 Blog Home
Blog HomeMeet LAVIS: A One-stop Library for Language-Vision AI Research and Applications
TL;DR: LAVIS (short for LAnguage-VISion) is an open-source deep learning library for language-vision research and applications, offering comprehensive support for a wide range of tasks, datasets, and state-of-the-art models. Featuring a unified interface and modular design, it’s easy to use off-the-shelf and to extend with new capabilities. With its powerful features and integrated framework, LAVIS helps make AI language-vision capabilities accessible to a wide audience of researchers and practitioners.
Background and Motivation
Multimodal content — in particular, language-vision data including text, images, and videos — is ubiquitous in real-world applications such as content recommendation, e-commerce, and entertainment. Each piece of language-vision data contains both textual and visual information — two modes, hence multimodal — which enables some specific language-vision applications to be developed, including generating textual descriptions for images, searching images using language queries, and classifying multimodal content such as product items described by text and images.
Recently, tremendous progress has been made in developing powerful language-vision models, especially language-vision foundation models. These are deep learning models pre-trained on large-scale image-text and video-text pairs (mostly collected from the internet), which can be flexibly transferred to a wide range of downstream tasks and applications, achieving good performance with a minimum amount of finetuning.
Limitations of Existing Libraries
While language-vision foundation models have achieved impressive results, they do have some limitations. For example, due to the diversity and complexity of language-vision tasks, training and evaluating these models are not straightforward. The experiment pipeline is a burdensome procedure that involves manual downloading of pre-trained models and task-specific datasets, careful coding to perform model training and evaluation, and miscellaneous tasks such as checkpointing and logging. It is demanding for incoming researchers and practitioners to carry out each step flawlessly. The main reason for such obstacles is the inconsistent interfaces across models, datasets, and task evaluations, as well as the non-trivial effort to prepare the required experiment setup.
Another limitation: most existing language-vision libraries support limited tasks, datasets, and/or obsolete models. For example, MMF (a MultiModal Framework for multimodal AI models) supports mostly task-specific finetuning models with inferior performance; X-modaler (a codebase for cross-modal analytics — image captioning, video captioning, and vision-language pre-training) supports much fewer tasks and datasets, with limited support for foundation models. Others’ ongoing efforts, including TorchMultimodal and UniLM, are largely under development with limited capabilities available.
In addition, the design of these libraries does not facilitate easy access to datasets and models for off-the-shelf use. This creates extra barriers for users who want to take advantage of modeling capabilities and resources.
Finally, most of these libraries do not provide fine-tuned model checkpoints or extensive benchmarking results. This results in additional effort to replicate model performance.

LAVIS: A Comprehensive Language-Vision Library for All
To make emerging language-vision intelligence and capabilities accessible to a wider audience, promote their practical adoption, and reduce repetitive efforts in future development, we built LAVIS (short for LAnguage-VISion), an open-source library which provides a unified interface for:
- training and evaluating state-of-the-art language-vision models on a rich family of tasks and datasets
- off-the-shelf inference on customized language-vision data
- easy extension with new models, tasks, and datasets.
The goals of LAVIS include:
- serving as a one-stop library for language-vision researchers and practitioners to leverage recent developments in the language-vision field
- welcoming newcomers to the field to join in with their ideas and help grow the community
- fostering collective efforts to amplify both research and practical impacts of the developed technology.
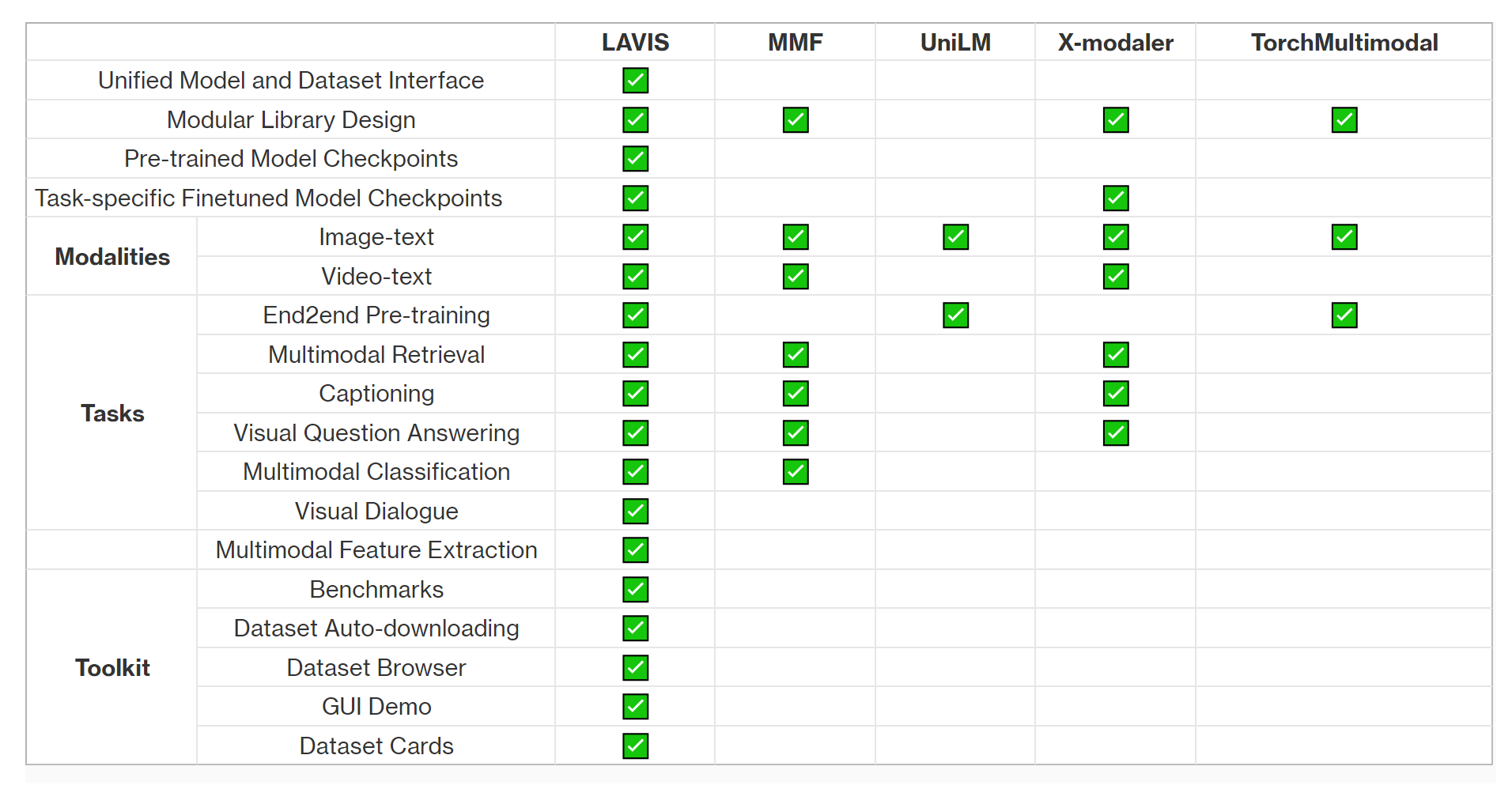
As Table 1 shows, LAVIS is the most comprehensive language-vision library available today, and we are working to continually improve it. Coming soon: stronger language-vision models, and new capabilities such as text-to-image generation.
Table 1: A head-to-head comparison of LAVIS and existing language-vision libraries/codebases. None of the others match LAVIS’s breadth of features and application areas. Note: language-vision models in UniLM and TorchMultimodal (alpha release) are under development, so the table only includes their supported features by the publication time of this blog post.
Deep Dive
Now let’s explore the main features of LAVIS in greater detail.
Comprehensive support of image-text/video-text tasks and datasets
LAVIS supports a growing list of more than 10 common language-vision tasks, across over 20 public datasets. These tasks and datasets provide a comprehensive and unified benchmark for evaluating language-vision models. In particular, we prioritize tasks that are standard and widely adopted for evaluation, with publicly available datasets. These include:
- multimodal retrieval tasks: given a query in one modality, search for targets in the other modality, such as image ↔ text retrieval, or video ↔ text retrieval
- multimodal question answering: answer questions regarding an image or video; for example, visual question answering (VQA), video question answering (VideoQA)
- image captioning: generate language descriptions for images
- multimodal classification: assign class labels to multimodal or unimodal inputs; for example, image classification, image-text classification
- multimodal dialogue: make conversations that involve multimodal content.
State-of-the-art and reproducible language-vision models
The LAVIS library enables access to over 30 pre-trained and task-specific finetuned model checkpoints of four popular foundation models: ALBEF, BLIP, CLIP, and ALPRO. These models achieve competitive performance across multiple tasks evaluated using common metrics. We also provide training, evaluation scripts, and configurations to facilitate reproducible language-vision research and adoption.
- ALBEF is an image-text model. It employs a ViT (Vision Transformer) as the image encoder, early BERT layers as the text encoder, and repurposes late BERT layers as the multimodal encoder by adding cross-attentions. It proposes the novel image-text contrastive (ITC) loss to align unimodal features before fusing them using the multimodal encoder. It is also one of the first models requiring no region information while demonstrating strong multimodal understanding capability.
- BLIP primarily tackles image-text tasks, while also showing strong zero-shot transfer capabilities to video-text tasks. It employs a ViT as the image encoder and a BERT as the text encoder. To facilitate multimodal understanding and generation, BLIP proposes a mixture of encoder-decoder (MED), which repurposes BERT into multimodal encoder and decoder with careful weight sharing. BLIP proposes dataset bootstrapping to improve the quality of text in the pre-training corpus by removing noisy ones and generating new diverse ones. In addition to the improved understanding capability compared to ALBEF, BLIP highlights its strong text generation ability, producing accurate and descriptive image captions. When adapted to video-text tasks, it operates on sampled frames while concatenating their features to represent the video.
- CLIP is a family of powerful image-text models. Different from ALBEF and BLIP, CLIP models adopt two unimodal encoders to obtain image and text representations. CLIP maximizes the similarity between positive image-text pairs, and was trained on 400M image-text pairs, rendering strong and robust unimodal representations.
- ALPRO is a video-text model, tackling video-text retrieval and video question answering tasks. It uses TimeSformer to extract video features, and BERT to extract text features. Similar to ALBEF, ALPRO uses contrastive loss to align unimodal features, yet it opts to use self-attention to model multimodal interaction. This architecture choice enables an additional visual-grounded pre-training task — prompt entity modeling (PEM) — to align fine-grained video-text information. ALPRO is strong in extracting regional video features and remains competitive for video understanding tasks across various datasets.
Table 2: Supported tasks, models, and datasets in LAVIS.
| Tasks | Models | Datasets | |
| Image-text Pre-training | ALBEF, BLIP | COCO, Visual Genome, SBU Caption, Conceptual Captions (3M, 12M), LAION | |
| Image-text Retrieval | ALBEF, BLIP. CLIP | COCO, Flickr30k | |
| Visual Quesiton Answering | ALBEF, BLIP | VQAv2, OKVQA, A-OKVQA | |
| Image Captioning | BLIP | COCO Caption, NoCaps | |
| Image Classification | CLIP | ImageNet | |
| Natural Language Visual Reasoning (NLVR2) | ALBEF, BLIP | NLVR2 | |
| Visual Entailment | ALBEF | SNLI-VE | |
| Visual Dialogue | BLIP | VisDial | |
| Video-to-text Retrieval | ALPRO, BLIP | MSRVTT, DiDeMo | |
| Video Question Answering | ALPRO, BLIP | MSRVTT-QA, MSVD-QA | |
| Video Dialogue | BLIP | AVSD | |
Modular and extensible design
The figure below shows the overall architecture of LAVIS. Our key design principle is to provide a simple and unified library to easily (i) train and evaluate the model; (ii) access supported models and datasets; (iii) extend with new models, tasks and datasets.
Key components in the library are organized using a modular design. This allows off-the-shelf access to individual components, swift development, and easy integration of new or external components. The modular design also eases model inferences, such as multimodal feature extraction.

Resourceful and useful toolkit
In addition to the core library functionalities, we also provide useful resources to further reduce learning barriers for language-vision research. These include automatic dataset downloading tools to help prepare the supported datasets, a GUI dataset browser to help preview downloaded datasets, and dataset cards documenting sources, supported tasks, common metrics, and leaderboards.
Pre-trained and finetuned model checkpoints. We include pre-trained and finetuned model checkpoints in the library. This promotes easy replication of our experimental results and repurposing of pre-trained models for other applications. Model checkpoints are downloaded automatically upon loading models.
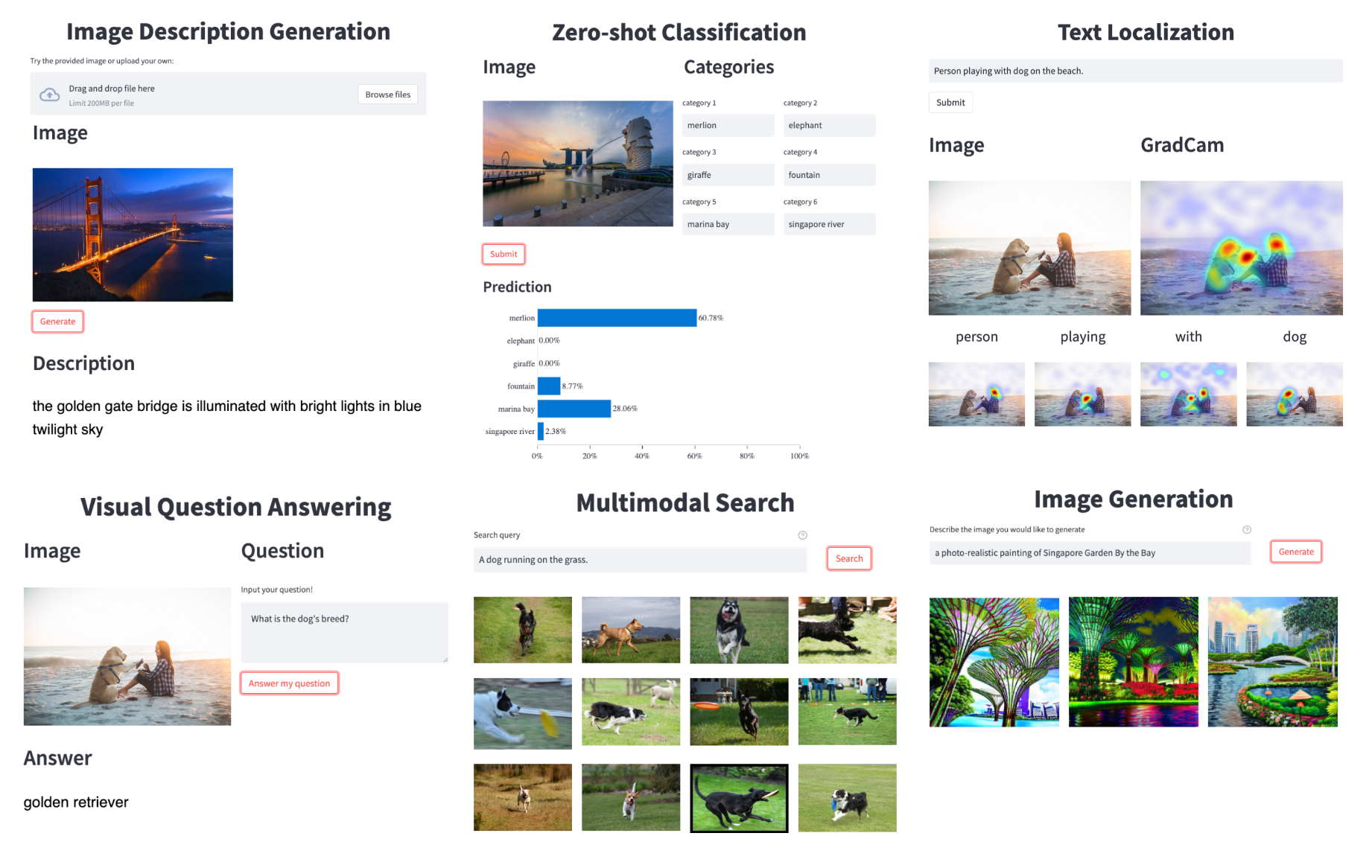
Web Demo: As shown in the Figure below, we developed a GUI-based web demo with a user-friendly interface to explore various multimodal capabilities. Currently the demo supports the following functionalities:
- Image captioning: produces a caption in natural language to describe an input image
- Visual question answering: answer natural language questions regarding the input image
- Multimodal search: search images in a gallery given a text query
- Text visualization: given an input image and a text caption, produces GradCam for each text token on the image
- Zero-shot multimodal classification: classify an input images into a set of input labels in text
- Easily extend the demo with new functionalities, such as text-to-image generation, thanks to LAVIS’s modular design.
Automatic dataset downloading and browsing: preparing language-vision datasets for pre-training and finetuning incurs much duplicating effort. To address this, LAVIS provides tools to automatically download and organize the public datasets, so that users can get easier and quicker access to common datasets. In addition, we also developed a GUI dataset browser, as shown in the Figure below, that helps users to rapidly gain intuitions about the data they use.

Societal Benefits and Responsible Use
We feel confident that the overwhelming impact of LAVIS will be positive.
- LAVIS can provide useful capabilities for many real-world multimodal applications.
- It features easy, unified, and centralized access to powerful language-vision models, facilitating effective multimodal analysis and reproducible research and development.
- We encourage researchers, data scientists, and ML practitioners to adopt LAVIS in real-world applications for positive social impacts, such as efficient and environment-friendly large-scale multimodal analysis.
However, it is possible that misuse of LAVIS may result in unwanted impacts.
- We encourage users to read detailed discussions and guidelines for building responsible AI.
- In particular, LAVIS should not be used to develop multimodal models that may expose unethical capabilities.
- In practice, we strongly recommend that users review the pre-trained models in LAVIS before practical adoption.
- Finally, note that models in LAVIS provide no warrant on their multimodal abilities; incorrect or biased predictions may be expected. We plan to further improve the library in the future, in order to avoid or minimize the occurrence of such problematic predictions.
The Bottom Line
- LAVIS is a comprehensive and extensible language-vision library that supports common tasks, datasets, and state-of-the-art models.
- LAVIS aims to provide data scientists, machine learning engineers, and researchers with a one-stop solution to analyze, debug, and explain their multimodal data.
- We continue to actively develop and improve LAVIS. In future releases, our priorities are to include more language-vision models, tasks, and datasets in the library. We also plan to add more parallelism support for scalable training and inference.
- We welcome and encourage any contributions from the open-source community.
Explore More
- Learn more details about LAVIS in our technical report: https://arxiv.org/abs/2209.09019
- Code: https://github.com/salesforce/LAVIS
- Demo: Offline GUI available, web demo is coming soon
- Contact: Dongxu Li at li.d@salesforce.com
- Follow us on Twitter: @SalesforceResearch @Salesforce
- Read our other blog posts: https://blog.salesforceairesearch.com
- Visit our main website to learn more about all of the exciting research projects Salesforce AI Research is working on: https://www.salesforceairesearch.com.
Related Resources
Blog posts:
- ALBEF: https://blog.salesforceairesearch.com/align-before-fuse/
- BLIP: https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/
- ALPRO: https://blog.salesforceairesearch.com/alpro/
Research papers:
- ALBEF: https://arxiv.org/abs/2107.07651
- BLIP: https://arxiv.org/abs/2201.12086
- ALPRO: https://arxiv.org/pdf/2112.09583.pdf
About the Authors
Dongxu Li is a Research Scientist at Salesforce Research. His research focuses on multimodal understanding and its applications.
Junnan Li is a Senior Research Manager at Salesforce Research. His current research focuses on vision and language AI. His ultimate research goal is to build generic AI models that can self-learn, without human supervision.
Steven C.H. Hoi is Managing Director of Salesforce Research Asia and oversees Salesforce's AI research and development activities in APAC. His research interests include machine learning and a broad range of AI applications.
Donald Rose is a Technical Writer at Salesforce Research. Specializing in content creation and editing, he works on multiple projects including blog posts, video scripts, news articles, media/PR material, writing workshops, and more. His passions include helping researchers transform their work into publications geared towards a wider audience, and writing think pieces about AI.
Glossary
Foundation models: Deep learning models pre-trained on very large amounts of data, which can perform well when transferred to a wide range of different tasks with minimum amounts of finetuning.
ViT: Vision Transformer. A visual model (based on the transformer architecture, which has proven popular for text-based tasks). A ViT model represents an input image as a sequence of fixed-size, non-overlapping image patches, analogous to the word embeddings used when applying transformers to text.