 Blog Home
Blog HomeALPRO: Understanding Video and Language by Aligning Visual Regions and Text Entities
TL;DR: We propose ALPRO, a new video-and-language representation learning framework which achieves state-of-the-art performance on video-text retrieval and video question answering by learning fine-grained alignment between video regions and textual entities via entity prompts.
For more background (a review of key concepts used in this post), please see the Appendix.
Motivation: The Inspo for ALPRO (or, What Problem Are We Trying to Solve?)
Think about how dynamic and rich real-world human interaction is. From the football commentary you enjoyed with friends over beers, to some puzzling Jeopardy questions about The Matrix, to the untold recipes presented on the Hell’s Kitchen TV show, there appears to be no doubt that we all interact verbally within a dynamic world, where video and language play vital interconnected roles on an ongoing basis.
In other words, in the Digital Age, video and language content have become ubiquitous — all around us, constantly, 24/7. And humans, for the most part, seem to have no problem processing this fire hose of video and text content.
But what about Artificial Intelligence (AI)?
More specifically: given this fundamental ubiquitous-video-and-language feature of the real world, a fundamental scientific question arises: how can we craft AI systems that jointly comprehend video content and human language?
Now you may be wondering: why is it important to work on both video and language at the same time? In other words, why did we decide that it was important to build an AI model to reason about video and language together?
We felt it was important to build such an AI model because many practical applications require the model to understand both modalities simultaneously. One example is content-based video search, which enables searching of a large volume of online videos, even without textual metadata. Another application is video categorization and recommendation, where the model can look at both video content and textual descriptions to label videos. This will be helpful for customized video search and recommendation.
Vision-Language Pre-training (VLP) Techniques
To tackle this AI challenge, vision-language or video-and-language pre-training (VLP) techniques have recently emerged as an effective approach.
Using VLP methods, one first pre-trains neural networks on a large number of video-text pairs from the web. Although some of this web data may be noisy, it turns out that neural networks can still learn useful representations for downstream applications.
Later, the parameters of the neural networks, obtained after pre-training, are used as the initialization for fine-tuning.
Limitations of Existing Work
Despite promising progress, current VLP models suffer from several limitations, such as:
Misalignment across modalities: First, the video and text embeddings are not well aligned. There are a couple of ways to model the cross-modal alignment in the existing literature. For example, some work maximizes the similarities of unimodal embeddings from the same video-text pair, for example, by taking dot-product between them. The other group of work directly feeds the unimodal embeddings to the cross-modal encoder, in the hope that the cross-modal encoder can capture the alignment relation automatically. However, as we know that these unimodal embeddings of videos and text are produced by separate encoder networks, their embeddings therefore reside in different feature spaces. As a result, both approaches are quite ineffective in modeling the cross-modal alignment.
Lack of fine-grained video information: Second, many visually-grounded pre-training tasks do not explicitly model fine-grained regional visual information. This information is, however, critical for understanding the video content. Some prior attempts (such as ActBERT) employ object detectors to generate pseudo-labels as supervision. Specifically, they first apply, e.g. Faster-RCNN, on their video frames to produce object labels. Then they use these labels to supervise the pre-training models. However, if you have ever played with object detectors, you may know that there are in fact not so many different object categories on these annotated detection datasets. For example, the MSCOCO object detection dataset has less than a hundred different object classes. This easily limits the VLP model from learning the abundant varieties of objects and entity concepts. In short, VLP models suffer from imprecise detections and a restricted number of object categories.
Our Approach: ALPRO (ALign & PROmpt)
To address the limitations of existing work, we propose ALign and PROmpt (ALPRO), a new video-and-language representation learning (pre-training) framework.
ALPRO follows the “pre-training-then-finetuning” paradigm used in the VLP techniques mentioned earlier, but addresses the limitations of those methods. Our framework operates on sparsely-sampled video frames and achieves more effective cross-modal alignment, without explicit object detectors.
The ultimate goal of our new approach is to improve downstream task performance — for example, on the tasks of video-text retrieval and video question answering (video QA). An improved pre-training strategy, as proposed in ALPRO, gives better video-language representations, which in turn contribute to improved downstream task performance.
The resulting pre-trained model in ALPRO achieves state-of-the-art performance on two classic tasks, video-text retrieval and video QA, across four public datasets. Our approach outperforms prior work by a substantial margin, while being much more label-efficient than other competing methods.
Deep Dive: How ALPRO Works
Let’s examine the techniques behind the ALPRO model in greater detail.
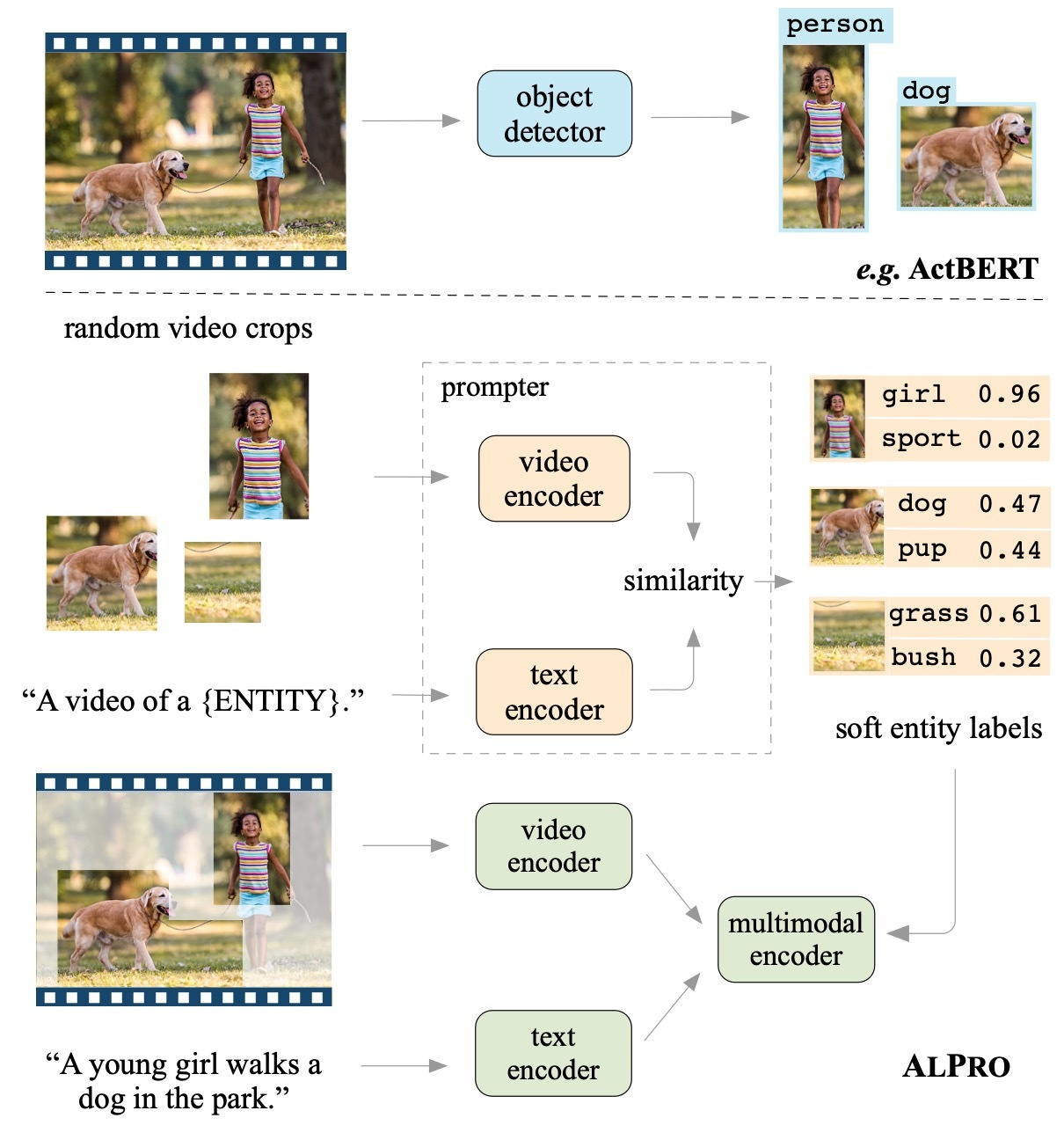
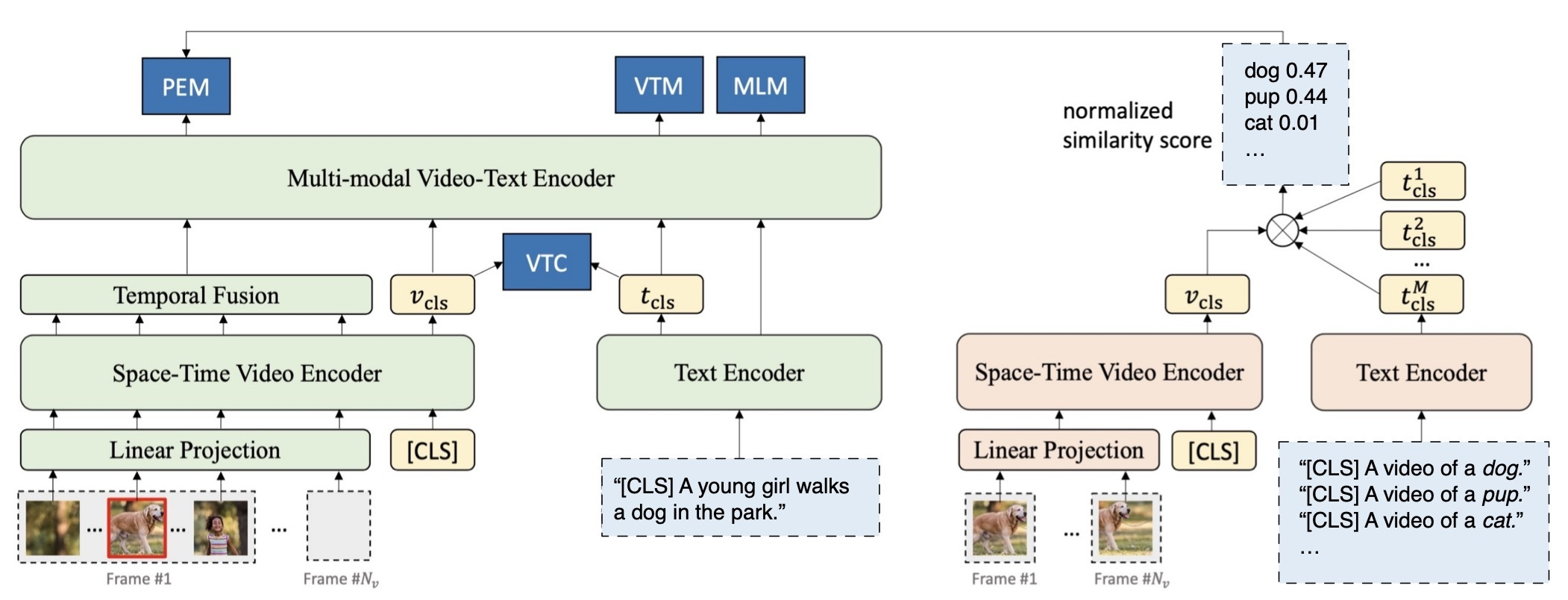
The novel ALPRO model (see figure above) consists of two main modules, a vision-language pre-training model and a prompter. The prompter serves to generate soft entity labels to supervise the pre-training of the video-language model. Both modules contain their own video encoder (TimeSformer) and text encoder (first 6-layers of BERT) to extract features for video and text inputs, respectively. The pre-training model has an additional multimodal encoder (last 6 layers of BERT) to further capture the interaction between the two modalities.
Now let’s take a closer look at two key pre-training tasks performed by ALPRO:
- Pre-training Task 1: Contrastive Video-Text Object to Cross-modal Alignment
- We first present a video-text contrastive (VTC) loss to align features from the unimodal encoders before sending them into the multimodal encoder. We achieve this by encouraging videos and text from positive pairs to have more similar embeddings than those from the negative pairs. In this way, we ensure that the cross-encoder receives better aligned unimodal embeddings before modeling their interactions.
- Pre-training Task 2: Prompting Entity Modeling (PEM) to Capture Fine-grained Video Information
- PEM is a new visually-grounded pre-training task that improves the models’ capabilities in capturing local regional information. Specifically, PEM relies on a prompter module that generates soft pseudo-labels of up to a thousand different entity categories for random video crops. The pre-training model is then asked to predict the entity categories given the pseudo-label as the target.
- In order to generate the pseudo-labels, the prompter computes the similarities between the selected video crops with a pre-determined list of so-called “entity prompts”. An example of an entity prompt is the short text, “A video of {ENTITY}”, where ENTITY is a noun that appears often in the pre-training corpus. In this way, we easily scale up the number of entity categories by simply adding more entity prompts.
Examples of generated pseudo-labels for the selected video regions are shown in the figure below.


As you can see, the categories contained in these pseudo-labels capture quite a diverse range of different visual concepts. Most of these concepts are not observed in the detection datasets. What’s even cooler: to generate these pseudo-labels, ALPRO does not need any human annotations on either object bounding boxes or categories. All of these are learned in a self-supervised manner.
Comparative Analysis: ALPRO is Effective and Label-efficient
ALPRO achieves state-of-the-art performance on four common video-language downstream datasets for the video-text retrieval and video QA tasks, as shown in the tables below.
On the widely-used video-text retrieval dataset MSRVTT, ALPRO surpasses previous best retrieval model FiT by 5 absolute lift in Recall@1 under the zero-shot setup.
On video QA, ALPRO achieves comparable results with VQA-T that utilizes QA-specific domain pre-training pairs.
Note that ALPRO achieves its superior performance using only about 5-10% of the pre-training data used by previous approaches, meaning that ALPRO is much more label-efficient. For more details, please check out our paper [1].
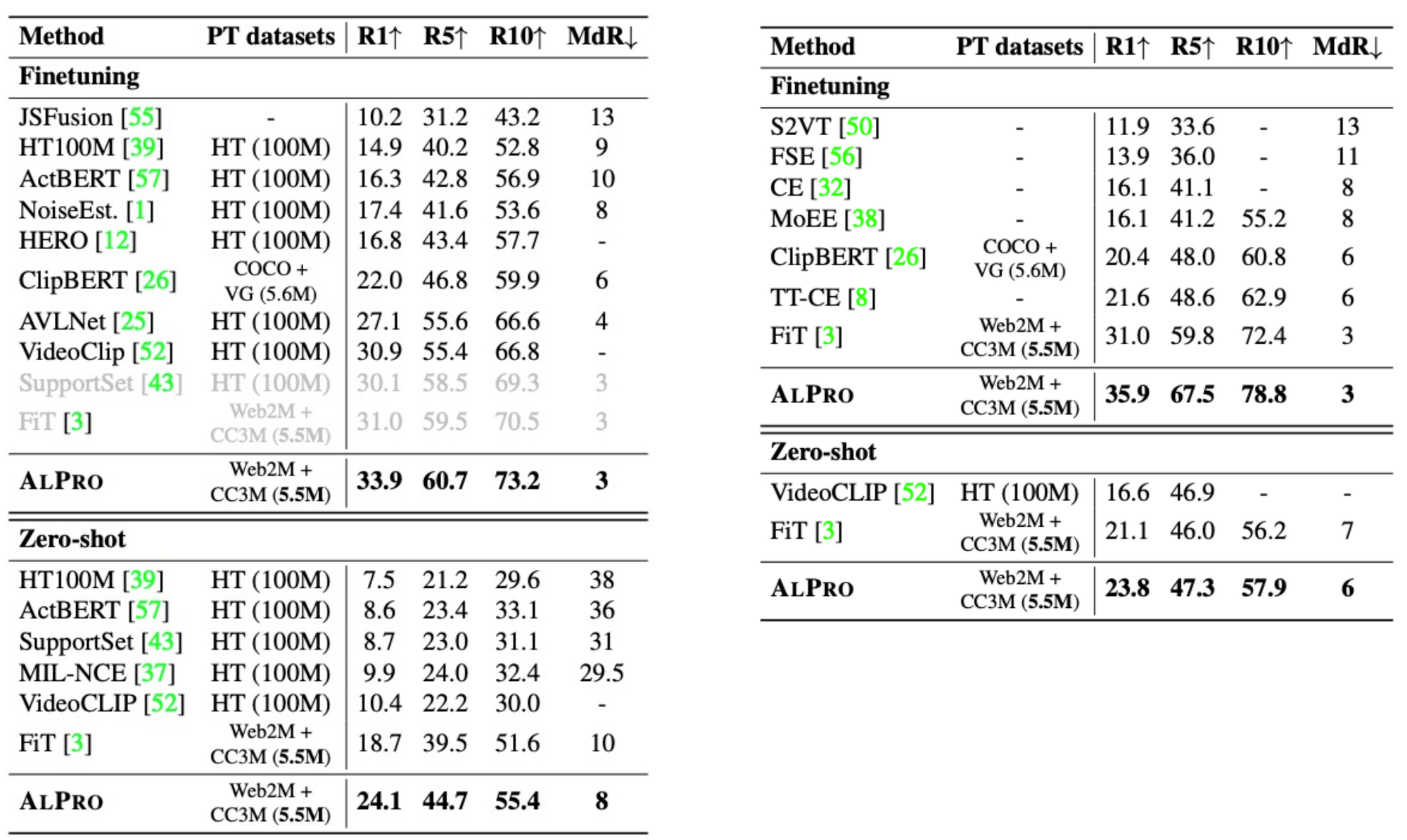
Results on video-text retrieval datasets MSRVTT (left) and DiDeMo (right).
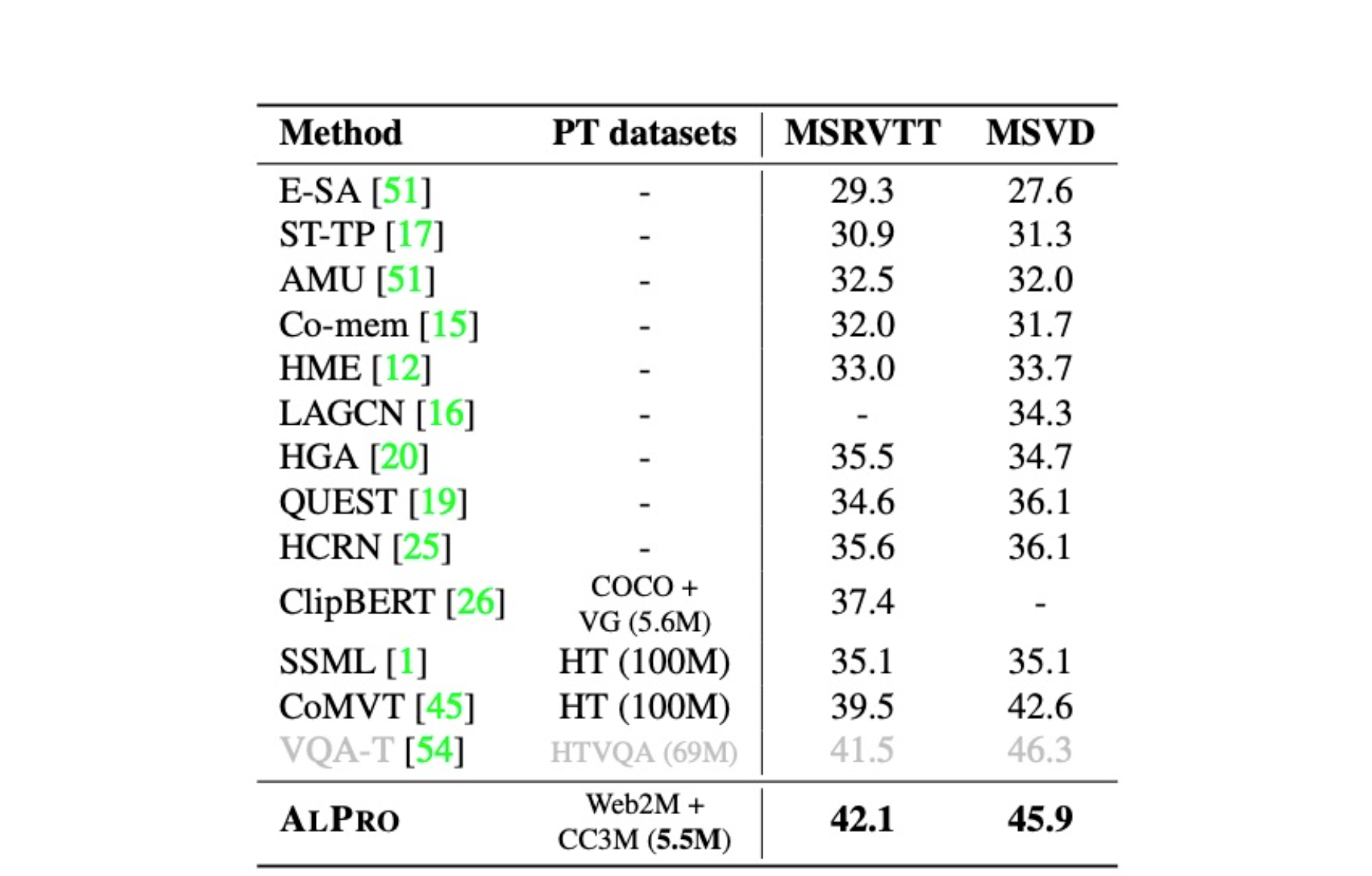
Results on video QA datasets.
The Big Picture: Ethical Considerations
- Inappropriate content exposure: The pre-training video-text corpus is collected from the web. This content is usually generated by users without proper controls. Therefore, it is possible that ALPRO is exposed to inappropriate video content or harmful text. As such, we suggest more model analysis before deploying ALPRO in production settings. It is also desirable to further pre-train and/or fine-tune ALPRO on production-specific multimodal data to alleviate the issue.
- Data Bias: Because the pre-training video-text corpus is collected from the web, it is also exposed to data bias. This bias could be present either in the object detector, text or video encoders. Similar to the issue above, additional analysis and/or training should be conducted before the system is deployed.
- Environmental cost: Training ALPRO requires a moderate amount of computational resources, with our careful optimization on model architecture and data processing pipeline. The overall training cost is around several hundred A100 GPU hours. In order to promote environmentally-friendly AI systems, we have published our pre-trained models to avoid repetitive pre-training efforts for end-users.
- Privacy concerns: Pre-trained video-language data may contain identity-sensitive information, such as biometrics. To address this issue, alternative pre-training sources without human identities may be considered (see, for instance, the work on self-supervised pre-training without humans [2]). Also, anonymity strategies may be adopted to pre-process the pre-training corpus to avoid identity leakage.
The Bottom Line
- We propose ALPRO (ALign and PROmpt), a new video-and-language pre-training framework that provides a generic yet effective solution to video-text representation learning. ALPRO follows the “pre-training-then-finetuning” paradigm used in other VLP techniques, but addresses the limitations of those methods.
- How it works: First, we introduce a video-text contrastive (VTC) loss to align unimodal video-text features at the instance level, which eases the modeling of cross-modal interactions. Then, we propose a novel visually-grounded pre-training task, prompting entity modeling (PEM), which learns fine-grained alignment between visual region and text entity via an entity prompter module in a self-supervised way. Finally, we pre-train the video-and-language transformer models on large web-sourced video-text pairs using the proposed VTC and PEM losses as well as two standard losses — masked language modeling (MLM) and video-text matching (VTM).
- Results: ALPRO achieves state-of-the-art performance on two classic tasks, video-text retrieval and video QA, across four public datasets, while being much more label efficient than other competing methods.
- We expect the idea of cross-modal alignment and fine-grained modeling in ALPRO to play vital roles in a wider range of applications, and eventually deliver great value for our customers at Salesforce.
- We felt it was important to build an AI model to reason about video and language together because many practical applications require the model to understand both modalities simultaneously. One example is content-based video search, which enables searching of a large volume of online videos, even without textual metadata. Another application is video categorization and recommendation, where the model can look at both video content and textual descriptions to label videos. This will be helpful for customized video search and recommendation.
Explore More
Salesforce AI Research invites you to dive deeper into the concepts discussed in this blog post (links below). Connect with us on social media and our website to get regular updates on this and other research projects.
- Research Paper: Learn more about ALPRO by checking out our paper, which describes the research in greater detail: https://arxiv.org/pdf/2112.09583.pdf
- Contact: li.d@salesforce.com or junnan.li@salesforce.com
- Code: https://github.com/salesforce/ALPRO
Related Resources
[1] Align and Prompt: Video-and-Language Pre-training with Entity Prompts. Dongxu Li , Junnan Li, Hongdong Li, Juan Carlos Niebles, Steven C.H. Hoi.
[2] PASS: An ImageNet replacement for self-supervised pretraining without humans. Yuki M. Asano, Christian Rupprecht, Andrew Zisserman, Andrea Vedaldi
About the Authors
Dongxu Li is a Research Scientist at Salesforce Research. His research focuses on multimodal understanding and its applications.
Junnan Li is a Senior Research Manager at Salesforce Research. His current research focuses on vision and language AI. His ultimate research goal is to build generic AI models that can self-learn without human supervision.
Steven C.H. Hoi is Managing Director of Salesforce Research Asia and oversees Salesforce's AI research and development activities in APAC. His research interests include machine learning and a broad range of AI applications.
Donald Rose is a Technical Writer at Salesforce AI Research. Specializing in content creation and editing, Dr. Rose works on multiple projects, including blog posts, video scripts, news articles, media/PR material, social media, writing workshops, and more. He also helps researchers transform their work into publications geared towards a wider audience.
Appendix: Key Concepts, Terms, Definitions
- Pre-training task: a task where we train a neural network with web data to help it obtain parameters that can be used in downstream applications. For example, the masked language modeling (MLM) task in BERT is a pre-training task on Wikipedia data.
- Downstream tasks: the tasks that you actually want to solve. For example, video question answering or video-text retrieval.
- Video-text retrieval: models try to find the most relevant video (from a gallery) for each text query.
- Video question answering (video QA): models answer natural language questions regarding videos.
- Embeddings / Features: used interchangeably in this post to refer to a real-valued vector that represents the data.
- Unimodal encoder: a neural network module that takes as input a single modality of data (such as video or text), and produces their embeddings as output. For instance, the BERT encoder is a unimodal encoder for text inputs while TimeSformer is a unimodal encoder for video inputs.
- Cross-modal encoder: a neural network module that takes as input the embeddings of two modalities (for example, video and text produced by individual unimodal encoders), and concentrates on modeling the interaction between the two modalities. Therefore, architecture-wise, cross-modal encoders usually operate after unimodal encoders.
- Cross-modal alignment: if a sentence describes the event happening in the video, an informed VLP model is supposed to easily tell from their representations that they are semantically close, or semantically aligned. For example, the embedding of a football match video should be better aligned to its accompanying commentary, as opposed to monologues in a TV show.
- Coarse-grained vs. fine-grained: coarse-grained information usually means you consider the input data holistically; for example, the whole video or sentence in full. In contrast, fine-grained information can usually be understood as parts of texts or videos, such as tokens or frame regions.