 Blog Home
Blog HomeAlign before Fuse (ALBEF): Advancing Vision-language Understanding with Contrastive Learning
TL; DR: We propose a new vision-language representation learning framework which achieves state-of-the-art performance by first aligning the unimodal representations before fusing them.
Vision and language are two of the most fundamental channels for humans to perceive the world. It has been a long-standing goal in AI to build intelligent machines that can jointly understand vision data (images) and language data (texts). Vision-and-language pre-training (VLP) has emerged as an effective approach to address this problem. However, existing methods have three major limitations.
Limitation 1: Methods represented by CLIP [2] and ALIGN [3] learn unimodal image encoder and text encoder, and achieve impressive performance on representation learning tasks. However, they lack the ability to model complex interactions between image and text, hence they are not good at tasks that require fine-grained image-text understanding.
Limitation 2: Methods represented by UNITER [4] employ a multimodal encoder to jointly model image and text. However, the input to the multimodal transformer contains unaligned region-based image features and word token embeddings. Since the visual features and textual features reside in their own spaces, it is challenging for the multimodal encoder to learn to model their interactions. Furthermore, most methods use a pre-trained object detector for image feature extraction, which is both annotation-expensive and computation-expensive.
Limitation 3: The datasets used for pre-training mostly consist of noisy image-text pairs collected from the Web. The widely used pre-training objectives such as masked language modeling (MLM) are prone to overfitting to the noisy text which would hurt representation learning.
To address these limitations, we propose ALign BEfore Fuse (ALBEF), a new vision-language representation learning framework. ALBEF achieves state-of-the-art performance on multiple vision-language downstream tasks such as image-text retrieval, visual question answering (VQA), and natural language visual reasoning (NLVR). Next, we will explain how ALBEF works.
Aligning Unimodal Representations with Image-Text Contrastive Learning
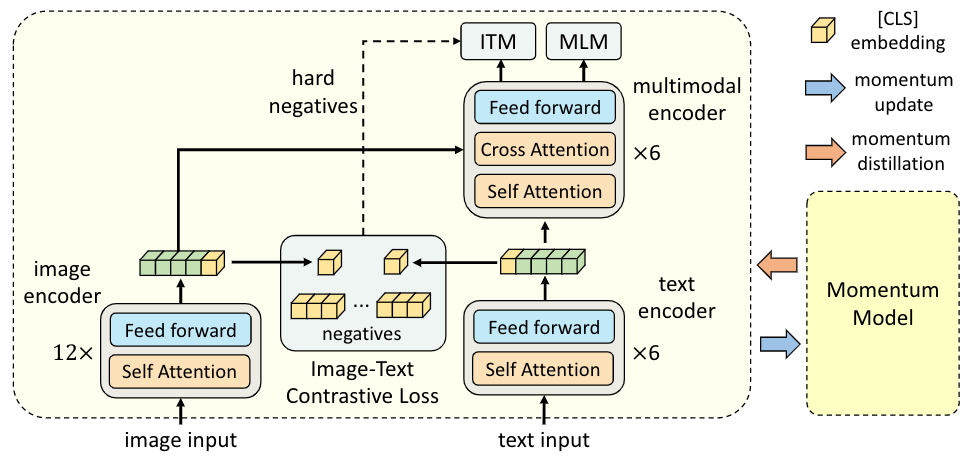
As illustrated in the figure above, ALBEF contains an image encoder (ViT-B/16), a text encoder (first 6 layers of BERT), and a multimodal encoder (last 6 layers of BERT with additional cross-attention layers). We pre-train ALBEF by jointly optimizing the following three objectives:
Objective 1: image-text contrastive learning applied to the unimodal image encoder and text encoder. It aligns the image features and the text features, and also trains the unimodal encoders to better understand the semantic meaning of images and texts.
Objective 2: image-text matching applied to the multimodal encoder, which predicts whether a pair of image and text is positive (matched) or negative (not matched). We propose contrastive hard negative mining which selects informative negatives with higher contrastive similarity.
Objective 3: masked language modeling applied to the multimodal encoder. We randomly mask out text tokens and trains the model to predict them using both the image and the masked text.
Momentum Distillation to Learn from Noisy Image-Text Pairs
The image-text pairs collected from the Web are often weakly-correlated: the text may contain words that are unrelated to the image, or the image may contain entities that are not described in the text. To learn from noisy data, we propose momentum distillation, where we use a momentum model to generate pseudo-targets for both image-text contrastive learning and masked language modeling. The following figure shows an example of the pseudo-positive texts for an image, which produces new concepts such as "young woman" and "tree". We also provide theoretical explanations from the perspective of mutual information maximization, showing that momentum distillation can be interpreted as generating views for each image-text pair.

Downstream Vision and Language Tasks
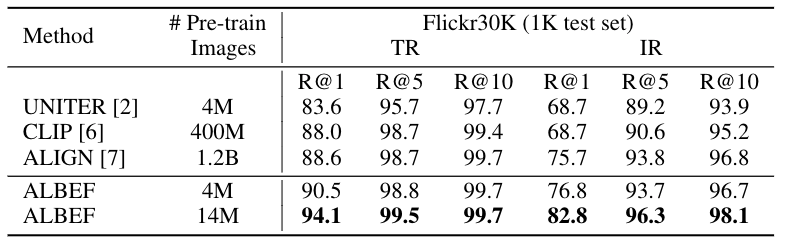
ALBEF achieves state-of-the-art performance on multiple downstream tasks, as shown in the following tables. On image-text retrieval, ALBEF outperforms methods that are pre-trained on orders of magnitude larger datasets (CLIP [2] and ALIGN [3]). On VQA, NLVR, and VE, ALBEF outperforms methods that use pre-trained object detectors, additional object tags, or adversarial data augmentations.

Visual Grounding
Surprisingly, we find that ALBEF implicitly learns accurate grounding of objects, attributes, and relationships, despite not being trained on any bounding box annotations. We use Grad-CAM to probe the cross-attention maps of the multimodal encoder, and achieves state-of-the-art results on the weakly-supervised visual grounding task. The following figures show some examples of the visualization.



Looking Forward
ALBEF is a simple, end-to-end, and powerful framework for vision-language representation learning. We have released our pre-trained model and code to spur more research in this important topic. If you are interested in learning more, please check out our paper [1]. Feel free to contact us at junnan.li@salesforce.com!
References
- Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, Steven Hoi. Align before Fuse: Vision and Language Representation Learning with Momentum Distillation. arXiv preprint arXiv: 2107.07651, 2021.
- Radford, A., J. W. Kim, C. Hallacy, et al. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
- Jia, C., Y. Yang, Y. Xia, et al. Scaling up visual and vision-language representation learning with noisy text supervision. arXiv preprint arXiv:2102.05918, 2021.
- Chen, Y., L. Li, L. Yu, et al. UNITER: universal image-text representation learning. In ECCV, 2020.