 Blog Home
Blog HomeLong Sequence Modeling with XGen: A 7B LLM Trained on 8K Input Sequence Length
TLDR
We trained a series of 7B LLMs named XGen-7B with standard dense attention on up to 8K sequence length for up to 1.5T tokens. We also fine tune the models on public-domain instructional data. The main take-aways are:
- On standard NLP benchmarks, XGen achieves comparable or better results when compared with state-of-the-art open-source LLMs (e.g. MPT, Falcon, LLaMA, Redpajama, OpenLLaMA) of similar model size.
- Our targeted evaluation on long sequence modeling benchmarks show benefits of our 8K-seq models over 2K- and 4K-seq models.
- XGen-7B archives equally strong results both in text (e.g., MMLU, QA) and code (HumanEval) tasks.
- Training cost of $150K on 1T tokens under Google Cloud pricing for TPU-v4.
Paper: https://arxiv.org/abs/2309.03450
Codebase: https://github.com/salesforce/xGen
Model Checkpoint: https://huggingface.co/Salesforce/xgen-7b-8k-base
Why XGen-7B with 8K Sequence Length
As LLMs become ubiquitous, their applications to long sequences have been a key focus, especially for applications like summarizing text (potentially interleaved with other data sources like tables and images), writing code, and predicting protein sequences, which require the model to effectively consider long distance structural dependencies. A large context allows a pre-trained LLM to look at customer data (e.g., documents the LLM did not use in training) and responds to useful information seeking queries.
Yet, most open-source LLMs (e.g., LLaMA, MPT, Falcon) have been trained with a maximum of 2K token sequence length, which is a key limitation in modeling long sequences. Inference time solutions such as ALiBi have yet to be evaluated for larger models (e.g. MPT-7b-StoryWriter-65k+). Recent work on model scaling has shown that for a given compute budget, the best performances are not necessarily achieved by the largest models, but by smaller models trained on more data (measured by number of tokens). A smaller model is also generally preferred for inference efficiency during serving including on-device serving. In light of this, we train a series of 7B LLMs named XGen with standard dense attention on up to 8K sequence length for up to 1.5T tokens. We also fine tune the XGen models on public-domain instructional data, creating their instruction-tuned counterparts (XGen-7B-inst).
Pre-training Data
We employ a two-stage training strategy, where each stage uses a different data mixture.
First stage (1.37T tokens)
Natural language data is a mixture of publicly available data. Code data is a mixture of the GitHub subset from the RedPajama dataset and the Apex code data we collected.
Second stage (110B tokens)
To better support code-generation tasks, in the second stage we mix more code data from Starcoder with the data from Stage 1.
We use OpenAI’s tiktoken to tokenize our data. We add additional tokens for consecutive whitespaces and tabs, as well as the special tokens described in the Starcoder paper.
Training Details
The XGen-7b models are trained with our in-house library JaxFormer, which facilitates efficient training of LLMs under both data and model parallelism optimized for TPU-v4 hardware. The training recipe and model architecture follow LLaMA, while we conduct two additional explorations. First, we investigate the occurrence of so-called “loss spikes” [PaLM, loss spikes] during training, that is, the loss suddenly explodes temporarily while the root cause for these spikes is unknown. Second, the XGen models support sequence lengths up to 8,192 tokens (rather than the common 2,048) for which we introduce stage-wise training.
Loss Spikes
As models are scaled to larger sizes, the training itself is increasingly sensitive to instabilities, which cause poor model performance, if not addressed carefully. In our exploration, we have gathered evidence for several factors, which individually contribute to unstable training. These preliminary findings include “sequential over parallel circuits”, “swish-GLU over GeLU”, “RMS-Norm over Layer-norm”. Specifically, widely used parallel circuits, which parallelize the computation of self-attention and feed-forward as adopted in [GPT-J, PaLM, CodeGen] may affect the stability of training.
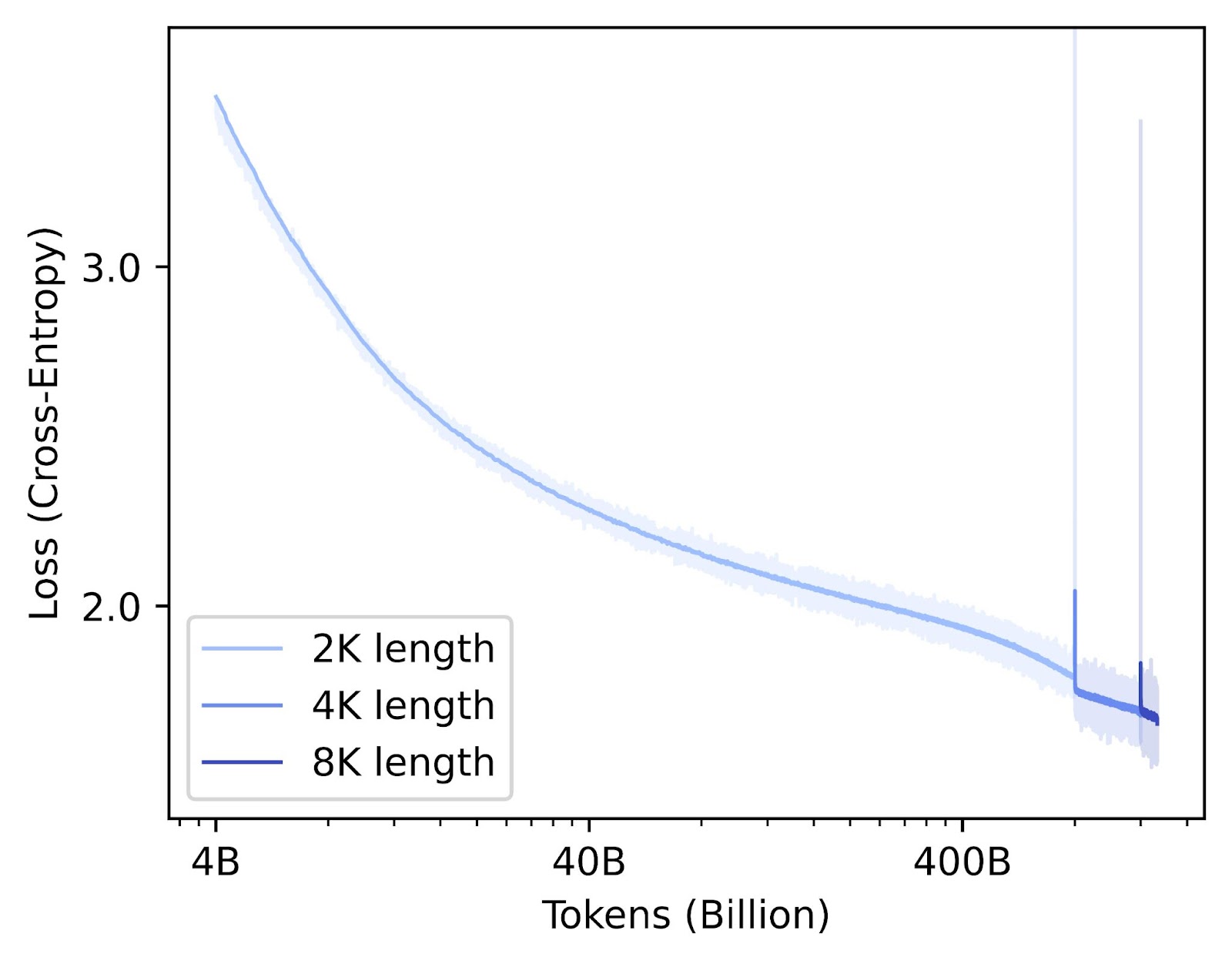
The figure above displays the loss in terms of cross-entropy over time following the well-known scaling laws. Remarkably, the training does not suffer from any instabilities or loss spikes. The two loss spikes depicted in the figure are expected when extending the sequence length, say from 2k to 4k tokens, since the model needs to adapt to such longer sequences.
Sequence Length
Training with longer sequences is computationally unproportionally costly as the complexity of self-attention is quadratic, that is, the training process is slow. To mitigate slow training, we introduce training in stages with increasing sequence length. First, 800B tokens with sequence length of 2k tokens are observed, then 400B tokens with 4k, finally, 300B tokens with 8k length.
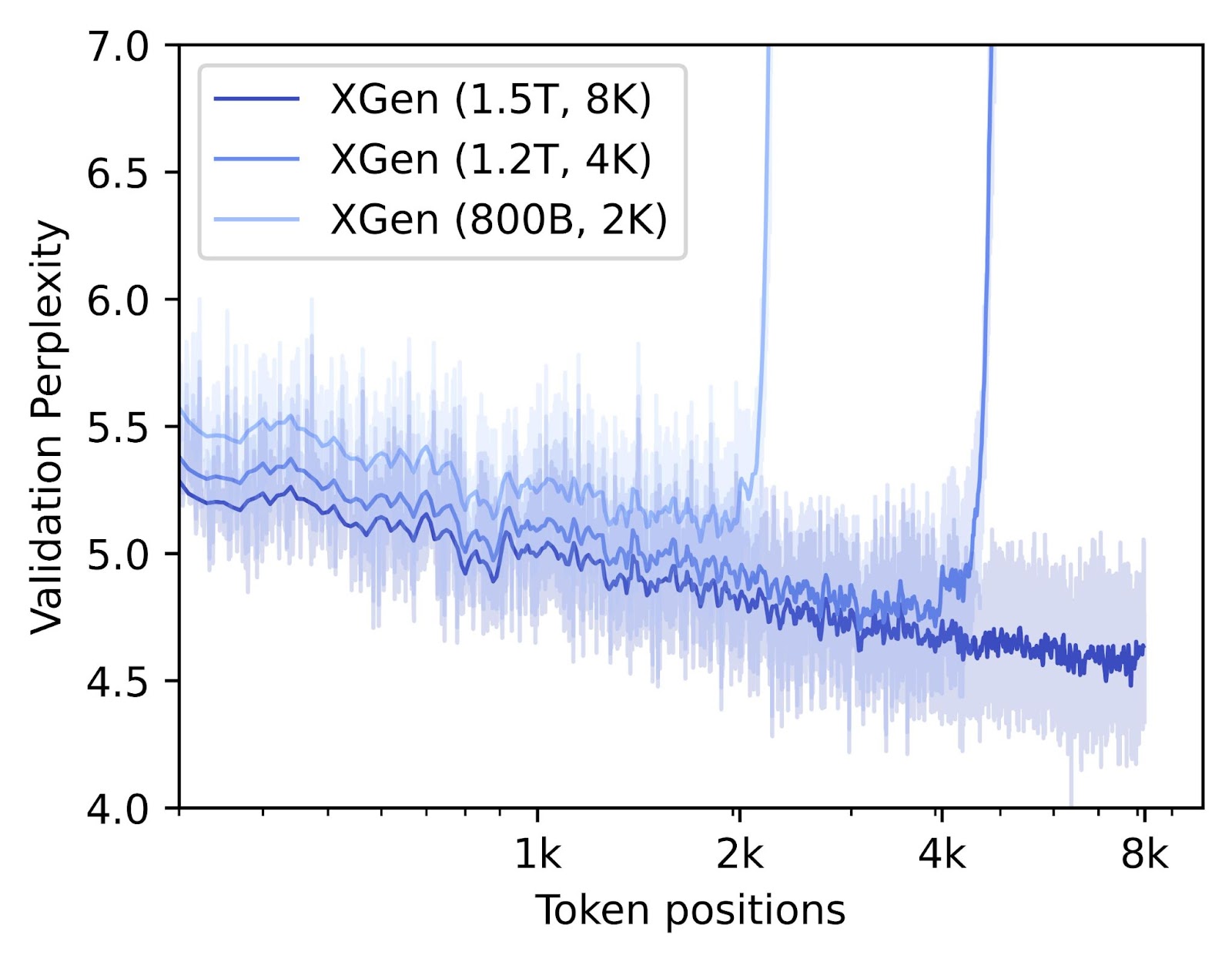
We verify the adaptation to longer sequences by computing the average perplexity at each token position on a held-out validation set containing documents of 8k sequence length or above. If the model successfully learns to utilize the full sequence, we would expect the perplexity to decrease over sequence length, as previous tokens carry information for the next to-be-predicted token. That is, for a long sentence, the more context in the form of previous words is provided, the easier it becomes to guess the next word. The figure above indeed shows that XGen at each stage successfully learns to utilize longer contexts, up to 8k sequence length.
Results on Standard Benchmarks
(i) MMLU
We first consider the Measuring Massive Multitask Language Understanding benchmark (see examples here), which is more recent than others due to which it is arguably less susceptible to data contamination as reported in recent studies (see page 32 of GPT-4 paper and a related discussion here), and has been used consistently as a held-out evaluation benchmark. Recently, however, inconsistencies in reporting MMLU scores have been reported, which resulted in wrong rankings in Hugginface’s Open LLM leaderboard; In fact, Huggingface later had to write a blog to clarify this. In our work, we follow the original MMLU standard, which is consistent with the published results (i.e., in LLaMA).
MMLU 5-shot In-context Learning Results: We first show results on the original (and recommended) 5-shot evaluation setting, where the LLM is provided with 5 demonstrations. XGen achieves the best results in most categories, also in weighted average.
MMLU 0-shot Results: On zero-shot MMLU, similarly we see good results although the difference with LLaMA is generally less here.
(ii) General Zero-shot Results
Next, we report general zero-shot results on general NLP tasks that involve common sense reasoning and QA.
(iii) Results on Code Generation
To evaluate XGen’s code generation capability from natural language instructions (docstrings), we evaluate it on the well-known HumanEval benchmark. We set the sampling temperature to 0.2, p to 0.95 (for top-p sampling), and num_samples_per_task (n) to 200. We report the standard zero-shot results with pass@1 metric.
Results on Long Sequence Generation Tasks
To further evaluate our XGen-7b 8k model in comparison to baselines which are limited to 2k inputs, we turn to long-form dialogue generation, text summarization and QA. All these tasks benefit from using processing and understanding a long context to generate a correct response. Note that for these tasks most of the base pre-trained models failed to generate a plausible response because of the task difficulty. We thus use instruction-tuned models.
Dialogue
To assess the long dialogue understanding and summarization capabilities, we report results on three dialogue summarization tasks: AMI meeting summarization, ForeverDreaming (FD), and TVMegaSite (TMS) screenplay summarization. The average source lengths of these datasets are approximately 5570, 6466, and 7653, respectively. We specifically evaluate samples that are less than 8K in length using various instruction-tuned models. Notably, when input truncation was not applied, both MPT-7b-inst and Alpaca-inst failed to perform well in this setting. Our model (XGen-7B-inst) achieved the highest ROUGE scores across all metrics.
Long-form QA
Next, we evaluate our XGen-7b-inst on a long-form QA task that we have designed in-house. We ask ChatGPT to generate questions from (a) long Wikipedia documents spanning four domains: Physics, Engineering, History, and Entertainment, and (b) summaries of these documents. Then we query the LLMs to generate answers for these questions. The answers are typically up to 256 tokens long. We use GPT-4 to evaluate the answer quality in terms of coherence (structure and organization) and relevance (relevance of generated answer to the question and the context document) on a scale of 0-3. From the results below, we see our model has higher scores in different aspects compared to the baselines considered.
Summarization
Here, we evaluate our model on two text summarization datasets included in the SCROLLS Benchmark, namely QMSum and GovReport. They cover two different domains -- meeting conversations and government reports. Additionally, QMSum data includes specific natural language queries which instruct the model about the key aspects of the source document that should be included in the summary. We see that our model XGen-7b outperforms other baselines on these tasks.
As we see encouraging results of our XGen-7b models on these long sequence tasks, we would like to note that since these models are not trained on the same instructional data, they are not strictly comparable.
Note on Potential Risks
Finally, despite our effort in addressing the risks of bias, toxicity and hallucinations both in pre-training and fine-tuning stages, like other LLMs, XGen-7b models are not free from such limitations. We hope our open-sourced codebase will help other researchers better understand these challenges and improve on these key limitations for making AI beneficial for everyone.