 Blog Home
Blog HomeAI Coding with CodeRL: Toward Mastering Program Synthesis with Deep Reinforcement Learning
TL;DR: CodeRL is a new framework for program synthesis through holistic integration of pretrained language models and deep reinforcement learning. By utilizing unit test feedback as part of model training and inference, and integrating with an improved CodeT5 model, CodeRL achieves state-of-the-art results on competition-level programming tasks.
The following GIF gives a brief, high-level overview of how CodeRL works. For more information (background, system details, an exploration of its societal impact, and more), please read the full blog post below.

Background: AI for Program Synthesis
Program synthesis is the task of building an executable program in a formal computer language (such as Java or Python) to solve a problem (for example, compute the area of a polygon). For a long time, solving problems through computer programming has been a test of human intelligence, and the machine learning community has considered this task a grand AI challenge.
Recent advances in deep learning, such as pretrained language models (LMs), have led to remarkable progress in program synthesis. In LMs, we can treat program synthesis as a sequence-to-sequence task, in which the input is the problem description in natural language and the output is a program expressed as a sequence of words (i.e., sequence of code).
Large LMs (such as Codex) that are pretrained on massive public datasets containing text and code are able to solve basic programming problems with impressive success rates.
Limitations of AI Systems for Program Synthesis
While they may be able to perform well on basic programming problems, existing AI program-synthesis models perform poorly when dealing with complex programming problems — such as the example below. (Highly difficult programming problems include those on major programming contest websites such as Codeforces.)

A typical example of a program synthesis task from the APPS Benchmark. Each task includes a problem specification in natural language, which often contains example input and output pairs. These example input and output pairs can be used to construct example unit tests (which check whether the code works). The expected output is a program that is checked for functional correctness against some unseen unit tests.
-
Existing AI-based approaches to program synthesis fall short for multiple reasons. Their main high-level limitations are:
- Generating code in a one-shot manner: Current AI code-generation approaches simply finetune existing large pretrained LMs on the code domain following conventional training objectives, and assume they can generate a perfect program in one shot — without revisions or iterative improvement. However, in reality, programs generated by existing state-of-the-art (SOTA) code generation models are far from perfect. For example, they often fail to execute, due to a compiler or runtime error, or they fail to pass unit tests (designed to determine whether the code works properly). In other words, existing frameworks often follow a standard supervised learning procedure to finetune pretrained LMs as a code generation model, using only natural language problem descriptions and ground-truth programs (correct target programs corresponding to the problem description) — but this training paradigm is not ideal in program synthesis to optimize models toward functionally correct programs.
- Not taking signals from the environment: The above training paradigm largely ignores important but potentially useful signals in the problem specification, which results in poor performance when solving complex unseen coding tasks. During inference, since example unit tests are often part of the problem description, they are potentially powerful to further improve output programs — for instance, through multiple rounds of regeneration and refinement (an iterative process of creating revised versions of previous output, each round producing an improved program that’s more functionally correct).
Solution: CodeRL Improves Pretrained LMs With Deep Reinforcement Learning
To address the limitations of existing AI code-generation systems, we propose CodeRL, a new general framework that holistically integrates pretrained LMs and deep reinforcement learning (RL) for program synthesis tasks. In this work, we aim to design and develop intelligent program-synthesis systems that are more capable of solving complex problems that existing approaches have difficulty with.
Here are CodeRL’s main innovations and accomplishments in a nutshell — what makes it unique and powerful:
- During training, we treat the code-generating LMs as an actor network, and introduce a critic network that is trained to predict the functional correctness of generated programs and provide dense feedback signals to the actor.
- During inference, we introduce a new generation procedure with a critic sampling strategy that allows a model to automatically regenerate programs based on feedback from example unit tests and critic scores.
- With an improved CodeT5 model, our method not only achieves new SOTA results on the challenging APPS benchmark, but also shows strong zero-shot transfer capability with new SOTA results on the simpler MBPP benchmark.
The GIF below provides a brief, high-level overview of how CodeRL works.

Deep Dive: CodeRL System Design
CodeT5 as the Foundation Model
For the model backbone, we extended the encoder-decoder architecture of CodeT5 with enhanced learning objectives, larger model sizes, and better pretraining data.
Finetune LMs with Deep RL
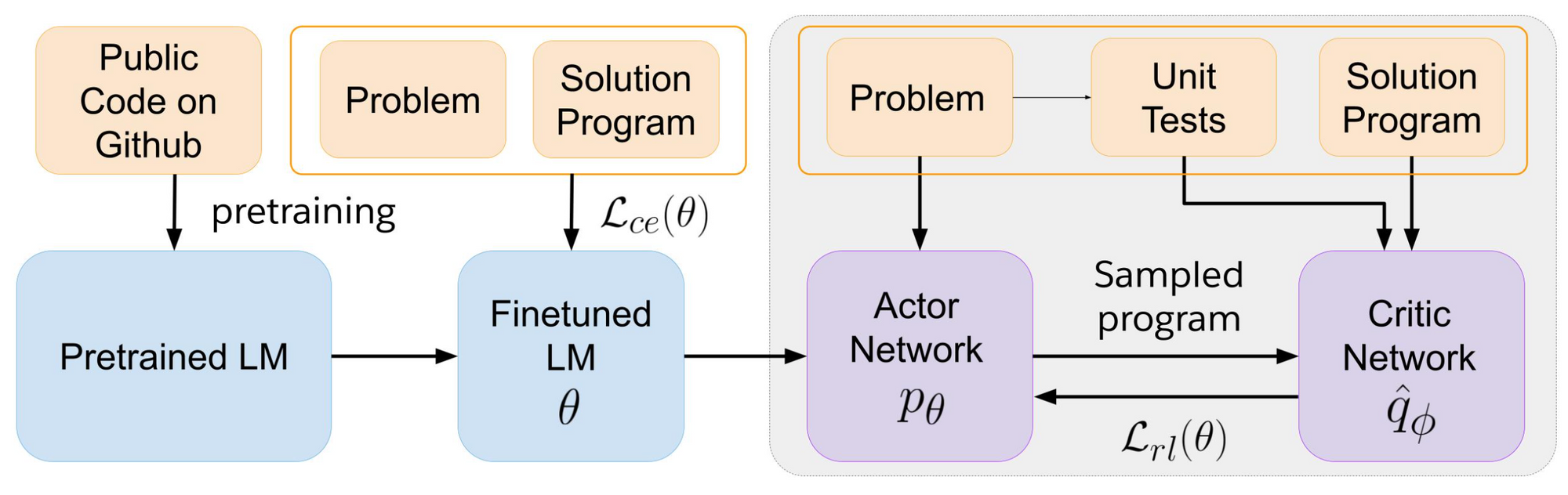
To finetune pretrained LMs for program synthesis, we propose a training strategy in an actor-critic approach:
- We treat the pretrained LM as an actor network and synthetically sample sequences from this actor, including both correct and incorrect programs.
- These program samples are passed to a critic network that is trained as an error predictor to assess the functional correctness of these samples.
- We use the token-level hidden states extracted from the learned critic model to estimate the values/scores of output tokens of these synthetic samples. The actor network is then finetuned on these synthetic samples weighted by their critic scores.
Refine and Repair Programs by Their Unit Test Results
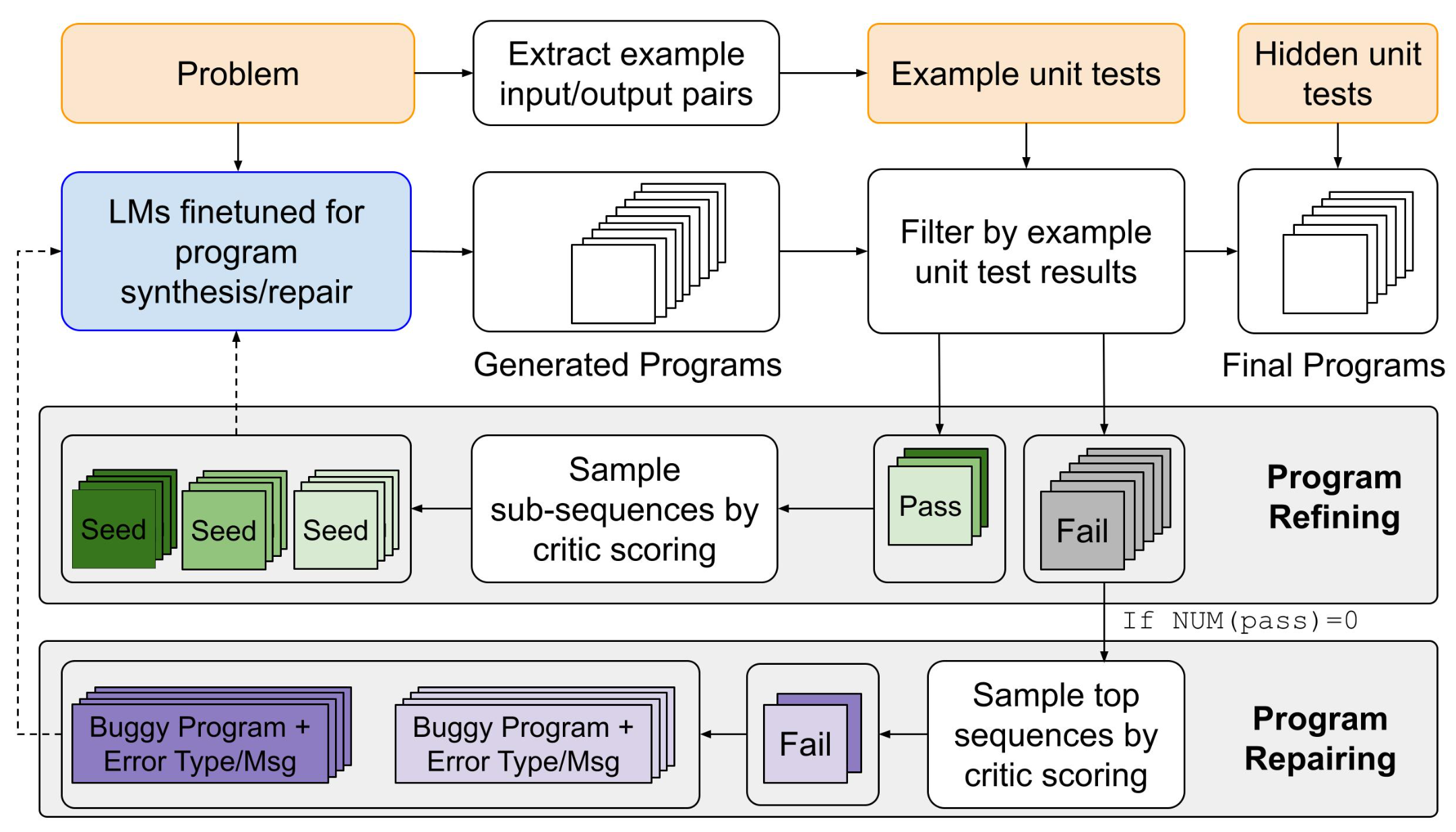
To better generate programs to solve unique unseen problems, we introduce Critic Sampling (CS), a new generation procedure that systematically exploits example unit test signals to allow models to further improve programs:
- For samples that pass the example unit tests, we employ the critic model to filter and select sub-sequences. These sub-sequences are utilized as seeds that condition the model to resample new tokens and construct new refined programs.
- Among failed programs, the critic selects top programs based on their likelihood of passing unit tests. These program candidates are concatenated with the error information received from a compiler and passed to a program repair module.
This generation procedure enables a dual strategy to automatically refine and repair output programs based on their unit test outcomes.
Example: How CodeRL Solves a Real-World Programming Problem
In the figure below, we show an example of a programming problem from the APPS benchmark and corresponding programs generated by CodeT5 variants. In CodeRL models, we further show programs before and after applying the CS procedure. The generated programs show that applying CodeRL can improve their functional correctness.
In addition, we found that applying the CS procedure improves the efficiency of generated programs to avoid timeout errors, an important quality in complex programming problems.

The above problem is from the APPS benchmark, and the solution programs are generated by CodeT5 and CodeRL.
-
Performance Results
New SOTA Results on Competitive Programming Tasks
On the challenging APPS code generation benchmark, we show that CodeRL with the improved CodeT5 model (770M) can achieve significant performance gains, outperforming many pretrained LMs of much larger sizes. Our approach achieved new SOTA results of 2.69% pass@1, 6.81% pass@5, and 20.98% pass@1000.
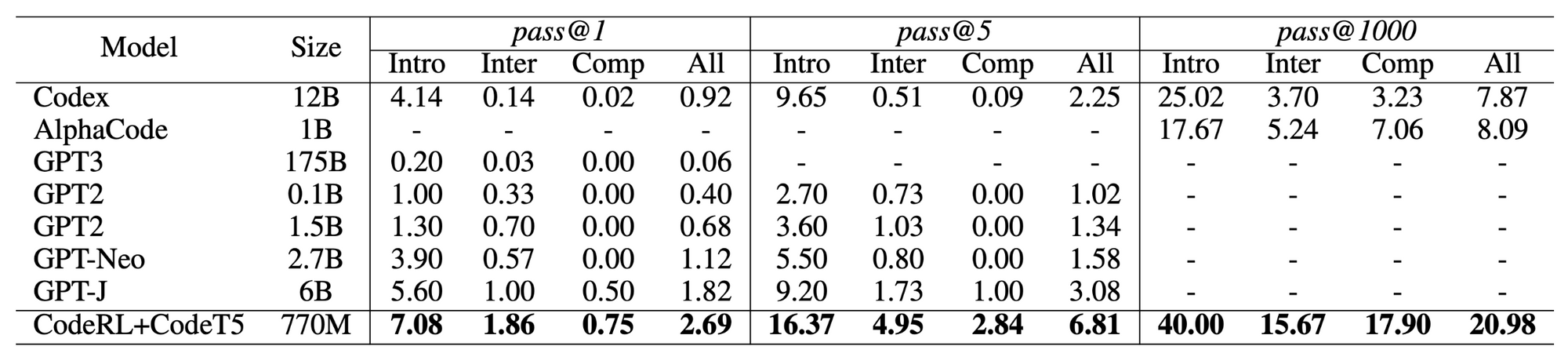
Above: Results of pass@k on the APPS benchmark. “Intro”: introductory, “Inter”: interview, “Comp”: competition-level tasks.
When evaluated on a subset of filtered code samples, our CodeRL+CodeT5 can achieve SOTA results of 8.48% 1@k and 12.62% 5@k.

Above: Results of n@k on the APPS benchmark. “Intro”: introductory, “Inter”: interview, “Comp”: competition-level tasks.
Note that while CodeRL incurs additional computational cost during inference with our Critic Sampling generation procedure, our approach requires a much lower generation budget k to achieve performance comparable to other models. For instance, with k=1000, our model performance is as good as AlphaCode with its much larger generation budget of k=50000.
Zero-shot transfer learning to the MBPP benchmark
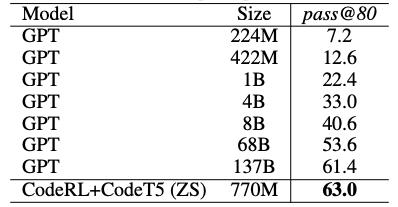
In addition to the APPS benchmark, we report the zero-shot transfer results of our CodeRL+CodeT5 on the MBPP benchmark and compare them with finetuned GPT models of up to 137B size. Our CodeRL+CodeT5 was trained on APPS and then evaluated on MBPP in a zero-shot setting. We observe that CodeRL with CodeT5 of a much smaller model size yields surprisingly good zero-shot performance, setting a new SOTA result of 63.0% pass@80. This indicatesthe strong zero-shot transfer ability of CodeRL for unseen tasks.
Please see our paper for more experimental results and analysis.
The Big Picture: Societal Benefits and Impact
Program synthesis can lead to substantial positive societal benefits, including:
Transforming future software development tools
Imagine a software development tool that goes beyond conventional editing options. Future AI-powered code editors could interact with human users more naturally, through natural language, allowing users to specify their intents to generate partial or full programs, fix code, and conduct unit testing automatically. CodeRL, which is designed for LMs learned from data in both natural language and programming language, can facilitate better systems that move ever closer toward achieving this ambitious goal.
Increasing developer productivity
Both professional software developers and students often spend a long time learning to understand complex problems, then designing, writing, and testing computer programs iteratively until they can eventually find a satisfying solution. We kept this problem-solving process in mind and designed the CodeRL framework with unit testing as a critical factor to improve generated programs. Applying CodeRL can improve any AI code-generation system, and facilitate a more productive programming process in both professional and educational environments.
Improving the accessibility of programming courses
Building a more intelligent code generation system can bring programming courses to a wider population. Imagine having a CodeRL-powered AI system as your programming teacher. You could interact with this tool at your convenience, and potentially at a much lower cost than a conventional human instructor (or even zero cost).
Of course, while this vision is an ambitious goal, the current state of program synthesis systems is far from perfect. Nevertheless, we believe CodeRL provides an important step forward to better AI models in the code domain and ultimately their applications to the software industry.
The Bottom Line
CodeRL is a general unified framework for program synthesisthat integrates pretrained LMs and deep RL holistically, adopting deep RL to improve pretrained LMs by exploiting unit test signals in both the training and inference stages.
- For model training, we introduce an actor-critic training approach to optimize pretrained LMs with dense feedback signals on synthetic code samples.
- During model inference, we propose a new generation procedure with critic sampling, which enables the model to automatically regenerate programs based on feedback from unit tests and critic scores.
By integrating CodeRL with the improved CodeT5-large model (770M), our framework achieved new SOTA results on both the APPS and MBPP benchmarks, surpassing the prior SOTA set by massive pretrained LMs of much larger model sizes.
Next Steps
CodeRL can be extended and improved in various ways. For example, it can be easily integrated with other (better pretrained) LMs, and improved with more fine-grained feedback from the environment, such as feedback received from a static code analyzer.
We hope CodeRL will inspire new innovations in neural code-generation systems, to tackle competitive program-synthesis problems and further extend to real-world programming applications.
Explore More
- Paper: https://arxiv.org/abs/2207.01780
- Code: https://github.com/salesforce/CodeRL
- Follow us on Twitter: @SalesforceResearch , @Salesforce
- Visit our main website to learn more about all of the exciting research projects that Salesforce AI Research is working on: https://www.salesforceairesearch.com
About the Authors
Henry Hung Le is a Research Scientist at Salesforce Research Asia, focusing on AI for software research and machine learning applications. His research interests include code generation, program synthesis, language models, dialogue systems, and multimodality.
Yue Wang is an Applied Scientist at Salesforce Research Asia with a focus on software intelligence. His research interests include language model pretraining, code understanding and generation, and multimodality. He is the main contributor to CodeT5, a programming language model that facilitates a wide range of code intelligence tasks.
Akhilesh Deepak Gotmare is a Research Scientist at Salesforce Research Asia, where he works on deep learning and its natural language processing applications like text generation, code generation, and code search. He leads applied projects aimed at identifying optimizations in Apex code using deep learning.
Steven C.H. Hoi is Managing Director of Salesforce Research Asia and oversees Salesforce's AI research and development activities in APAC. His research interests include machine learning and a broad range of AI applications.
Donald Rose is a Technical Writer at Salesforce AI Research. Specializing in content creation and editing, Dr. Rose works on multiple projects — including blog posts, video scripts, newsletters, media/PR material, social media, and writing workshops — and enjoys helping researchers transform their work into publications geared towards a wider audience.
Glossary
ground-truth program: a true, correct program that corresponds to the problem description. In other words, a target program that is a solution for the problem. A ground-truth program is a specific solution case that might be different from other generated (but still correct) programs by variable names, loop functions, etc.
regeneration: the process of generating a revised version of previous output — an improved program that is more functionally correct (and should be able to pass more unit tests). The ultimate goal, which might take multiple rounds of regeneration, is to find a program that is fully functionally correct (can pass all of the unit tests).
unit: a piece or snippet of code.
unit test: a test of a code unit (or an entire program) to make sure it operates properly.
unseen tasks/problems/tests: tasks/problems/tests not seen during model training.