 Blog Home
Blog HomeWarpDrive v2 Release Supports Numba to Simplify Machine Learning Workloads and Make Building Simulations Easier on NVIDIA GPUs
TL;DR: Deep reinforcement learning (RL), a powerful learning framework to train AI agents, can be slow as it requires repeated interaction with a simulation of the environment. Our original WarpDrive accelerates multi-agent deep RL on NVIDIA GPUs, enabling 10-100x speedups compared to alternative CPU+GPU implementations of multi-agent simulations. However, users had to write simulation environments in NVIDIA CUDA, which requires C expertise for coding and debugging. Solution: our newly released WarpDrive v2 supports running simulations in Numba, a drop-in replacement for NumPy. Users can now implement simulations much faster, using higher-level coding for rapid prototyping, and also have the flexibility to use CUDA for highest performance.
Multi-agent systems, particularly those with multiple interacting AI agents, are a frontier for AI research and applications. They are key to solving many engineering and scientific challenges in economics, self-driving cars, robotics, and many other fields.
Deep reinforcement learning (RL) is a powerful learning framework to train AI agents. For example, deep RL agents have mastered Starcraft [1], successfully trained robotic arms [2], and effectively recommended economic policies [3,4].
Problem: Multi-Agent Deep RL Experiments Take a Long Time
Multi-agent deep RL (MADRL) experiments can take days or even weeks, especially when a large number of agents must be trained, since MADRL requires repeatedly running multi-agent simulations and training agent models. This takes a lot of time because MADRL implementations often combine CPU-based simulations with GPU deep learning models, which introduces many performance bottlenecks due to the poor parallelism capabilities of CPU computations and heavy data transfers between CPUs and GPUs.
Solution: WarpDrive Meets the Need for Speed
To accelerate MADRL research and engineering, we built WarpDrive – an open-source framework for end-to-end MADRL on one or more GPUs. As its Star-Trek-inspired name implies, speed is the “Prime Directive” for WarpDrive, and it succeeds with flying colors.
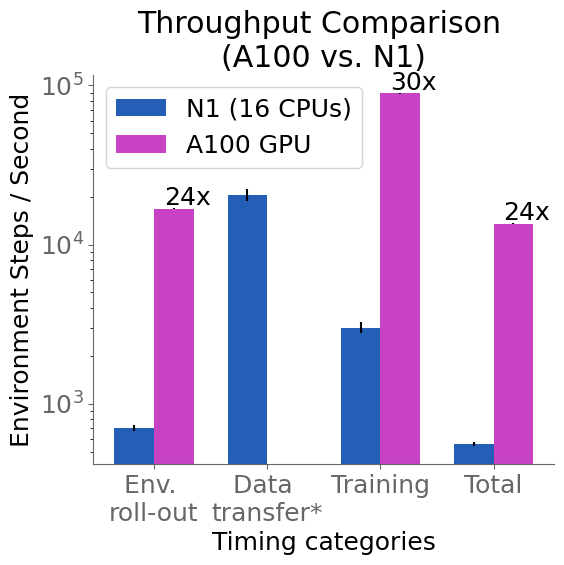
WarpDrive achieved impressive acceleration, as its design enables on the order of 10-100x speedups compared to alternative CPU+GPU implementations of multi-agent simulations. In one example – a simple Tag environment – WarpDrive achieves orders of magnitude faster multi-agent RL training with 2000 environments and 1000 agents [5, 6]. In the COVID-19 economic simulation [4] with 60 environments, as shown in the figure below, WarpDrive achieves a 24x throughput boost running on a single NVIDIA A100 Tensor Core GPU versus n1-standard-16 (16 CPUs) [7].

Want to build your own fast RL workflows? WarpDrive enables you to quickly develop new MADRL projects, providing tools and workflow objects to do it. For your own simulation, you need to implement the simulation step function in CUDA C.

Challenge: Make Coding Simulations Easier
The original version of WarpDrive did speed up MADRL, letting users address the “slow RL” problem by writing a CUDA C version of their simulation environment. However, CUDA programming relies on C expertise that not all developers have.
Is there a way to make programming simulations in WarpDrive easier and/or faster? Can we let users code in a higher-level language to create these simulations? Yes and Yes – thanks to our new version of WarpDrive!
Solution: WarpDrive v2 with Numba Simplifies Simulation Creation
We’ve released the second major version of WarpDrive, WarpDrive v2, which supports running simulations in Numba. Numba is a Python package – a drop-in replacement for NumPy – so users can now take advantage of the power of Python and NumPy to build their simulations.
Adding Numba to WarpDrive brings some significant benefits:
- Numba utilizes just-in-time (JIT) compilation to build architecture-specific machine code.
- Users can implement simulations much faster using a higher-level language. Coding is efficient because the user can now focus on higher-level design issues rather than low-level coding/debugging issues.
WarpDrive v2 provides a single API for both backends – CUDA C and Numba. All of WarpDrive's functions work with both Numba and CUDA, and users can switch back and forth between the two as they build simulations.
Deeper Dive
How to Use Numba in WarpDrive v2
To turn on the Numba simulation, users just need to specify env_backend=“numba”. WarpDrive will then automatically link the simulation built by users in Numba with the Numba-compatible core residing inside WarpDrive to complete the end-to-end simulation and training, as in the example shown below.
env_wrapper = EnvWrapper(
env_obj=TagContinuous(**run_config["env"]),
num_envs=run_config["trainer"]["num_envs"],
env_backend="numba",
)
trainer = Trainer(env_wrapper, run_config, policy_tag_to_agent_id_map)
trainer.train()
Demos and Tutorials
We encourage you to visit the following webpages to explore some tutorials, examples, code, and related documentation:
- NVIDIA NGC Hub offers users performance-optimized AI and HPC software containers, pre-trained AI models, and Jupyter Notebooks that accelerate AI development and HPC workloads on any GPU-powered on-prem, cloud, or edge systems
- Lightning tutorials
- Github tutorials
Numba or CUDA: Best of Both Worlds to Build Simulated Worlds
You may be wondering: if users can code in either Numba or CUDA, which is better, and when? Is it an advantage in WarpDrive v2 that users can "go back and forth" between CUDA C and Numba? Are there cases where a user might want to code in lower-level CUDA C instead of Numba, or would everyone always use Numba since it involves higher-level programming?
In general, we would say yes: the ability to go back and forth between the two (having the option of using either CUDA or Numba) is an advantage. Here's why:
- Numba/Python benefits: faster to learn, more efficient coding. Compared to using the lower-level programming language CUDA C, coding in Numba/Python should be faster to learn for some users, and more efficient (with built-in powerful features and shorthand commands that make commonly-used functions easier to write). Plus, thanks to Numba’s JIT compiler, it is also fast running on a GPU, with optimized runtime performance.
- CUDA’s advantage: performance. On the other hand, if you’re really pursuing the fastest speed, CUDA C is preferred because it is low-level pre-compiled code and compiled only once. According to our experiments, for very large-scale simulations, CUDA C is roughly 1.5x-3x faster than Numba in this domain (MADRL).
So, if you’re developing a complicated simulation, and experimenting with different simulation designs, it’s probably best to start with Numba. But if you’ve moved from the development and experimentation phase to the production phase, and this simulation will be used again and again, consider converting to CUDA C in the end, to ensure it’s optimized for speed.
In short, Numba is generally faster for development and experimentation, while CUDA C provides better performance, so "back and forth" seems like an ideal feedback loop, although it depends on many factors. The above “Numba or CUDA” debate is meant to stimulate thinking about the various factors, not to be the final word; each tool has its advantages, and can be the best choice for a given problem setup. The important thing is that we provide CUDA C and Numba to cover both low-level and high-level programming; for many users, high-level programming is more familiar and will speed development, while others will prefer CUDA C to make their code run as fast as possible. With WarpDrive v2, users can enjoy the best of both worlds.
The Bottom Line
The release of WarpDrive v2 is significant because it improves on the previous version in several ways:
- WarpDrive v2 supports both CUDA C and Numba (a drop-in replacement for NumPy).
- Support for Numba improves the user experience, switching it from low-level to higher-level programming.
- WarpDrive v2 provides a single API for both backends (CUDA C and Numba).
- All of WarpDrive's functions work with both Numba and CUDA backends, and users can switch back and forth between the two as they build simulations.
- In short, users now have more flexibility: they can leverage the power of Python and Numba to build their prototypes - and they also have the option to use CUDA, if desired, for production (for example, to achieve greater performance).
Explore More
Salesforce AI Research invites you to dive deeper into the concepts discussed in this blog post (links below). Connect with us on social media and our website to get regular updates on this and other research projects.
- Paper: Read more about this project in our research paper
- Original blog post: See our previous blog post on the original version of WarpDrive
- Code: Visit our GitHub at https://github.com/salesforce/warp-drive
- Container: Deploy WarpDrive on preferred system or with one click on Google Cloud from NVIDIA NGC catalog
- Tutorial: Extremely Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU
- Contact us: tian.lan@salesforce.com
- Follow us on Twitter: @SalesforceResearch , @Salesforce
- Blog: Check out our other blog posts at blog.salesforceairesearch.com
- Main site: To learn more about all of the exciting projects at Salesforce AI Research, please visit our main website at salesforceairesearch.com.
About the Authors
Tian Lan is a Senior Research Scientist at Salesforce Research, working for both the AI Operations team and the AI Economist team. For AI Economist, his main focus is on building and scaling multi-agent reinforcement learning systems. He has extensive experience building up large-scale and massively parallel computational simulation platforms for academia, automated trading, and the high-tech industry.
Stephan Zheng (www.stephanzheng.com) leads the AI Economist team at Salesforce Research, working on deep reinforcement learning and AI simulations to design economic policies.
Donald Rose is a Technical Writer at Salesforce AI Research, specializing in content creation and editing for blog posts, video scripts, newsletters, media/PR material, workshops, and more.
Related Resources
- Grandmaster level in StarCraft II using multi-agent reinforcement learning.
- Deep reinforcement learning will transform manufacturing as we know it.
- The AI Economist: Optimal Economic Policy Design via Two-level Deep Reinforcement Learning. Stephan Zheng, Alexander Trott, Sunil Srinivasa, David C. Parkes, Richard Socher.
- Building a Foundation for Data-Driven, Interpretable, and Robust Policy Design using the AI Economist. Alexander Trott, Sunil Srinivasa, Douwe van der Wal, Sebastien Haneuse, and Stephan Zheng.
- https://blog.salesforceairesearch.com/warpdrive-fast-rl-on-a-gpu/
- WarpDrive: Extremely Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU. Tian Lan, Sunil Srinivasa, Huan Wang, Stephan Zheng
- NVIDIA A100 Tensor Core GPU: https://cloud.google.com/compute/docs/gpus#a100-gpus n1-standard-16: https://cloud.google.com/compute/docs/general-purpose-machines#n1_machines
Acknowledgments
This release was made possible in part by NVIDIA, and we wish to thank them for their significant help and support. Special thanks to Brenton Chu for being the first to write a Numba simulation, which motivated us to update the entire codebase and make it compatible with Numba. We thank our partners for their generous support and can’t wait to see what you create with this release!