 Blog Home
Blog HomeTrusted NLG Research @ Salesforce AI
Intro
In 2023, we witnessed the rapid development of generative AI, starting with the ascent of ChatGPT. This led to a surge in the creation of competitive closed-source large language models (LLMs) like Claude, Command, and Gemini as well as open-source models such as Llama-2, Mistral, including our released model XGen. Despite all of the advancements and rapid improvements, issues in these models such as a tendency to produce biased or factually inconsistent output may prevent users from fully trusting such systems.
At Salesforce, trust is our #1 value, and we at Salesforce AI Research have helped lead the way in understanding what it means to create trusted natural language generation (NLG) by analyzing existing methods, improving modeling approaches, fine-grained evaluating, and implementing solutions into the Salesforce Trust Layer. The Salesforce Trust Layer is equipped with best-in-class security guardrails from the product to our policies. Designed for enterprise security standards, the Einstein Trust Layer allows teams to benefit from generative AI without compromising their customer data.
Overview of Trusted NLG - SalesforceAI Research
AI has been at the core of Salesforce products, as shown in the image below, and even before this recent wave of LLM work, Salesforce has been a leader in AI, producing impactful research to make AI models more trusted.
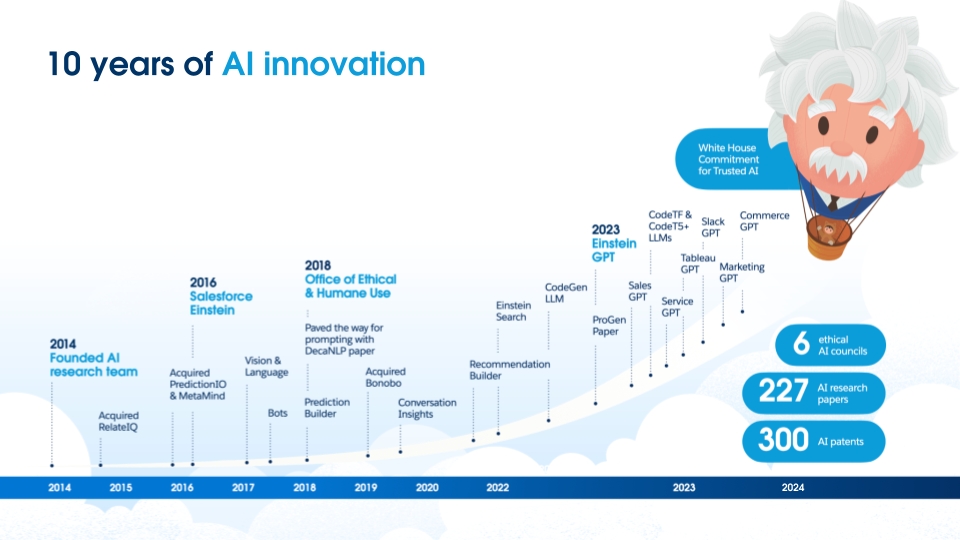
For example, our earlier work focused on reducing gender bias in AI models. We also called for a more robust evaluation of these models and an understanding of factual errors found in tasks such as summarization. To further help the community evaluate and understand their models, we have released open-source tools such as Robustness Gym and SummVis. Robustness Gym is a simple and extensible evaluation toolkit that unifies several robustness evaluation paradigms, while SummVis is a visualization tool focused on summarization that enables users to understand and visualize metrics such as factual consistency that ground a summary in its input context.
With the proliferation of LLMs, Salesforce has continued to be at the forefront of research in trusted AI. The main focus of our contributions, and the focus of this blog post, have been on factual correctness and evaluation; for AI methods to be trusted the output must be factually consistent with the input and evaluation must be robust to understand the strengths and weaknesses of the models. Below we briefly describe some of our contributions along the dimensions of improving methods for factual consistency along with our work on benchmarking and evaluation.
Methods for improving factual consistency
Within improving factual consistency, some of our work has focused on better grounding entities found in the input context and ensembling models trained on varying levels of noisy data in our CaPE paper. In our Socratic pretraining paper, we proposed better ways to pretrain a model that allows for the grounding of the output on important questions that a user may ask while also making the model more controllable. Where training a model further can be difficult, we have proposed several methods that edit an existing model’s output by either compressing the output or verifying the model’s reasoning.
Methods for evaluation
In order to fully understand the improvements introduced by the methods discussed above, a thorough evaluation is essential. We have introduced automatic methods for to assess whether a model’s summary is factual consistent with its input context. Our approaches include a model that checks whether the summary is entailed by the input and a model that verifies whether the input context can be used to answer questions based on the model summary. However, much of our work focuses on building benchmarks that aim to understand the current status of the field. These benchmarks cover a diverse set of tasks, from fact-checking in dialogues to classification in multi-turn settings to analyze whether a model flip-flops, or changes its answers to queries.
Several of our benchmarking works have centered around summarization. In our AggreFact benchmark, we aggregate recent summarization systems and propose a method to align their error types for a more comprehensive analysis. SummEdits proposes an efficient method to leverage LLMs in the annotation process for factual error analysis and benchmarks the most recent LLMs as evaluation models. Similarly aiming to refine evaluation protocols, our RoSE benchmark introduces a protocol for human evaluation of whether a summary is relevant that achieves high inter-annotator agreement among crowd-sourced workers, and our DiverseSumm work builds on the insights of our previous papers on evaluation and breaking down tasks to simpler components in the context of multi-document summarization.
Case Studies
Below we select two representative works that highlight our efforts to improve evaluation and understand model performance across the quality dimensions of relevance and factual consistency. Our case studies focus on summarization but could be applied to other generation tasks.
Case Study 1: Trusting Human Evaluation
This section follows our work Revisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation.
Motivation
To properly evaluate a summarization system, the model output summary is evaluated to the information in the source, its intrinsic characteristics, and potentially to reference summaries. These comparisons are done using both automatic evaluation metrics as well as human evaluation. This setup is shown in the figure below.
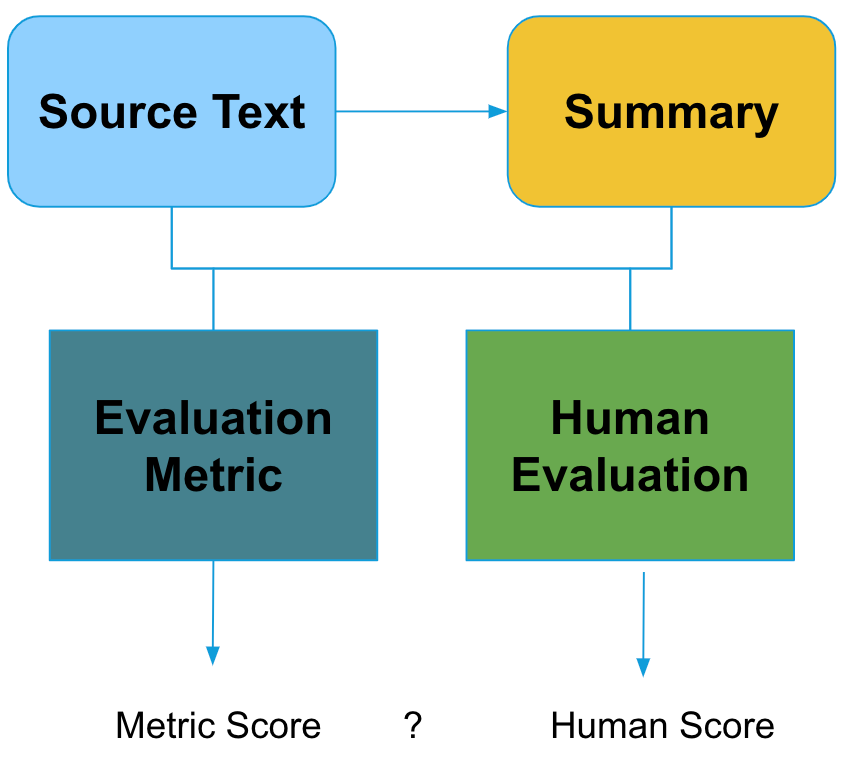
Human evaluation is regarded as the gold standard for both evaluating the summarization systems and the automatic metrics. However, simply doing human evaluation does not automatically make it the ‘’gold’ standard. In fact, it is very difficult to properly conduct a human evaluation study, as annotators may disagree on what a good summary is and it may be hard to draw statistically significant conclusions based on the current evaluation set sizes.
These difficulties motivate us to perform an in-depth analysis of human evaluation of text summarization. Our first focus is a better protocol and benchmark.
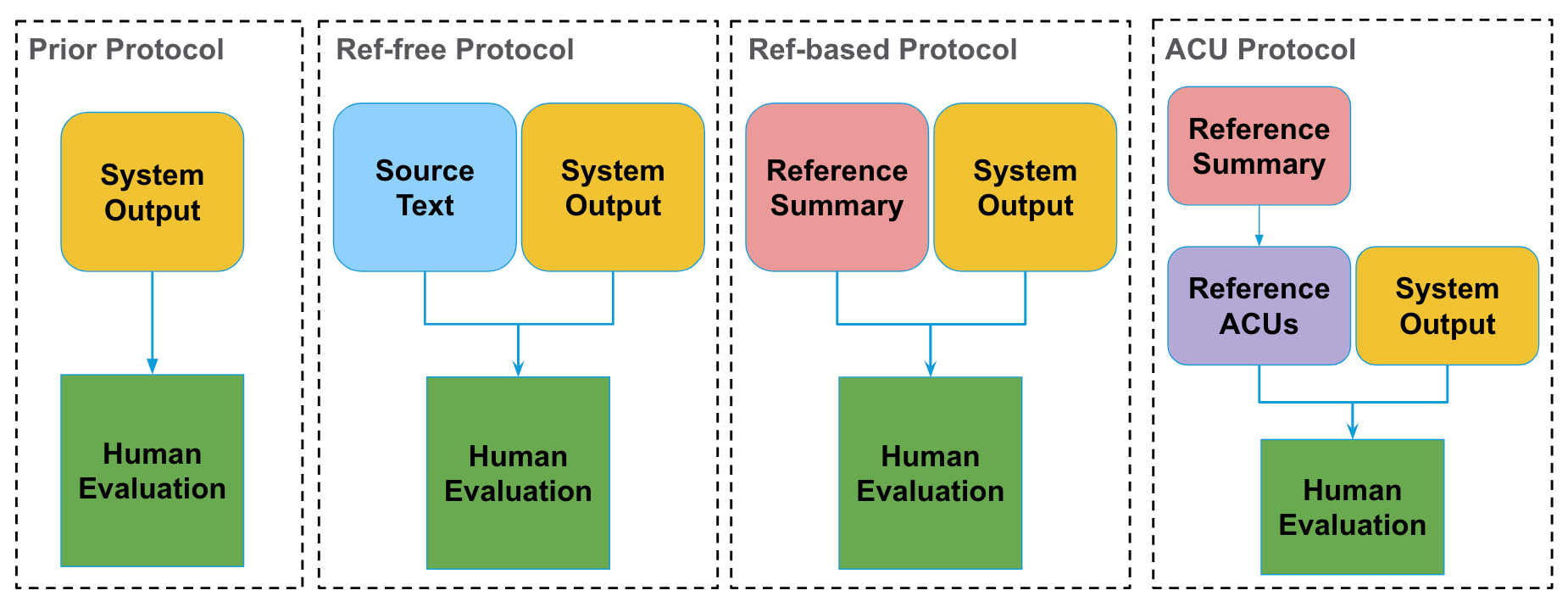
ACU Protocol
The goal of this protocol is to allow our annotators to objectively judge whether the summary contains salient information from the reference summary.
To do so, inspired by the pyramid evaluation protocol, we dissect the evaluation task into finer-grained subtasks with the notion of atomic content units.
We take the reference summary and ask experts to extract simple facts, or atomic units, from the reference. The first stage is done by experts, as it’s considered a more difficult task to write the units. Then for each system generated summary, we check whether that fact is present or not. This second matching stage is done by crowdsourced workers. This process is illustrated in the figure below.
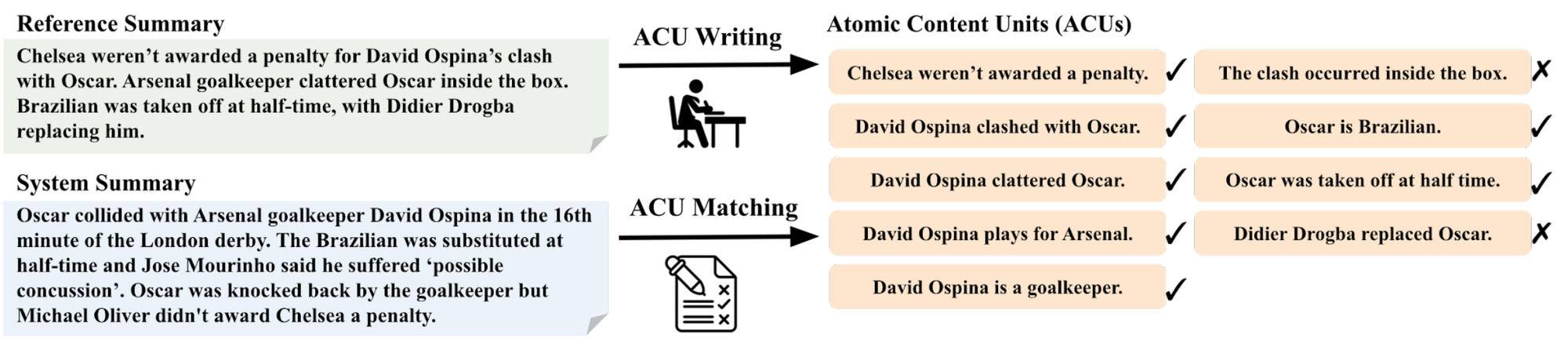
We collect data following this protocol over three common summarization datasets covering news and dialogue domains. The resulting benchmark, which we call RoSE (Robust Summarization Evaluation) contains three test sets and a validation set on the CNN/DailyMail dataset. We achieve a high inter-annotator agreement, with a Krippendorff’s alpha of 0.75. Dataset statistics are shown below.
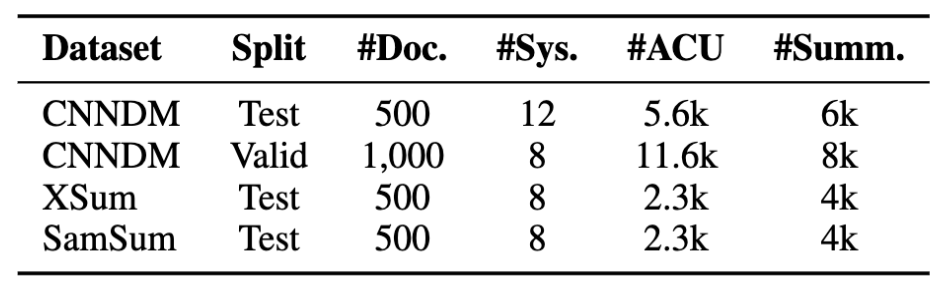
Our benchmark consists of 22,000 summary-level annotations over 28 top-performing systems on three datasets. Standard human evaluation datasets for summarization typically include around 100 documents, but we have 5 times as many documents, which allows us to draw stronger conclusions about differences in system performance.
Evaluation Protocol Comparisons
To better understand our ACU protocol, we compare it against three other common human evaluation protocols, namely protocols that do not take into account a reference summary (Prior and Ref-free) and those that compare with a reference (Ref-based and our ACU protocol). In order to evaluate these protocols, we collect annotations on 100 examples from our benchmark for the three other protocols. The following diagram shows what the annotator sees when annotating according to each protocol.
We perform a focused study on the most recent BART and BRIO models, which are supervised language models, and the zero-shot LLMs of T0 and GPT-3.5 (davinci-002). The results are shown in the diagram below.
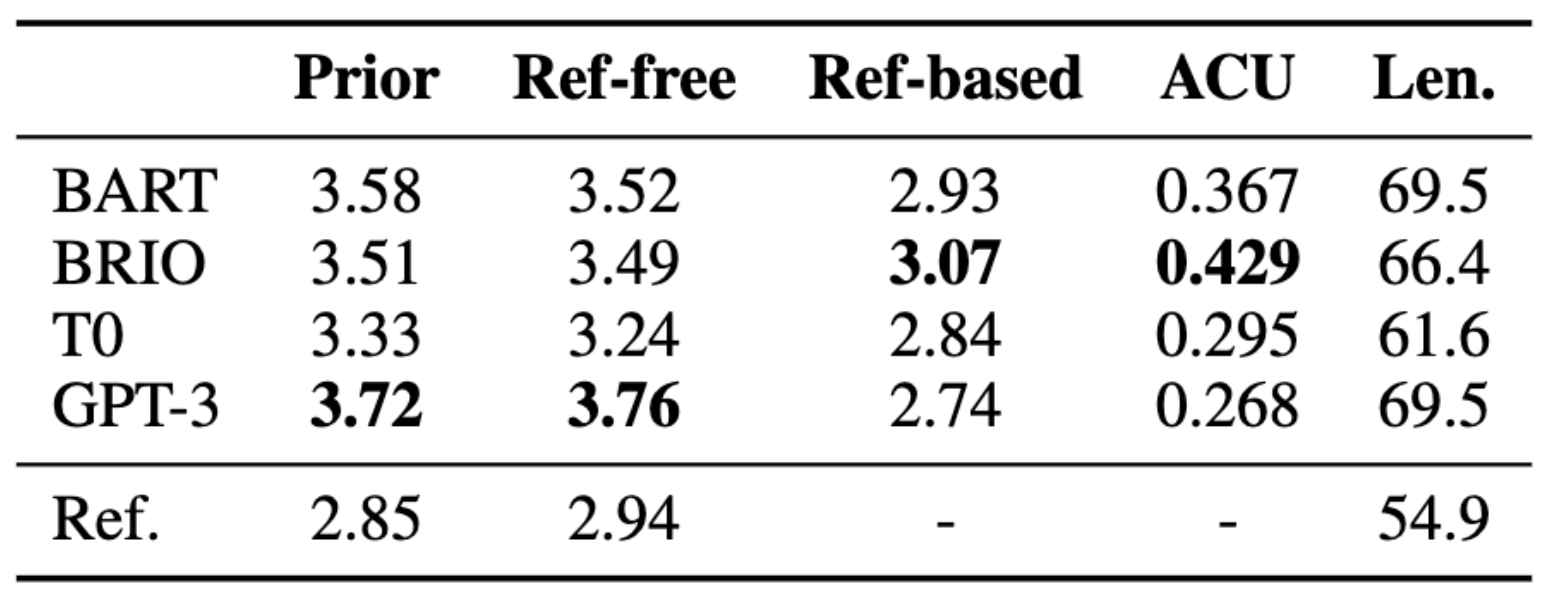
We find that GPT3 does better on protocols where the annotator does not see the reference, as it’s not trained to produce such summaries. Furthermore, there are issues with the references which have been noted by prior work, and they are not favored by annotators.
We also analyze for potential confounding factors in our protocol comparison. We find that the annotator’s prior score is a better predictor of their own reference-free score than if you use the scores of other annotators; the correlation between an annotator’s prior and ref-free score is .404, while the correlation between the ref-free score and score from other annotators is only 0.188. This suggests that the prior score influences the score of the annotator’s judgment even when they have access to the documents.
Takeaways
When evaluating system performance, we should have clearly defined targets. Otherwise, as seen above, the annotator’s prior preference can play a large role in evaluation results.
We also want to note the difference between reference-free and reference-based evaluation and how to choose between them. Reference-based evaluation can be more objective and easier to perform. However, reference-based evaluation can be more restrictive, and some quality aspects are by definition reference-free such as factual consistency and coherence. Furthermore, reference-free evaluation aligns with training techniques such as RLFH; however, it may be noisier and more subjective.
We stress that fine-grained human evaluation across protocols can lead to more robust and objective results. The same principle has been applied to the evaluation of several summary qualities such as factual consistency and coherence. We believe extending our ACU protocol to reference-free additional evaluation dimensions is a promising direction.
Overall, human evaluation is becoming even more important with the current progress of LLMs and the introduction of training techniques like RLHF, and there is much room left for improvement, such as proposing more targeted human evaluation protocols and improving the reliability and reproducibility of human evaluation practices.
Case Study 2: Trusting Benchmark Evaluation
This section follows our work SUMMEDITS: Measuring LLM Ability at Factual Reasoning Through The Lens of Summarization. As mentioned in the previous part, we want to perform a targeted evaluation of additional quality dimensions, and in this work, we focus on factual consistency.
Motivation
Prior work has pointed to low inter-annotator agreement and variations in how different papers have annotated factuality categories. This is unfortunate given how factuality should be one of the more objective categories to annotate. Another factor in this annotation, is that as opposed to a quality dimension such as coherence or our ACU annotation evaluating factuality generally requires reading the entire input, which can be very costly when only annotating several examples per document.
Guiding Principles for Factual Consistency Benchmarking
We design a benchmark that embodies several principles from our analysis of existing work on factual consistency. Additional details on our analysis are found in the paper.
- We frame factuality evaluation as a binary classification to improve interpretability; a yes/no classification of whether a summary is factually consistent with the input is more interpretable than a score between 1 and 5.
- Our focus is factual consistency, so we do not want factors such as grammaticality or fluency errors to influence annotations. Previous benchmarks include summaries that may have imperfections in fluency or formatting. We remove such summaries in order to have the annotator only focus on the factual consistency label.
- We want high inter-annotator agreement to improve the reproducibility of the protocol, and we also want a task that humans can perform but the models may struggle with.
- We want the benchmark to be diverse across a wide range of error types and domains.
SummEdits Annotation Protocol
We incorporate the above principles into our annotation schema for factual consistency.
In the first step, we select a document and a seed summary (which may come from the original dataset or be LLM-generated) and validate that they do not contain errors. We use an LLM to generate many minor edits of that summary, producing additional consistent and inconsistent edits. Then, we manually classify each edit as consistent, inconsistent, or borderline/unsure. We remove the borderline cases to ensure that our dataset only includes high-quality samples. An overview of our annotation pipeline is found below.
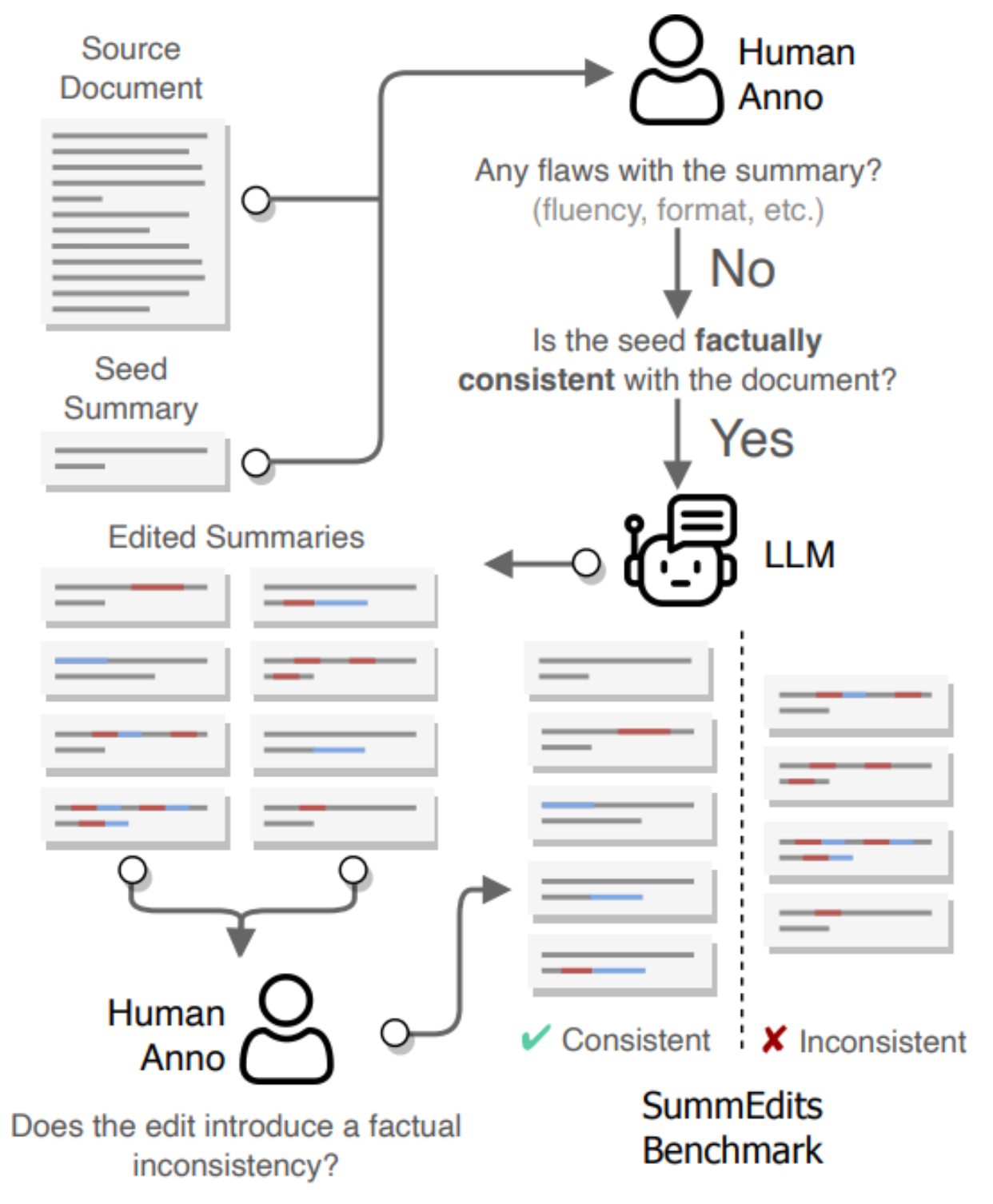
To be more concrete, we ask GPT3.5-turbo to edit the seed summary by modifying a few words to create additional consistent and inconsistent examples. The edited summaries have and average of 3.6 words inserted, and 3.5 words deleted. We ask the model to generate about 30 modified summaries per document and thus the annotator does not have to read multiple input documents. This results in a cost of about $300 for 500 annotated samples. We hire a professional editor for this annotation step.
SummEdits Benchmark
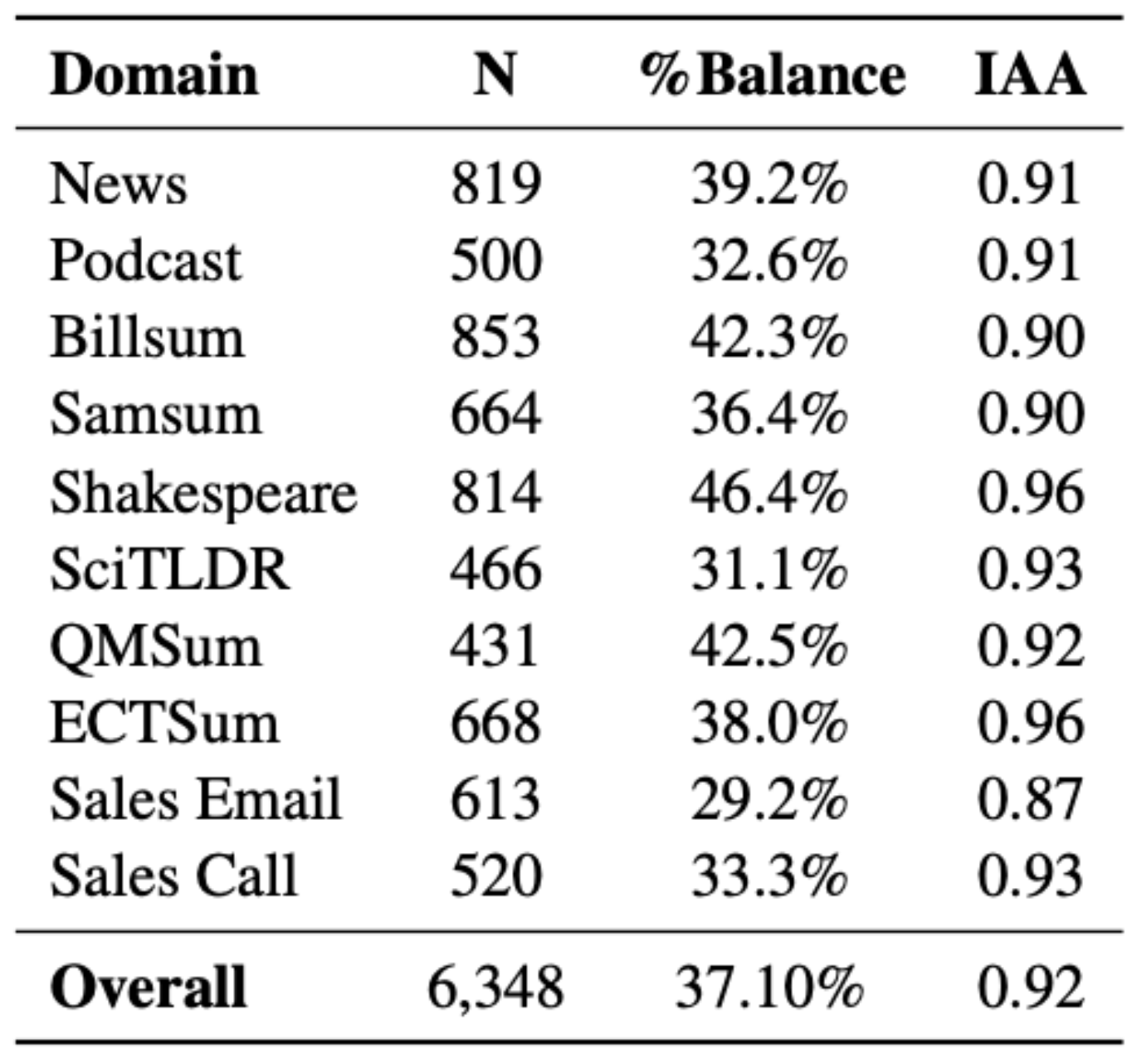
We apply this approach on 10 domains raining from news to dialogue, scientific text and sales calls. For 5 of the domains, we automatically generate a seed summary from GPT 3.5 turbo due to the lack of high-quality existing reference summaries.
In the final benchmark, 37% of summaries are consistent, approaching our objective of a balanced benchmark to facilitate robust evaluation.
The authors of the paper annotated 20% of the benchmark samples for factually consistent or inconsistent and achieve a high inter-annotator agreement, and even higher when removing the borderline cases from initial annotations. See the below table for an overview of the domains covered, dataset size, and agreement.
As noted, the benchmark creation process is quite efficient, costing $300 per domain. We compare to the estimated costs of a previous factual consistency protocol FRANK, which would cost about $6000 to produce a dataset of similar size for a new domain, which you would then have to multiple by 10 to match our overall benchmark size.
Analysis
In the table below we show the averaged accuracy results across domains for SummEdits for top LLMs at the time of submission.
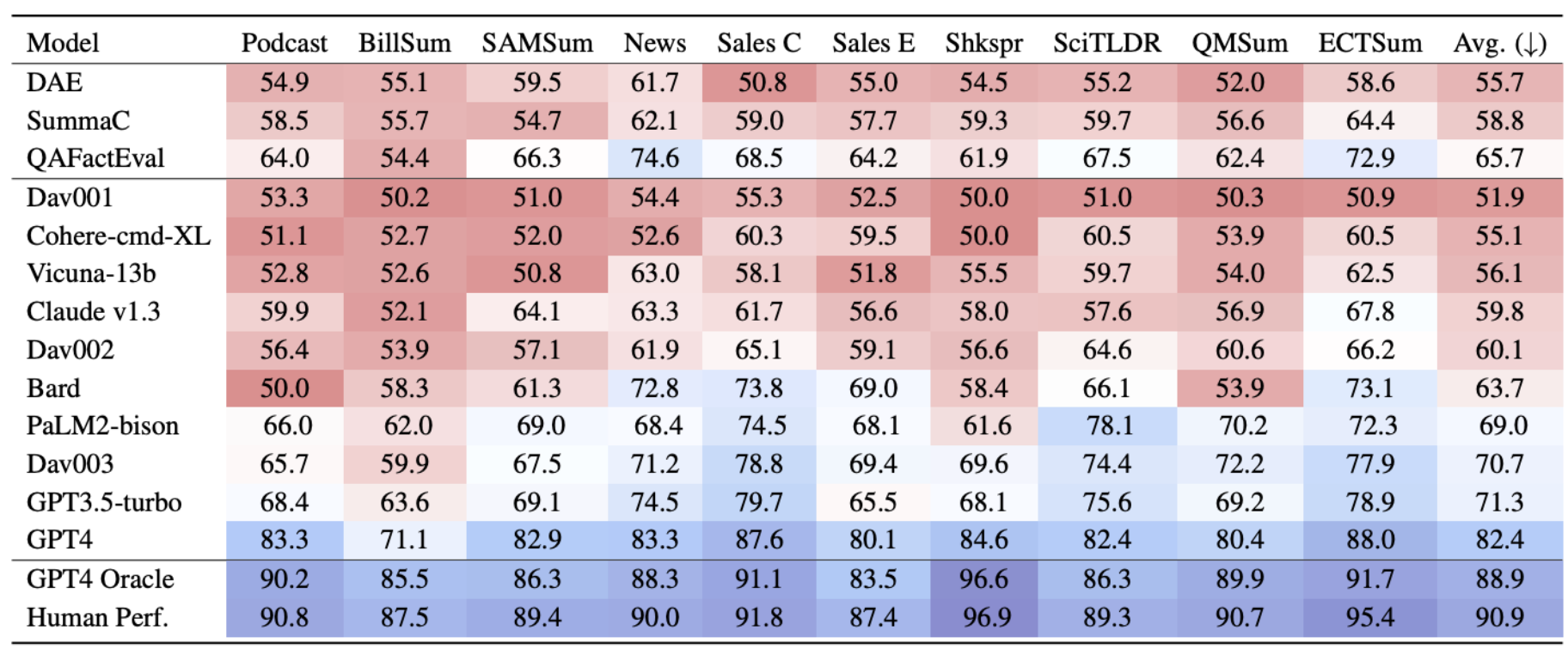
We find that the QAFactEval performs well, only being outperformed overall by 4 LLMs. We find the the non-LLM metrics perform best on the news domain, which makes sense given that they were largely developed and tested on news. For the legal domain and Shakespeare dialogue domains, most models performed the worse. These differences point to the necessity to develop and test across multiple domains.
At the bottom of the table, we show estimated human performance as well as an oracle setting. In the oracle setting, we append the seed summary to the article and modified summary. The seed summary here serves as an information scaffold, and the improved performance confirms that high model performance is attainable; the challenge in the benchmark lies in aligning the facts of the edited summary with the document when the model doesn’t know what has been edited.
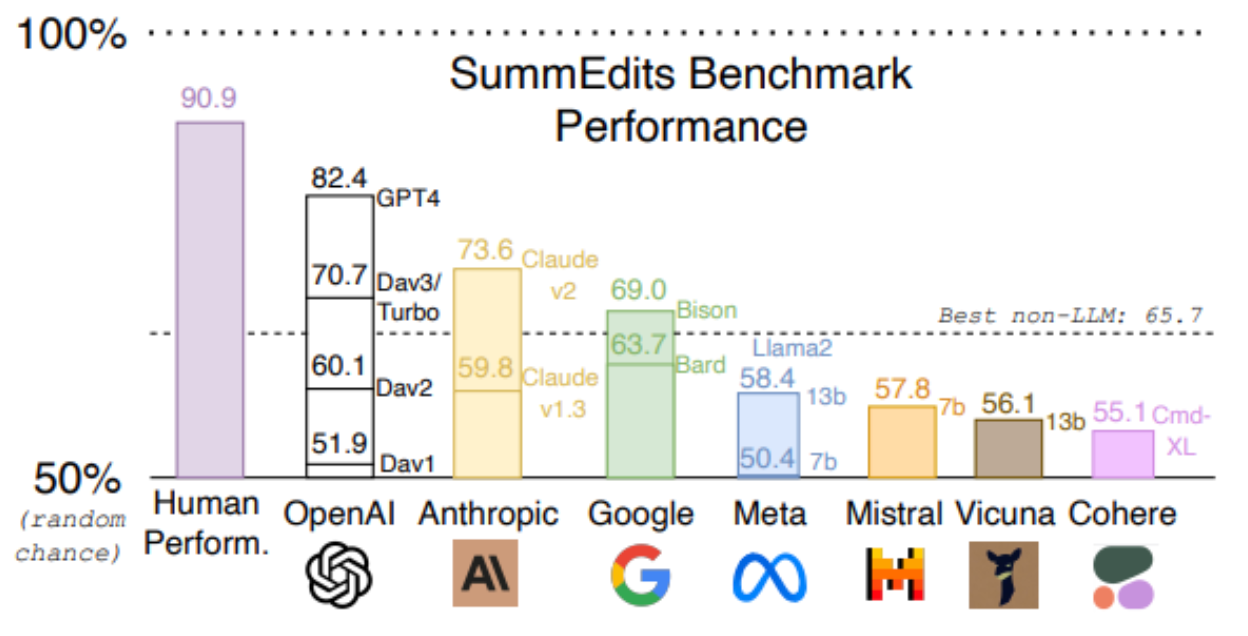
In the table below, we visualize the average performance across competing models. As can be seen, there still remains a gap between the top model and human performance and a sizable gap with other models. Thus we believe that the SummEdits provides a robust, challenging benchmark for LLM factual consistency evaluation comparisons.
Takeaways
In this work, we benchmark LLMs on prior data, but also use them to take a critical approach to previous benchmarks and potential errors in their creation. We call for more reproducible and challenging benchmarks like the one we introduce here. Clear and atomic edits and breaking down the annotation process, similar to the above RoSE benchmark, simplify the data collection and allow for better annotator agreement.
Overall, given the improvements of LLMs, we are able to leverage them to scale annotation processes. In this work, we found only GPT3.5 or 4 were able to generate refined enough edits without completely rewriting summaries. The LLM chosen could very well have an effect on which models are preferred, and ideally, we could leverage multiple LLMs in this process.
Additionally, we focus on the binary classification task, but this data could be used for error localization or error correction in future studies. Also, as opposed to other benchmarks, we are benchmarking models as metrics and not models as underlying summarizers, but could leverage our data for example by comparing the likelihood of consistent summaries across summarizers.
Conclusion
While we’ve seen amazing improvements in model performance over the last several years, we must be aware of the remaining downsides of these models. We believe that by jointly improving these models as well as evolving our approaches to evaluating them is essential going forward. We will continue to research the areas of factual consistency and evaluation, open-sourcing our paper code and tools such as our AuditNLG to promote trusted NLG.