 Blog Home
Blog HomeTalk to Your Data: One Model, Any Relational Database
TL;DR: We introduce Photon, a live demo of a natural language interface to databases based on our latest research in neural semantic parsing. 🔗 https://naturalsql.com/
Recently the field has seen a surge of interest in natural language based data querying approaches. This is partially driven by the latest advances in natural language processing that led to the development of voice- and text-based interfaces in a wide range of applications. Easy and fast access of data is a continuous demand, and the investment in natural language information systems dates back to the early days of database systems. Previously, Salesforce released WikiSQL, a large-scale benchmark dataset which enabled significant progress in mapping natural language utterances to structured queries over open-domain tables. This article describes our latest research in this area towards more intelligent and robust modeling, and introduces Photon, a live prototype of a natural language interface to complex relational databases.

Background
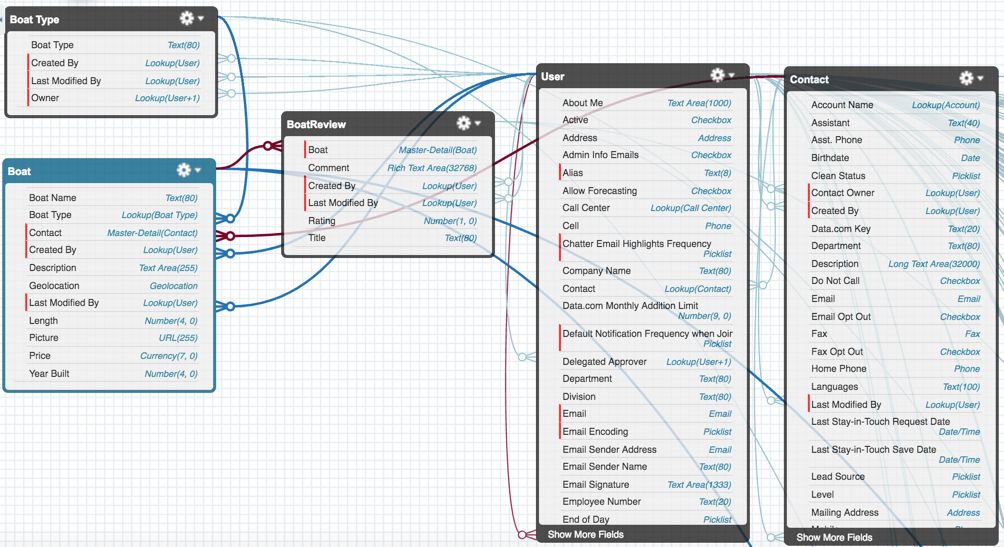
Relational Databases (DBs). The relational database, introduced in 1970, remains the dominant database architecture used across industries. It organizes data using inter-linked tables consisting of columns (also called "fields" or "attributes") and rows (also called "records" or "tuples") (Figure 2). Generally, each table represents an entity type (e.g. user and contact); each column represents an attribute of the entity type (name and address) and each row represents an instance. Some columns are primary keys, used for uniquely identifying a row (e.g. contact.account_name), and some are foreign keys, used to reference a primary key in a different table (e.g. boat.contact).
Structured Query Language (SQL). Most databases employ SQL as the language for users to query (SELECT) and manipulate data (UPDATE/ INSERT / DELETE). Industrial database management systems (DBMSs) often implement their own SQL dialects (PostgreSQL, SQLite, Oracle, MySQL etc.) and extensions. While these dialects vary widely and are incompatible with each other, most of them support some common functionalities. Figure 3 shows a complex query that selects the average review scores of bow-riders by users from different departments, which requires joining three tables.

Natural Language Interfaces to Databases (NLIDBs). While SQL was originally intended for end users, query construction is often laborious in practice and creates steep learning curve. As of today, it is common for SQL queries to be embedded into software to provide a more accessible user interface (e.g. dashboards). This, however, does not eliminate the need for natural language based querying, which supports greater user initiative and is often less distracting.
System
Photon is a state-of-the-art NLIDB prototype that supports most common SQL operations (including table joins and query compositions) and works across different databases.
We design Photon following two core principles: intelligence and robustness. It adopts a modular architecture comprising a state-of-the-art neural semantic parser, a human-in-the-loop question corrector, a DB engine and a response generator. We expect the interface to correctly interpret a large and diverse set of natural language questions, while avoiding unreliable guesses for noisy input.
Cross-Database Semantic Parsing. The core of an NLIDB is a semantic parser that maps a natural language user input to an executable SQL query. Photon adopts a cross-DB semantic parsing model that realizes this mapping for a large number of DBs, including DBs it has never been trained on.
| DB | Question | SQL Query |
| Wines | Title of most expensive wine | SELECT wines.Title FROM wines ORDER BY wines.Price DESC LIMIT 1 |
| Concert | What is the top attendance for a performance? | SELECT MAX(show.Attendance) FROM show |
| Employee | Bonus of Vickery | SELECT evaluation.Bonus FROM employee JOIN evaluation ON employee.Employee_ID = evaluation.Employee_ID WHERE employee.Name = "vickery" |
Following previous work [2,4], we design an encoder-decoder model that takes a natural language question and the target DB schema as input and synthesizes a SQL query as output. We represent the input question and the DB schema jointly as a tagged sequence (Figure 4), which is first encoded with BERT and then a bi-directional LSTM. We use the hidden representations corresponding to special tokens [T] and [C] in this encoding as the table and column representations, and infuse them with DB metadata features. The question portion of the encoding is further encoded with another Bi-LSTM, and we use its output as the start state of the decoder.
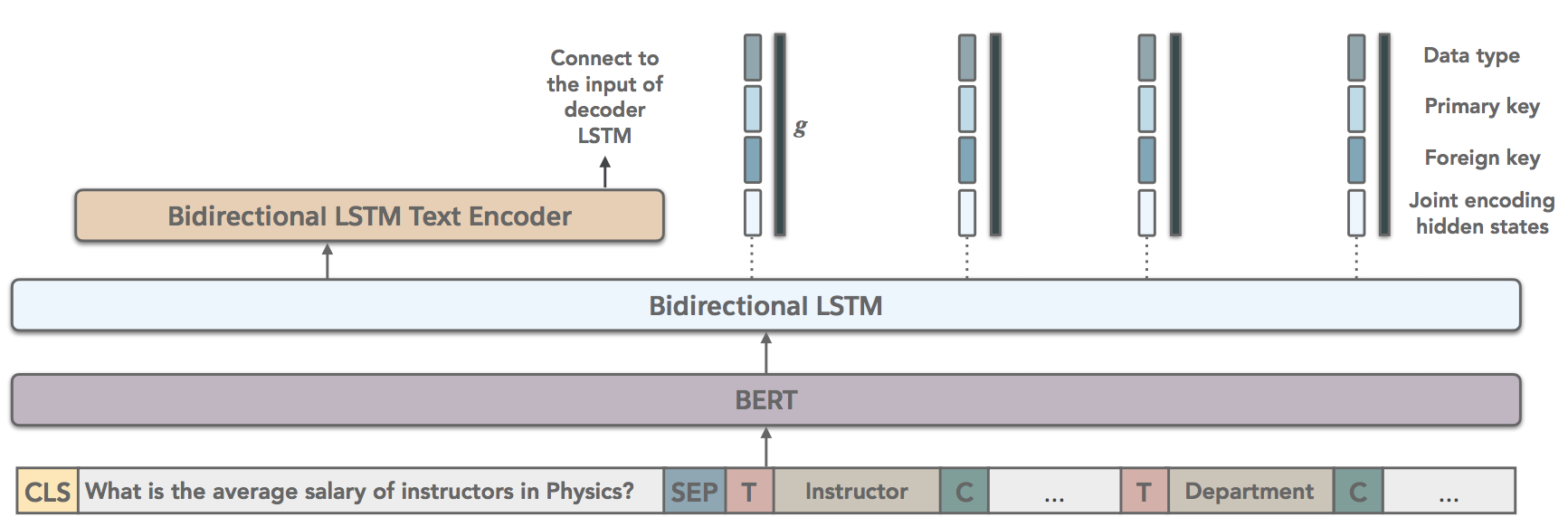
[T] and [C]. We represent a DB as the concatenation of its table representations, and further concatenate it with the input question. Our decoder is an LSTM-based pointer-generator model that generates complex SQL queries as a sequence of tokens. At each decoding step, the decoder performs one of the three actions: generating a SQL keyword, copying a table/column, or copying a token from the input utterance, determined by a learned gating function.
We train the model on a popular cross-DB text-to-SQL dataset, Spider [4]. Combined with table value augmentation and static SQL correctness checking, our model achieves state-of-the-art structure matching accuracy on the Spider dev set. More details can be found in our research paper. (We are continuously improving the semantic parser and updating the Photon backend.)
Handling Untranslatable Utterances. While state-of-the-art cross-DB semantic parsers are able to handle a large set of common user requests, there is still ample space for improvement. Besides reducing errors made on questions that have a SQL translation, we also need to properly handle input utterances that cannot be mapped to a SQL statement, even by humans.
Practical NLIDBs are exposed to a wide range of noisy user input. Users tend to employ underspecified and incomplete NL expressions when interacting with such interfaces [5,6], and may ask for information that is not provided by the DB. For such input, learning-based semantic parsers can make unreliable guesses that may appear correct on the surface. This issue is especially severe for end-to-end neural semantic parsers when the noisy input appears similar to a valid input in the embedding space.
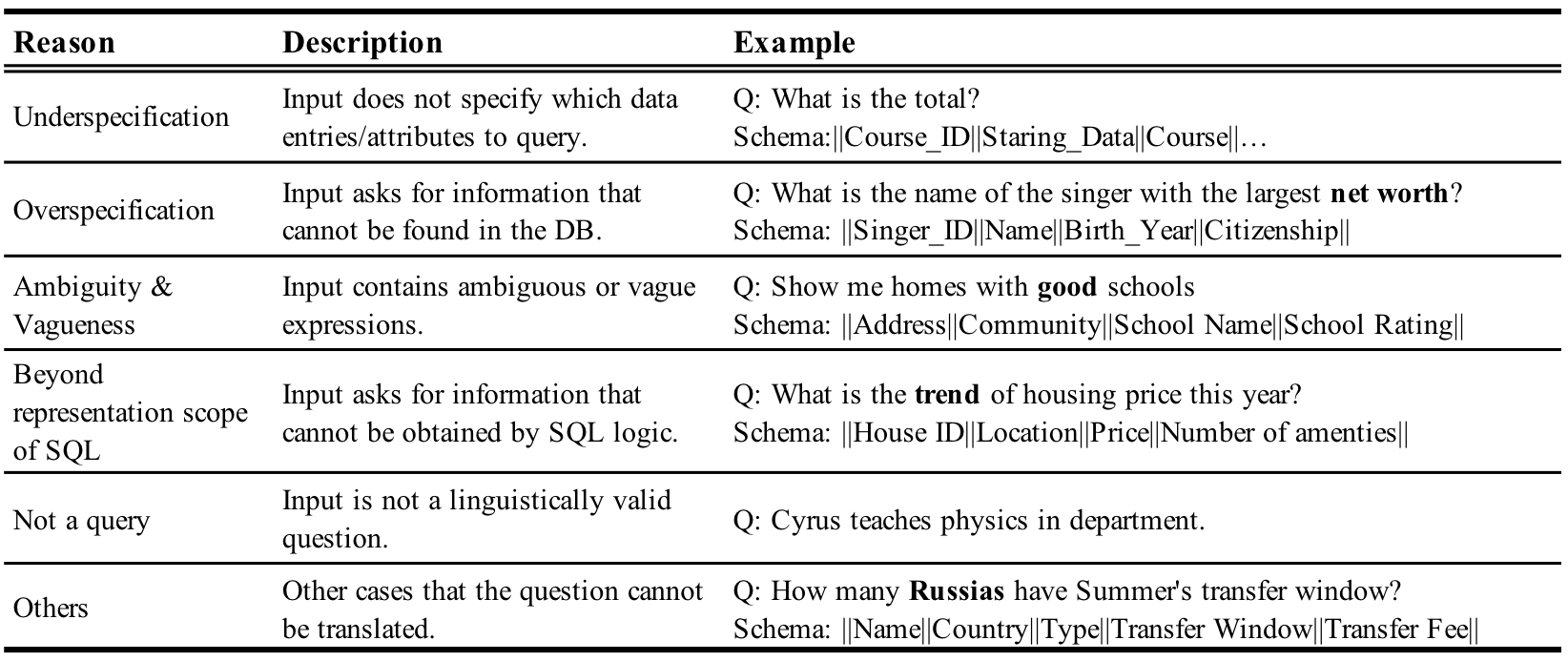
Photon implements a module that automatically detects untranslatable input utterances and highlights the ambiguous spans in order to help users rephrase the utterance. To this end, we perturb the Spider dataset to automatically synthesize a large number of untranslatable utterances corresponding to the categories in Figure 5. Our perturbation method yields not only untranslatable questions but also the exact span that causes it to be untranslatable. With this new data, we train a neural translatability detector by extracting confusion spans from the input utterance. If a confusion span is detected, we deem the question untranslatable and prompt the user to rephrase. If the model detects that a confusion span likely refers to a field, we run a language model perplexity check to identify the possible target field and suggest it to the user. More details can be found in our research paper.
Dual-Input Mode. Photon accepts both natural language questions and well-formed SQL queries as input. It automatically detects the input type and executes the input immediately if it is a valid SQL query. We expect that under certain cases, forming a natural language question can be difficult and writing SQL directly may save time, especially for users proficient in SQL.
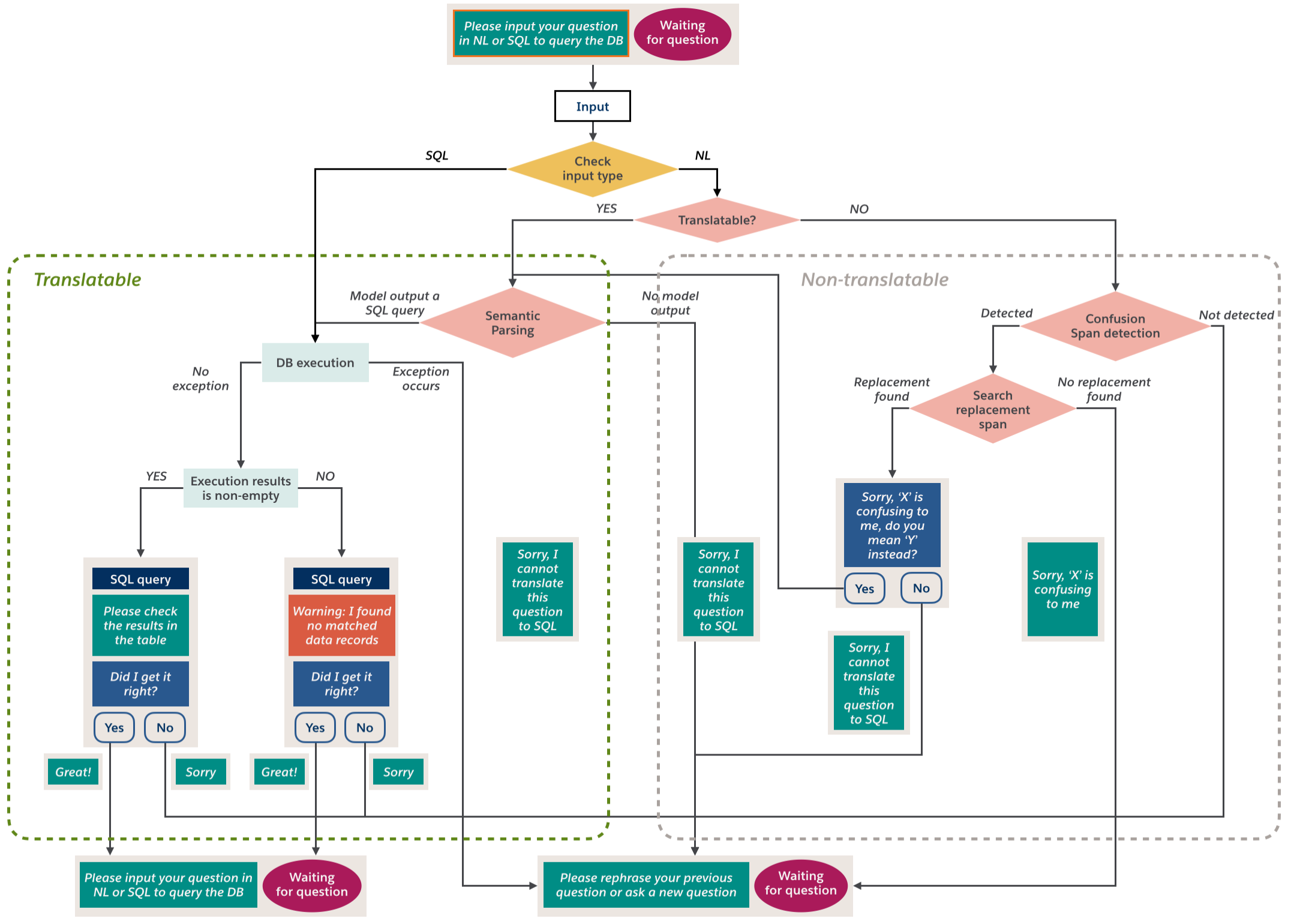
Figure 6 shows the flow diagram of Photon. The confusion detection module determines the translatability of an incoming question. For translatable questions, the semantic parser attempts to parse them into executable SQL queries conditioned on the DB schema. For untranslatable questions, the confusion spans together with the context are fed into the question-correction modules to predict the user's attempted question. The response generation module handles user interaction by confirming a successful translation, soliciting feedback or asking the user to rephrase.
User Feedback
Since its debut in July, thousands of users have interacted with the demo and we received much useful feedback. Check out these two highly engaged LinkedIn posts: link1, link2.
Our demo users are primarily data scientists, analysts, software engineers, students and professors. Many liked our system and expressed strong interests in seeing future iterations. Below we summarize some suggestions and concerns, which may benefit future development of the community.
Trust and Reliability. Deep learning based semantic parsers act as black boxes and their predictions lack interpretability. Moreover, it is difficult for end users to detect mistakes made by the parser when the output is executable and yields results of the same type as the correct interpretation (e.g. flights arriving in SFO vs. flights departing from SFO). Some developers have expressed reluctance to trusting the system output, highlighting the necessity of better explanation for both the generated queries and the process of deriving them.
Self-control. Some users expressed reluctance to losing control of the process of crafting SQL. To quote one of them, "But ... but ... I love the smell of freshly handcrafted SQL in the morning 😁". The dual input mode is one solution we offer to keep programmers in the pilot seats when they like. It is also possible to implement features enabling generating SQL queries with the users interactively, leaving ultimate control to the user.
External Knowledge. Some users pointed out that expressing the goal in English may be challenging in some scenarios, requiring an understanding of the underlying business logic structure. In the future we hope to integrate background knowledge of business logic into the interface, in order to enable more complex functions from simple utterances.
SQL Query Optimization. Some users suggested that such interfaces should be combined with DB design and resource analysis to generate SQL queries that are not only accurate but also optimal. This direction is especially interesting given that businesses increasingly deal with big data.
Conclusion
We introduce Photon, a modular and cross-domain NLIDB that supports most common SQL operations and filters untranslatable utterances. The current Photon system is still a prototype, with limited user interactions and functions. We expect to continue adding more features to Photon, such as voice input, auto-completion, and visualization of the output when appropriate. Given the advances of modern NLP, we believe an era of natural language information systems is just around the corner.
Please cite the following paper if you find our work useful.
Jichuan Zeng*, Xi Victoria Lin*, Caiming Xiong, Richard Socher, Michael R. Lyu, Irwin King, Steven C.H. Hoi. ACL 2020 System Demonstration. Photon: A Robust Cross-Domain Text-to-SQL System. *: Equal Contribution
Additional References
- Li and Jagadish. VLDB 2014. Constructing an Interactive Natural Language Interface for Relational Databases.
- Zhong et al. 2017. Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning.
- Li et al. ACL 2018. Confidence Modeling for Neural Semantic Parsing.
- Yu et al. EMNLP 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task.
- Setlur et al. IUI 2019. Inferencing Underspecified Natural Language Utterances in Visual Analysis.
- Setlur et al. UIST 2020. Sneak Pique: Exploring Autocompletion as a Data Discovery Scaffold for Supporting Visual Analysis.
- Wang et al. ACL 2020. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers.
- Suhr et al. ACL 2020. Exploring Unexplored Generalization Challenges for Cross-Database Semantic Parsing.
- Elgohary et al. ACL 2020. Speak to your Parser: Interactive Text-to-SQL with Natural Language Feedback.
- Yu et al. EMNLP 2019. CoSQL: A Conversational Text-to-SQL Challenge Towards Cross-Domain Natural Language Interfaces to Databases.
- Khani et al. ACL 2016. Unanimous Prediction for 100% Precision with Application to Learning Semantic Mappings.
Acknowledgements
We thank Dragomir Radev and Tao Yu for valuable research discussions; Melvin Gruesbeck for providing consultancy and mockups for frontend design; Andre Esteva, Yingbo Zhou and Nitish Keskar for advice on model serving; Srinath Reddy Meadusani and Lavanya Karanam for support on setting up the server infra; Victor Zhong, Jesse Vig and Wenhao Liu for helpful feedback on this blog post; and members from Salesforce AI Research for piloting the system.