 Blog Home
Blog HomeHow to Talk to Your Database
A vast amount of today’s information is stored in relational databases. These databases provide the foundation of systems such as medical records, financial markets, and electronic commerce. One of the key draws of relational databases is that an user can use a declarative language to describe the intended query instead of writing a collection of function calls. The details of how the query is executed is abstracted away in the implementation details of the database management system, avoiding the need to modify application code due to changes in database organization.
Despite the meteoric rise in the popularity of relational databases, the ability to retrieve information from these databases is limited. This is due, in part, to the need for users to understand powerful but complex structured query languages.
In this work, we provide a natural language interface to relational databases. Through this interface, users communicate directly with databases using natural language as opposed to through structured query languages such as SQL 1. Our work is two-fold: first, we introduce Seq2SQL, a deep neural network for translating natural language questions over a given table schema to corresponding SQL queries. Next, we release WikiSQL, a corpus of 87,000 hand-annotated instances of natural language questions, SQL queries, and SQL tables extracted from HTML tables from the English Wikipedia. WikiSQL is orders of magnitude larger than comparable datasets 2.
Developing a natural language interface for relational databases
The functionality of a simplified natural language interface can be illustrated as follows. Suppose we are given a table and asked a question regarding the content of the table.
| Rnd | Pick | Player | Pos | Nationality | Team | School/club |
|---|---|---|---|---|---|---|
| 1 | 1 | Markelle Fultz | PG | United States | Philadelphia 76ers (from Brooklyn via Boston) | Washington |
| 1 | 2 | Lonzo Ball | PG | United States | Los Angeles Lakers | UCLA |
| 1 | 3 | Jayson Tatum | SF | United States | Boston Celtics (from Sacramento via Philadelphia) | Duke |
| 1 | 4 | Josh Jackson | SF | United States | Phoenix Suns | Kansas |
| 1 | 5 | De’Aaron Fox | PG | United States | Sacramento Kings | Kentucky |
| 1 | 6 | Jonathan Isaac | SF/PF | United States | Orlando Magic | Florida State |
| 1 | 7 | Lauri Markkanen | PF/C | Finland | Minnesota Timberwolves (traded to Chicago Bulls) | Arizona |
Question
Who was drafted with the 3rd pick of the 1st round?
Answer
Jayson Tatum
In this case, to arrive at the correct answer, we look for rows in which the Rnd column is “1” and the Pick column is “3”. Next, we extract the Player from the corresponding rows. To a database, we describe our query via structured query language (SQL) as follows:
SELECT Player from mytable WHERE Rnd = 1 AND Pick = 3We can also ask questions that require aggregation (we are assuming that the table is as given, even though the actual NBA draft is much larger):
| Question | SQL | Answer |
|---|---|---|
| How many players from the United States play PG? | SELECT COUNT Player FROM mytable WHERE Pos = 'PG' AND Nationality = 'United States' | 3 |
| What’s the lowest pick in round 1? | SELECT MIN Pick FROM mytable WHERE Rnd = 1 | 1 |
| Who was drafted before the 3rd pick in round 1? | SELECT Player FROM mytable WHERE Rnd = 1 AND Pick < 3 | Markelle Fultz, Lonzo Ball |
Suppose we would like to develop a machine learning model that produces the corresponding SQL from the given question. Our model would need to make a number of non-trivial inferences such as the following:
- The term “play” corresponds to the column “Pos”, which is short for the player’s position.
- The phrase “lowest pick” corresponds to the minimize operation over the “Pick” column.
- The phrase “before the 3rd pick” corresponds to a “less than” operation over the “Pick column” in this context.
- The only correct column to select is the “Player” column, because the question asks for “who”.
Seq2SQL
We now describe Seq2SQL, an end-to-end deep learning model for translating natural language questions to corresponding SQL queries over a database table. Seq2SQL offers several advantages over traditional attentional sequence to sequence models:
- Seq2SQL takes into account the natural structure of SQL queries, therefore reducing the space of candidate queries.
- The utilisation of an augmented pointer network further reduces the output space of candidate queries and helps the model focus on relevant queries given the question and table schema.
- We train Seq2SQL using policy gradient, a class of reinforcement learning algorithms, to help the model explore the space of queries that are not in the training data. We see later that due to the application of policy gradient, the model is able to produce equivalent queries that are correct but distinct from the ground truth query.
The structure of a SQL query
Most simple SQL queries can be decomposed into three components: an optional aggregation operator, selection columns, and an WHERE clause of conditions. For example, the queries above can be decomposed in the following fashion:
| SQL | Aggregation | Select | Where conditions |
|---|---|---|---|
| SELECT COUNT Player FROM mytable WHERE Pos = 'PG' AND Nationality = 'United States' | COUNT | Player | Pos = 'PG', Nationality = 'United States' |
| SELECT MIN Pick FROM mytable WHERE Rnd = 1 | MIN | Pick | Rnd = 1 |
| SELECT Player FROM mytable WHERE Rnd = 1 AND Pick > 3 | None | Player | Rnd = 1, Pick > 3 |
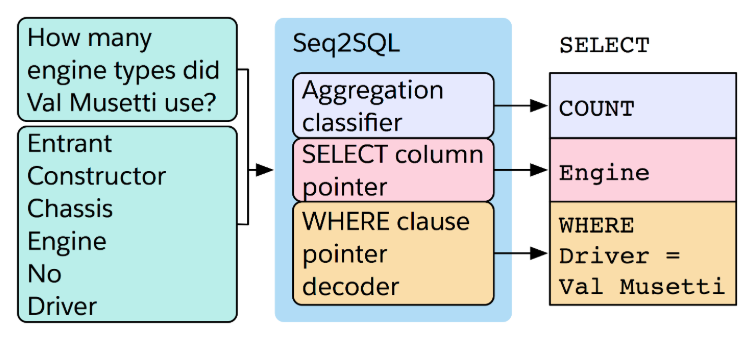
Seq2SQL leverages this inherent structure of SQL queries by first encoding the question and table schema and then predicting each part of the query separately. The diagram below illustrates an particular example.
Here, the question is encoded via a recurrent network. Similarly, each column, which may consist of several words, is encoded via another recurrent network. We use the encodings of the question, in this case “How many …”, to compute the aggregation operation. The question encoding is also used along with the column encodings to compute the column for the selection operation. The WHERE clause of the query is generated using an augmented pointer network whose input is the question sequence, augmented with the table schema and the small set of SQL vocabulary such as AND, >, <, = and so forth.
Augmented Pointer Network
The augmented pointer network deserves special consideration because it differs from popular approaches for sequence to sequence models. The de-facto sequence to sequence model, the attentional sequence to sequence model (Seq2Seq), was arguably popularized by Bahdanau et al.’s work in neural machine translation 3. In the typical machine translation setting, a sentence in the source language is translated by a model one word at a time to a sentence in the target language. Each time the model outputs a word, it considers the input sentence and selects a word from the pool of known words in the target language (referred to as the target vocabulary). One characteristics of Seq2Seq models is that the target vocabulary tends to be large because it needs to encompass all the important words in the target language. Suppose we have \(V\) important words (e.g. we take the \(V\) most common words) and generate a sentence of \(N\) words, the size of the output space is \(V^N\). This number increases exponentially with respect to the sentence length. For a vocabulary of \(50000\) and a sentence length of \(20\), the size of the output space is \(50000^{20} = 9.53 \times 10^{93}\), more than the estimated number of atoms in the universe!
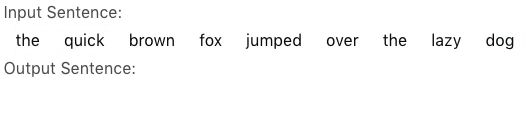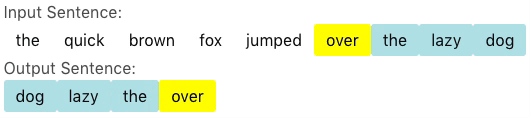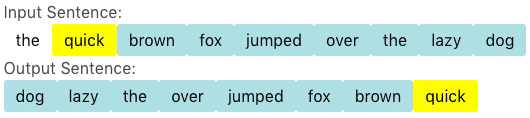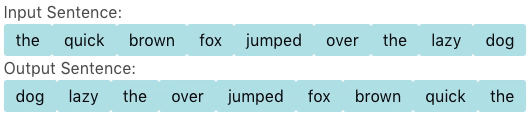
For some problems, however, one can cleverly and drastically reduce the output space of the model. Vinyals et al. describes a class of such problems in which the target sentence is solely comprised of words from the source sentence and proposed the pointer network as a solution to efficiently solve this problem. Instead of selecting a word from the target vocabulary, the pointer network instead selects a words from the source sentence. In most cases, the source sentence contains orders of magnitude less words than the target vocabulary, resulting in a correspondingly orders of magnitude smaller output space. For example, suppose we would like to generate a sentence of length \(20\) from another sentence of length \(20\), the size of the output space is only \(20^{20} = 1.05 \times 10^{26}\); that is to say, roughly \(\frac{1}{10^{67}}\) the size of the output space of the sequence to sequence model.
In our case, we observe that the output SQL query is mostly comprised of words from the question. However, the model must also be able to produce words from the table schema (e.g. column names), since an user can refer to a column by other names (e.g. “round” instead of “Rnd”). We also need to make the model aware of SQL vocabulary such as WHERE, =, AND etc. The resulting model is then an augmented pointer network, in which we augment the question with words from the table columns and the SQL vocabulary. When decoding each word, the model can choose from a word from the question, or a word from the column names, or a word from the SQL vocabulary.
Generating equivalent queries using policy gradient
For SQL queries, it turns out that there are in fact multiple equivalent queries for the same question. Let’s go back to our example queries. For the question “How many players from the United States play PG?”, we need to enforce the two conditions Nationality = 'United States' and Pos = 'PG'. However, the database does not care which condition comes first in the WHERE clause. In this sense, the queries SELECT COUNT Player FROM mytable WHERE Pos = 'PG' AND Nationality = 'United States' and SELECT COUNT Player FROM mytable WHERE Nationality = 'United States' AND Pos = 'PG' are equivalent queries (though the notion of equivalent queries is not limited to different ordering of WHERE clauses).
The existence of equivalent queries present an interesting problem from a modeling standpoint. Normally, sequence models are trained via cross-entropy loss by forcing the model to imitate a ground truth sequence (e.g. the correct target sentence). In our case, since the ground truth query is not necessarily the only solution, using it exclusively to supervise the model is suboptimal because equivalent queries are penalized.
Instead, we apply policy gradient to encourage the model to explore alternative ways of constructing queries that are equivalent to the ground truth query 4 . To supervise the reinforcement learning algorithm, we use a surrogate reward that encourages the model to generate queries that execute to the same result as the ground truth query. Alternatively, if the generated query is invalid or executes to a different results than the ground truth query, the model is penalized. In addition to enabling the model to generate equivalent queries, we observe a consistent improvement in overall performance through the application of policy gradient.
With the inclusion of policy gradient, the training of Seq2SQL is illustrated in the figure below.

Evaluation
The table below shows the performance of Seq2SQL compared to other models on the WikiSQL dataset. The Attentional Seq2Seq model is the conventional sequence to sequence model typically used for machine translation and summarization 5. The Augmented Pointer Network refers to a simplified, unstructured variant of Seq2SQL trained using cross-entropy loss in which the the augmented pointer network generates the entire query, including the aggregation and selection parts. The Seq2SQL (no RL) model refers to a version of Seq2SQL trained purely using cross entropy loss, without policy gradient.
| Model | Test Logical Form Accuracy | Test Execution Accuracy |
|---|---|---|
| Attentional Seq2Seq | 23.4 | 35.9 |
| Augmented Pointer Network | 42.8 | 52.8 |
| Seq2SQL (no RL) | 47.2 | 57.6 |
| Seq2SQL | 49.2 | 60.3 |
Logical form accuracy measures the percentage of examples for which the model produced a query that is identical to the ground truth query. Execution accuracymeasures the percentage of examples for which the model produced a query that, when executed, yields an identical result set as the execution of the ground truth query. Because of the existence of equivalent queries, logical form accuracy provides a lower bound for the real performance of the model whereas execution accuracy provides an upper bound.
As shown in the table, the reduction in output space provided by the augmented pointer network leads to a significant improvement of 16.9% execution accuracy over the traditional attentional sequence to sequence model. Incorporating structure futher improves the performance by 4.8%. Finally, adding policy gradient results in the top performance of 60.3% execution accuracy. For more details about our experiments, such as validation performance, hyperparameter settings, and error analysis, please see our paper.
What was the result of the game played on April 16 with Philadelphia as home team?
SELECT result FROM mytable WHERE home team = philadelphia AND date = april 16Who were the Investing Dragons in the episode that first aired on 18 January 2005 with the entrepreneur Tracey Herrtage?
SELECT investing dragon ( s ) FROM mytable WHERE first aired = 18 january 2005 AND entrepreneur ( s ) = tracey herrtageWho is the incumbent for the Oregon 5 District that was elected in 1996?
SELECT incumbent FROM mytable WHERE first elected = 1996 AND district = oregon 5Examples of queries generated by Seq2SQL.
WikiSQL dataset release
In addition to Seq2SQL, we release WikiSQL, a large, supervised dataset for developing natural language interfaces. WikiSQL consists of examples of SQL table, question, and corresponding SQL query hand-annotated by crowd workers on Amazon Mechanical Turk. Compared to existing datasets, it is orders of magnitude larger - consisting of 87000 examples at the time of this writing. The tables in WikiSQL are originally collected by Bhagavatula et al. and span over English Wikipedia. We generate queries for table and ask crowd workers to paraphrase the query. Each paraphrase is then verified by independent workers to make sure that the paraphrase does not change the meaning of the original query. We hope that the availability of WikiSQL will help the community develop the next generation of natural language interfaces.
More details about WikiSQL, as well as the download link, can be found here.
Citation credit
Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning.
Footnotes
1: The broader research area that this falls under is natural language interfaces (NLI), especially with regards to databases. For more details, please see Androutsopoulos et al, 1995’s work Natural Language Interfaces to Databases - An Introduction.
2: The problem of translating natural language utterances to logical forms is the core problem in the field of semantic parsing. Existing datasets for semantic parsing includes Geoquery, ATIS, Freebase917, Overnight, WebQuestions, and WikiTableQuestions. Comparisons between these datasets and WikiSQL can be found in our paper. Percy Liang provides an excellent overview of the field of semantic parsing in this video.
3: Attentional Sequence to Sequence models was arguably popularized by Bahdanau et al’s paper Neural Machine Translation by Jointly Learning to Align and Translate. Sutskever et al.‘s work Sequence to Sequence Learning with Neural Networks is great resource for learning about sequence to sequence models. Another great resource is Graves’ Generating Sequences With Recurrent Neural Networks. Bryan McCann also provides an overview of the attentional sequence to sequence model in Learned in translation: contextualized word vectors.
4: Policy gradient methods were proposed by Sutton et al. in their work Policy Gradient Methods for Reinforcement Learning with Function Approximation. Schulman et al.’s work Gradient Estimation Using Stochastic Computation Graphs provides an excellent and lucid overview of how to implement policy gradient methods in practice.
5: The attentional sequence to sequence model we use for our baseline is similar to that proposed by Dong et al.’s work Language to Logical Form with Neural Attention, one of the pioneering works on neural semantic parsing.