 Blog Home
Blog HomeSlack your way to QA - How past conversations can answer future questions.

How many emails and working-related conversations do you have every day? The average office worker receives about 121 emails daily and uncountable messages on platforms such as Slack, Team, or iMessage. With the increasing volume of remote work, it can be really difficult to organize or seek information from these conversations. It is time-consuming to go through the whole message to find information. Different people may repeatedly ask similar questions.
Having conversations is one of the most common ways to share knowledge and exchange information. Imagine having a smart assistant that can help you find the most relevant information in large conversations. For example, say you have an email thread with many people discussing a meeting schedule. You post a question directly to the email thread asking “Why IETF meetings create logistics problems?” and the assistant replies “Because meetings tend to become too large.” Or for instance, let’s assume you try to find an answer regarding something your team discussed on Slack the past month such as “What is Salesforce’s revenue in 2020 Q2?” The assistant can search the whole channel and then give you the answer which is “$5.15B, a year-on-year increase of 29%.”
With scenarios like these in mind, we aim to build a question-answering (QA) system that can understand conversations. QA task is one of the popular NLP tasks that people have been working on for decades. However, QA research mainly focuses on document understanding (e.g., Wikipedia) as opposed to conversation understanding. Dialogues have significant differences with documents in terms of data format and wording style. Existing work related to QA and conversational AI focuses on conversational QA instead of QA on conversations. Specifically, conversational QA has sequential dialogue-like QA pairs grounded on a short document paragraph, but what we are more interested in is having QA pairs grounded on conversations, treating past dialogues as a knowledge source.
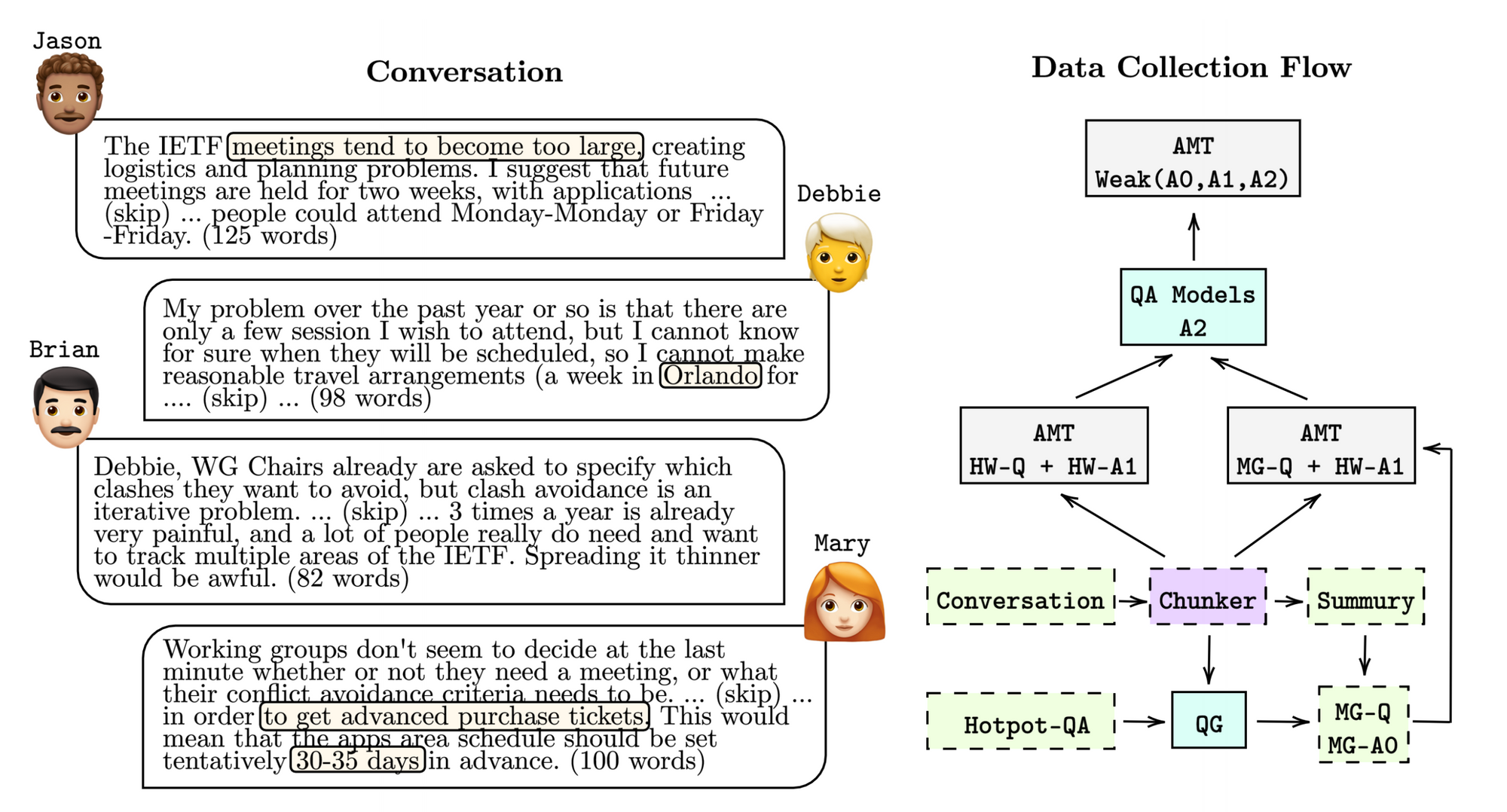
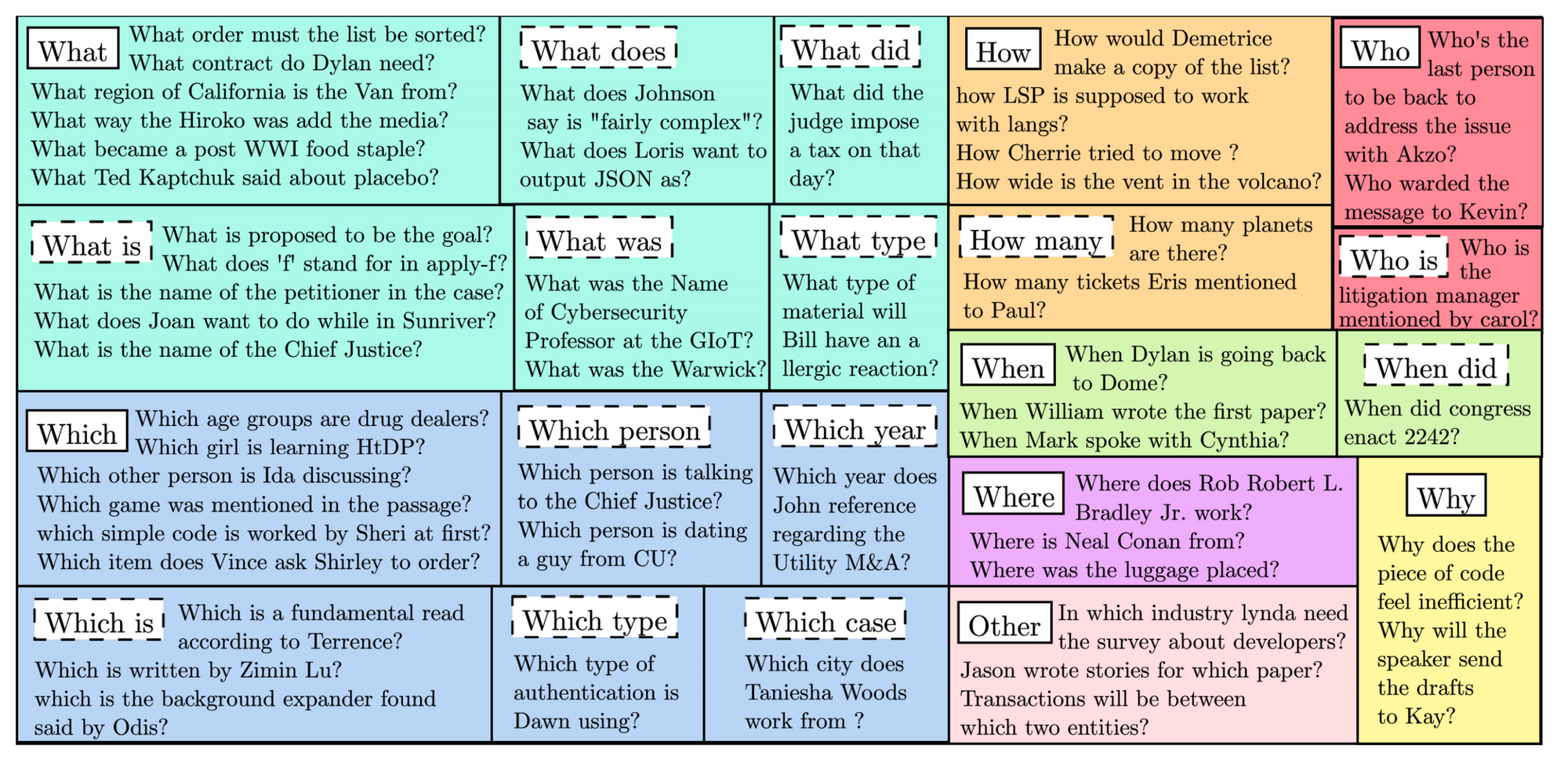
We introduce a new dataset called QAConv: Question Answering on Informative Conversations where we aggregate 10,259 conversations from business email, panel discussion, and working channel. The longest dialogue sample in our data has 19,917 words (or 32 speakers) coming from a long panel discussion. In addition to asking crowd workers to write QA pairs, we use machine learning models to generate multi-hop question candidates that are not that easy to answer. That is, users may need to refer to multiple sentences in a conversation to answer such questions. We show in human evaluation that machine-generated questions are usually longer, more fluent, and more complex.

We also collect unanswerable questions where we ask crowd workers to ask questions that have some mentioned entities but cannot be answered by the given content. For example, if A, B, and C are discussing when they are going to meet but without mentioning the meeting location, the question “Where are A, B, and C going to meet this weekend?” is unanswerable. Predicting questions to be unanswerable could be more difficult than predicting answers, and the “know that I do not know” task is an essential ability for a smart assistant.
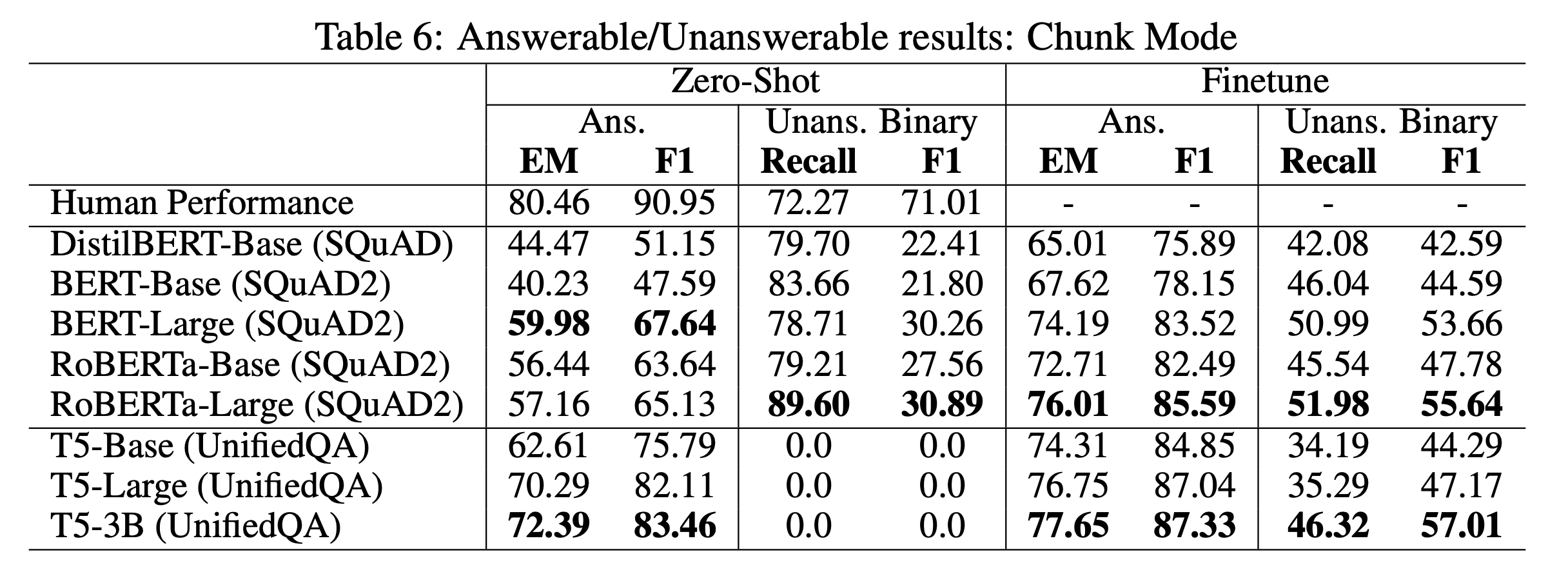
There are two possible scenarios to test QA models, chunk mode and full mode, depending on whether the most relevant conversational piece is given. Since past conversations can be too long to input all at once, we may have to retrieve the most important part first regarding the given question. Thus, the chunk mode is just to test machine reading ability and the full mode is more close to a real use case. We evaluate existing state-of-the-art QA models including the span extraction RoBERTa-Large model trained on SQuAD 2.0 dataset and the generative UnifiedQA model trained on 20 different QA datasets. We investigate the BM25 retriever and the dense passage retriever (DPR) as our conversational retrievers. We show zero-shot (without training any samples from our dataset and directly evaluate on our test set) and fine-tuning (training on our training set first) performances in both modes.
We find that the state-of-the-art UnifiedQA model with 3B parameters can achieve good zero-shot performance in the chunk mode on our dataset, suggesting the effectiveness of knowledge transferring by such a giant language model. However, they cannot answer any unanswerable questions and keep predicting some “answers”. We observe that the RoBERTa model performs poorly on answerable questions. However, it achieves high recall but low F1 on unanswerable questions, implying that it tends to predict our task as unanswerable, revealing the weakness of their dialogue understanding abilities. All baselines in our paper can have significant improvement after finetuning on our training set, which further closes the gap between machine and human performance. Nevertheless, there is still room for improvement, especially under the full mode setting in which all models have over a 20% performance drop.
Our data and baseline code are publicly available on the QAConv Github repository. Please feel free to download and report your results on the leaderboard at our repository. QA on conversations is one of the first steps to show how machines can leverage conversational data as a knowledge source, and there are more challenging yet exciting applications along this research direction.
Interested in learning more about Salesforce Research? Click here to visit our webpage and follow us on Twitter.
Paper: https://arxiv.org/pdf/2105.06912.pdf
Code: https://github.com/salesforce/QAConv
About the Researcher

Chien-Sheng (Jason) Wu is a senior research scientist at Salesforce AI. His research focuses on deep learning applications in natural language processing and conversational AI.