 Blog Home
Blog HomeSFR-Embedding-Mistral: Enhance Text Retrieval with Transfer Learning
TLDR
The SFR-Embedding-Mistral marks a significant advancement in text-embedding models, building upon the solid foundations of E5-mistral-7b-instruct and Mistral-7B-v0.1.
The main takeaways are:
- SFR-Embedding-Mistral ranks top in text embedding performance on the MTEB (average score 67.6, over 56 datasets), achieving state-of-the-art results.
- The model demonstrates a substantial improvement in retrieval performance, leaping from a score of 56.9 for E5-mistral-7b-instruct to an impressive 59.0.
- In clustering tasks, the SFR-Embedding-Mistral model exhibits a notable absolute improvement of +1.4 compared to E5-mistral-7b-instruct.
Model checkpoint: https://huggingface.co/Salesforce/SFR-Embedding-Mistral
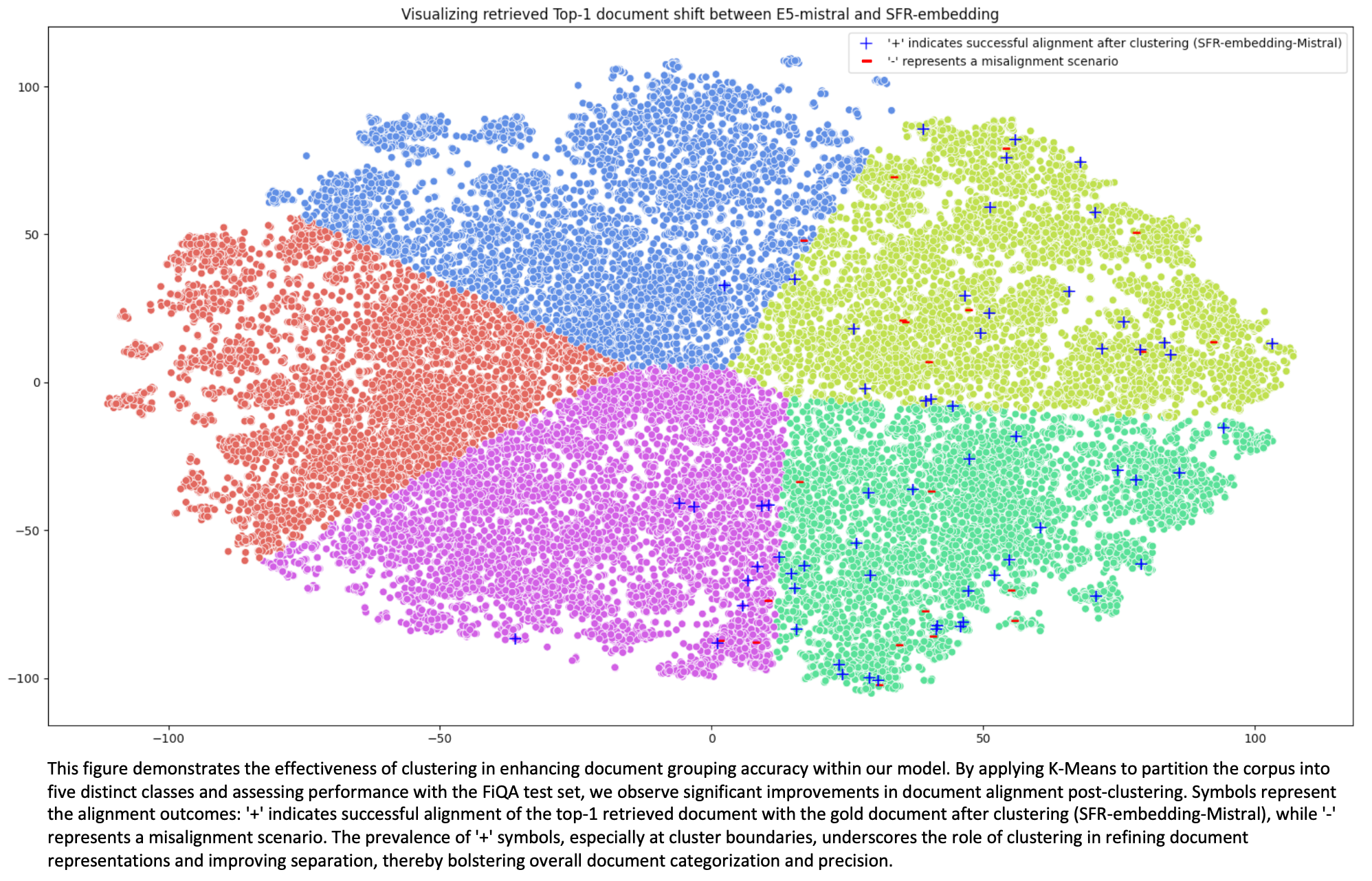
Training Details
The SFR-Embedding-Mistral model is trained on data from a diverse range of tasks. For retrieval tasks, it utilizes data from MS-MARCO, NQ, FiQA, SciFact, NFCorpus, DBPedia, FEVER, HotpotQA, Quora and NLI. Clustering tasks use data from arXiv, bioRxiv , and medRxiv, applying filters to exclude development and testing sets in the MTEB clustering framework. The model utilizes datasets from AmazonReview, Emotion, MTOPIntent, ToxicConversation , and TweetSentiment for classification. In the realm of Semantic Textual Similarity (STS), it is trained on STS12, STS22 , and STSBenchmark, while for reranking tasks, it uses data from SciDocs and StackOverFlowDupQuestions. We employ contrastive loss, utilizing in-batch negatives alongside expectational clustering and classification tasks. We treat the labels as documents for these specific tasks and apply contrastive loss exclusively to their respective negatives, omitting in-batch negatives. Our experiments in the following report results on the dev set of the MTEB benchmark.
We conduct fine-tuning of the e5-mistral-7b-instruct model using a batch size of 2,048, a learning rate of 1e−5, and a warmup phase of 100 steps followed by a linear decay. Each query-document pair is batched with 7 hard negatives. We employ a maximum sequence length of 128 for queries and 256 for documents. This fine-tuning process took approximately 15 hours on 8 A100 GPUs. LoRA adapters with rank r=8 are added to all linear layers, resulting in 21M trainable parameters. Our implementation is based on the HuggingFace PEFT library at https://github.com/huggingface/peft.
Multi-task Training Benefits Generalization
We have observed that embedding models experience a substantial enhancement in retrieval performance when integrated with clustering tasks, and their effectiveness can be further improved through knowledge transfer from multiple tasks. By explicitly guiding documents towards high-level tags, training with clustering data enables embedding models to navigate and retrieve information more effectively. While all three clustering datasets originate from the scientific domain, incorporating additional clustering training yields significant improvements across all tasks. We hypothesize that the clustering labels encourage models to regularize the embeddings based on high-level concepts, resulting in better separation of data across different domains.
Moreover, generalization can be strengthened by employing multi-task training and adapting the models to specific tasks. This approach not only improves the accuracy of search results but also ensures the adaptability of models to diverse domains and tasks, which is crucial for real-world application scenarios.
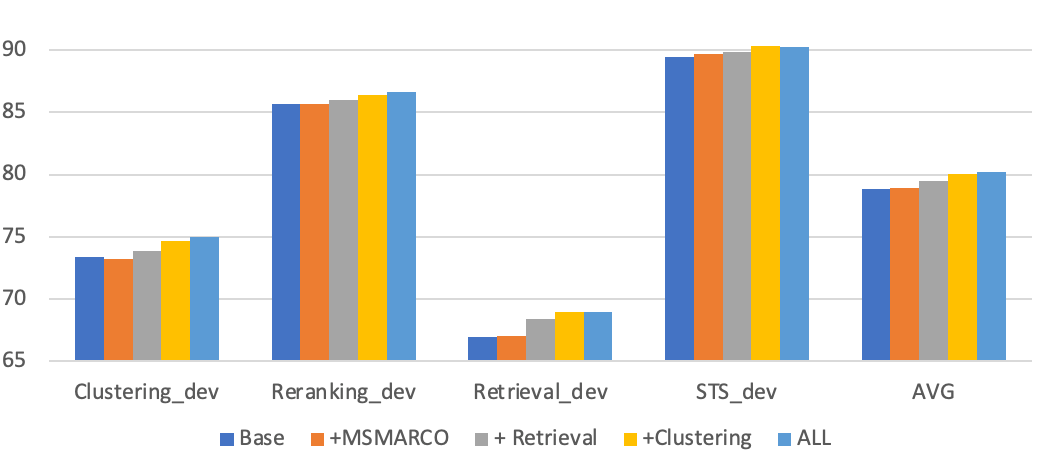
Task-Homogenous Batching
Task-homogeneous batching is another factor contributing to the performance of our models. This technique constructs batches consisting exclusively of samples from a single task. Consequently, the in-batch negative becomes more challenging as other examples within the batch closely resemble the test case scenario. Experimental results highlight a notable enhancement in retrieval tasks with task-homogeneous batching, particularly an increase of 0.8 points.
Interleaved Batching | Off | On |
Clustering_dev | 75.29 | 75.04 |
Reranking_dev | 86.57 | 86.54 |
Retrieval_dev | 68.2 | 69.02 |
STS_dev | 89.81 | 90.3 |
AVG | 79.97 | 80.23 |
Impact of Hard Negatives
An effective technique for training embedding models is using “hard negatives” - data points that are challenging for the models to distinguish from the positive ones. By default, we use the BGE-base model to mine the hard negatives.
Strategy to Eliminate False Negatives
Upon inspecting the mined negatives, a considerable portion appear to be false negatives, meaning they are semantically identical to the corresponding positive documents but mistakenly treated as negatives. A strategy to accurately and efficiently select hard negatives is crucial for embedding training, as it aids models in identifying the most relevant documents to a query.
The results indicate that the range from 30 to 100 yields improved performance. This implies that the top-ranked documents (0-100) may include some false negatives, while those ranked lower (50-100) lack sufficient challenge. Therefore, finding the right tradeoff between these factors is important in contrastive training.
Range of Selecting Negatives | 0-100 | 30-100 | 50-100 |
Clustering_dev | 74.6 | 75.04 | 74.91 |
Reranking_dev | 86.57 | 86.54 | 86.45 |
Retrieval_dev | 68.99 | 69.02 | 69 |
STS_dev | 90.17 | 90.3 | 90.24 |
AVG | 80.08 | 80.225 | 80.15 |
Number of Hard Negatives
The quantity of hard negatives used in contrastive learning can significantly impact the model's learning dynamics. Including more hard negative prompts enables the model to differentiate more subtle distinctions, potentially enhancing its generalization capabilities. Nevertheless, our findings suggest that the training process remains relatively stable regardless of the number of hard negatives utilized.
Number of Negative | #HN=1 | #HN=7 | #HN=15 | #HN=31 |
Clustering_dev | 74.96 | 75.04 | 75.11 | 75.07 |
Reranking_dev | 86.61 | 86.54 | 86.43 | 86.45 |
Retrieval_dev | 68.96 | 69.02 | 68.96 | 68.95 |
STS_dev | 90.26 | 90.3 | 90.21 | 90.17 |
AVG | 80.2 | 80.225 | 80.18 | 80.16 |
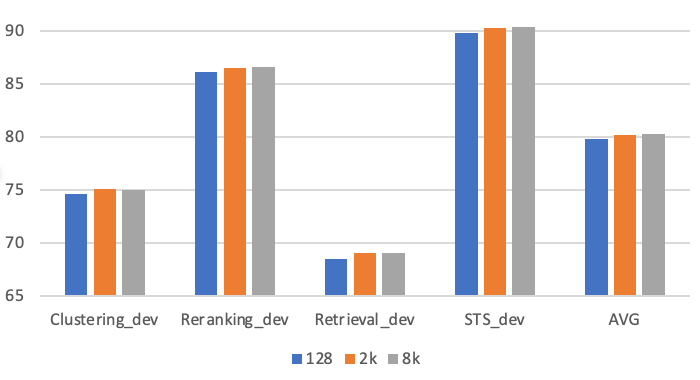
Impact of Batch Size
Leveraging larger batch sizes has proven advantageous, primarily due to the inclusion of more challenging negative examples. We leverage GradCache to facilitate training with large batch sizes. We conducted experiments with batch sizes of 128, 2,048, and 8,192 to assess the impact of batch size. Leveraging larger batch sizes (2K+) leads to considerable improvement compared to the smaller batch sizes (e.g., 128) conventionally used for fine-tuning. However, enlarging the batch size from 2048 to 8192 does not result in any significant change in performance.
Teacher models for hard negative mining
It is customary to utilize more advanced models to collect challenging hard negatives. In our study, we employ four models to investigate the impact of teacher models on mining hard negatives, spanning from the classic lexical model BM25 to advanced dense models, such as our SFR-Embedding-Mistral. The findings indicate that the selected dense models serve as superior teacher models compared to BM25, and in general, more powerful models can yield more effective hard negatives (SFR-Embedding-Mistral > E5-Mistral > BGE-base). In the future, it will be intriguing to explore the impact of multi-round training on two fronts: (a) hard negative (HN) mining with SFR-Embedding-Mistral, and (b) utilizing the identified HNs to refine and improve SFR-Embedding-Mistral.
Hard Negative Mining | BM25 | BGE-base | E5-mistral | SFR-Embedding-Mistral |
| Clustering_dev | 75.07 | 75.04 | 75.04 | 75.45 |
| Reranking_dev | 86.43 | 86.54 | 86.52 | 86.6 |
| Retrieval_dev | 68.42 | 69.02 | 69.06 | 69.15 |
| STS_dev | 90.11 | 90.3 | 90.3 | 90.24 |
| AVG | 80.01 | 80.23 | 80.23 | 80.36 |
Impact of Context Length
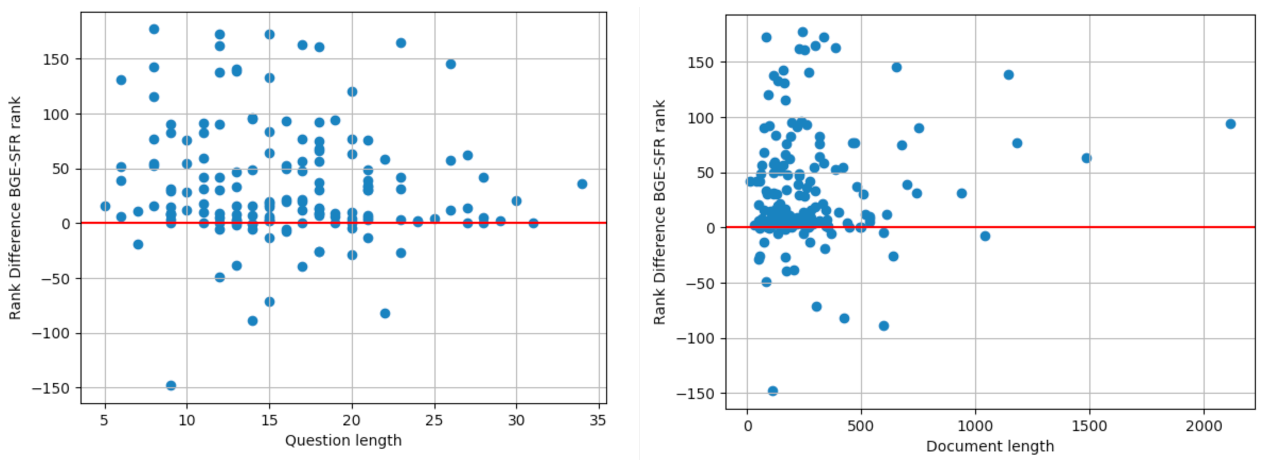
We showcase the difference in ranking of the positive documents for the BGE-large and our SFR-Embedding-Mistral model in relation to the length of the query/question (left figure) and the length of the document (right figure). More precisely, the y-axis captures the rank(gold-document | BGE-large) - rank(gold-document | SFR-Embedding-Mistral), meaning the higher the absolute value, the more contrast between the two models. In both figures, SFR-Embedding-Mistral model ranks positive documents better than the BGE model overall. More importantly, we observe that after a certain length threshold, i.e., 25 for queries and 700 for documents, BGE model is significantly less likely to rank the gold document higher than SFR-Embedding-Mistral owing to the inherent power of LLMs to represent long-context. It becomes particularly appealing for downstream RAG applications where keeping the document structure intact is indispensable. For example, the RAG system maintains the structure of long legal documents during summarization by understanding and retrieving various sections, ensuring the summary accurately captures the case's essence and legal reasoning, which is vital for legal contexts.
Full Evaluation on MTEB
MTEB (Massive Text Embedding Benchmark) is by far the most comprehensive benchmark for evaluating embedding models, encompassing 56 datasets across seven task types: seven tasks: classification, clustering, pair classification, re-ranking, retrieval, STS, and summarization.
As evidenced by the MTEB leaderboard (as of February 27, 2024), SFR-Embedding-Mistral claims the top spot among over 150 embedding models, including several proprietary ones such as voyage-lite-02-instruct, OpenAI text-embedding-3-large, and Cohere-embed-english-v3.0. Particularly noteworthy is its performance on retrieval tasks, which are considered the most pivotal among all MTEB task types. SFR-Embedding-Mistral excels with an average score of 59.0, surpassing the 2nd place model by a substantial margin (57.4). This outcome underscores the exceptional performance of our model across diverse tasks and domains.
| MTEB Rank (by Feb 27, 2024) | Model | Average (56 datasets) | Retrieval (15 datasets) | Classification (12 datasets) | Clustering (11 datasets) | Pair Classification (3 datasets) | Reranking (4 datasets) | STS (10 datasets) | Summarization (1 dataset) |
| 1 | SFR-Embedding-Mistral | 67.6 | 59.0 | 78.3 | 51.7 | 88.5 | 60.6 | 85.1 | 31.2 |
| 2 | voyage-lite-02-instruct | 67.1 | 56.6 | 79.3 | 52.4 | 86.9 | 58.2 | 85.8 | 31.0 |
| 3 | GritLM-7B | 66.8 | 57.4 | 79.5 | 50.6 | 87.2 | 60.5 | 83.4 | 30.4 |
| 4 | e5-mistral-7b-instruct | 66.6 | 56.9 | 78.5 | 50.3 | 88.3 | 60.2 | 84.6 | 31.4 |
| 5 | GritLM-8x7B | 65.7 | 55.1 | 78.5 | 50.1 | 85.0 | 59.8 | 83.3 | 29.8 |
| 8 | text-embedding-3-large | 64.6 | 55.4 | 75.5 | 49.0 | 85.7 | 59.2 | 81.7 | 29.9 |
| 10 | Cohere-embed-english-v3.0 | 64.5 | 55.0 | 76.5 | 47.4 | 85.8 | 58.0 | 82.6 | 30.2 |
| 13 | bge-large-en-v1.5 | 64.2 | 54.3 | 76.0 | 46.1 | 87.1 | 60.0 | 83.1 | 31.6 |
Conclusion
SFR-Embedding-Mistral is the top-ranked model on the MTEB benchmark, attributed to several pivotal innovations and strategies:
- Transfer learning from multiple tasks, notably clustering, enhances the model's adaptability and performance.
- Task-homogeneous batching increases the difficulty of the contrastive objective for the model, promoting enhanced generalization.
- Constructing better hard negatives further sharpens the model’s ability to discern discriminating misleading documents.