 Blog Home
Blog Home
The 58th Association for Computational Linguistics (ACL) Conference kicked off this week and runs from Sunday, Jul 5 to Friday, Jul 10 in a fully virtual format. ACL is the premier conference of the field of computational linguistics, covering a broad spectrum of diverse research areas that are concerned with computational approaches to natural language (ACL 2020 Website).
The accepted papers below will be presented by members of our team through prerecorded talks and slides during the main conference July 6 – 8, 2020. Questions and comments about this work can be discussed using the online ACL forum, through twitter accounts of the authors or by emailing us at salesforceresearch@salesforce.com. We look forward to sharing some of our exciting new research with you this week!
Our publications at ACL 2020
ESPRIT: Explaining Solutions to Physical ReasonIng Tasks
Nazneen Fatema Rajani, Rui Zhang, Yi Chern Tan, Stephan Zheng, Jeremy Weiss, Aadit Vyas, Abhijit Gupta, Caiming Xiong, Richard Socher and Dragomir Radev
Neural networks lack the ability to reason about qualitative physics and so cannot generalize to scenarios and tasks unseen during training. We propose ESPRIT, a framework for commonsense reasoning about qualitative physics in natural language that generates interpretable descriptions of physical events. We use a two-step approach of first identifying the pivotal physical events in an environment and then generating natural language descriptions of those events using a data-to-text approach. Our framework learns to generate explanations of how the physical simulation will causally evolve so that an agent or a human can easily reason about a solution using those interpretable descriptions. Human evaluations indicate that ESPRIT produces crucial fine-grained details and has high coverage of physical concepts compared to even human annotations.
Blog
GitHub
ERASER: A Benchmark to Evaluate Rationalized NLP Models
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher and Byron C. Wallace
State-of-the-art models in NLP are now predominantly based on deep neural networks that are opaque in terms of how they come to make predictions. This limitation has increased interest in designing more interpretable deep models for NLP that reveal the `reasoning' behind model outputs. But work in this direction has been conducted on different datasets and tasks with correspondingly unique aims and metrics; this makes it difficult to track progress. We propose the Evaluating Rationales And Simple English Reasoning (ERASER) benchmark to advance research on interpretable models in NLP. This benchmark comprises multiple datasets and tasks for which human annotations of "rationales" (supporting evidence) have been collected. We propose several metrics that aim to capture how well the rationales provided by models align with human rationales, and also how faithful these rationales are (i.e., the degree to which provided rationales influenced the corresponding predictions). Our hope is that releasing this benchmark facilitates progress on designing more interpretable NLP systems.
Code
Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
Tianlu Wang, Xi Victoria Lin, Nazneen Fatema Rajani, Bryan McCann, Vicente Ordonez and Caiming Xiong
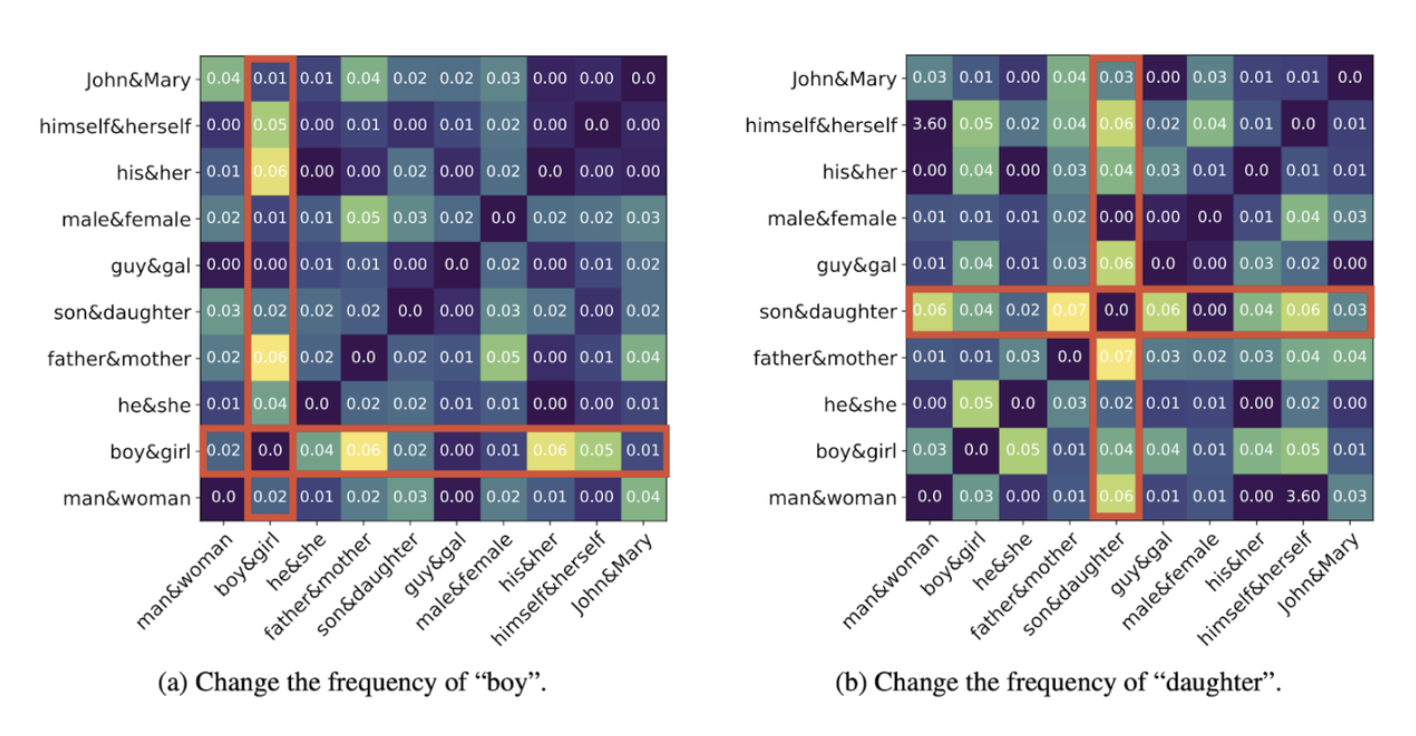
Word embeddings derived from human-generated corpora inherit strong gender bias which can be further amplified by downstream models. Some commonly adopted debiasing approaches, including the seminal Hard Debias algorithm, apply post-processing procedures that project pre-trained word embeddings into a subspace orthogonal to an inferred gender subspace. We discover that semantic-agnostic corpus regularities such as word frequency captured by the word embeddings negatively impact the performance of these algorithms. We propose a simple but effective technique, Double Hard Debias, which purifies the word embeddings against such corpus regularities prior to inferring and removing the gender subspace. Experiments on three bias mitigation benchmarks show that our approach preserves the distributional semantics of the pre-trained word embeddings while reducing gender bias to a significantly larger degree than prior approaches.
Blog
EMT: Explicit Memory Tracker with Coarse-to-Fine Reasoning for Conversational Machine Reading
Yifan Gao, Chien-Sheng Wu, Shafiq Joty, Caiming Xiong, Richard Socher, Irwin King, Michael Lyu and Steven C.H. Hoi
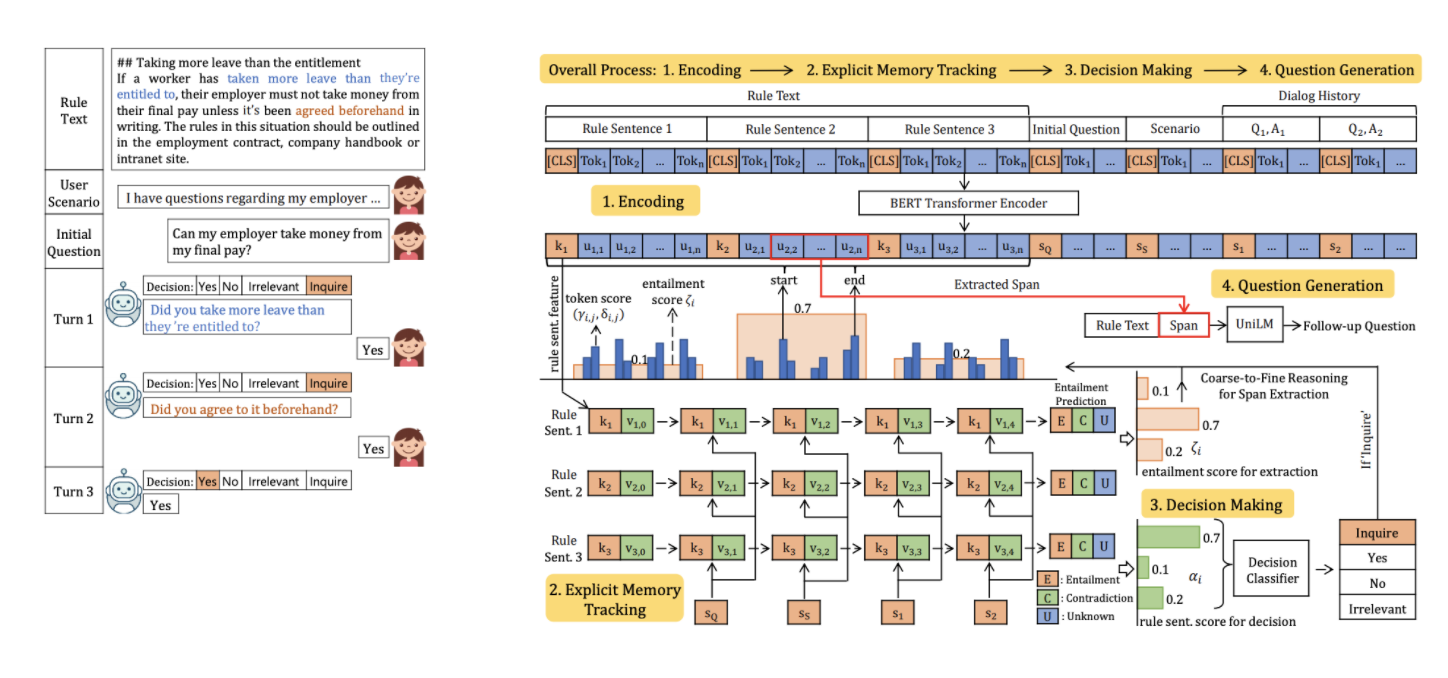
The goal of conversational machine reading is to answer user questions given a knowledge base text which may require asking clarification questions. Existing approaches are limited in their decision making due to struggles in extracting question-related rules and reasoning about them. In this paper, we present a new framework of conversational machine reading that comprises a novel Explicit Memory Tracker (EMT) to track whether conditions listed in the rule text have already been satisfied to make a decision. Moreover, our framework generates clarification questions by adopting a coarse-to-fine reasoning strategy, utilizing sentence-level entailment scores to weight token-level distributions. On the ShARC benchmark (blind, held-out) test set, EMT achieves new state-of-the-art results of 74.6% micro-averaged decision accuracy and 49.5 BLEU4. We also show that EMT is more interpretable by visualizing the entailment-oriented reasoning process as the conversation flows.
GitHub
It’s Morphin’ Time! Combating Linguistic Discrimination with Inflectional Perturbations
Samson Tan, Shafiq Joty, Min-Yen Kan and Richard Socher
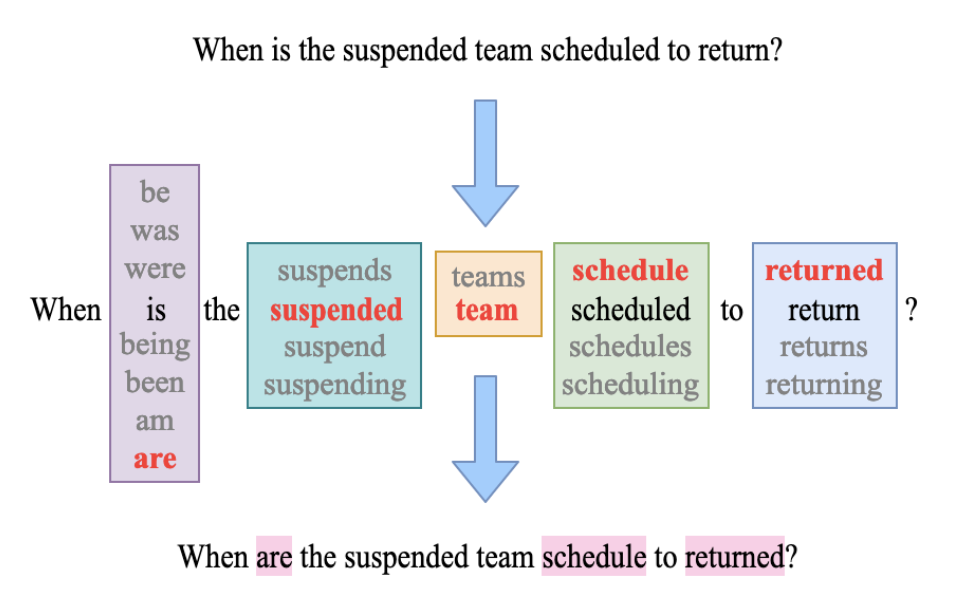
Training on only error-free Standard English corpora predisposes pretrained neural networks to discriminate against minorities from non-standard linguistic backgrounds (e.g., African American Vernacular English, Colloquial Singapore English, etc.). We perturb the inflectional morphology of words to craft plausible and semantically similar adversarial examples that expose these biases in popular NLP models, e.g., BERT and Transformer, and show that adversarially fine-tuning them for a single epoch significantly improves robustness without sacrificing performance on clean data.
Video-Grounded Dialogues through Pretrained Language Models with Spatio-Temporal Reasoning
Hung Le and Steven C.H. Hoi
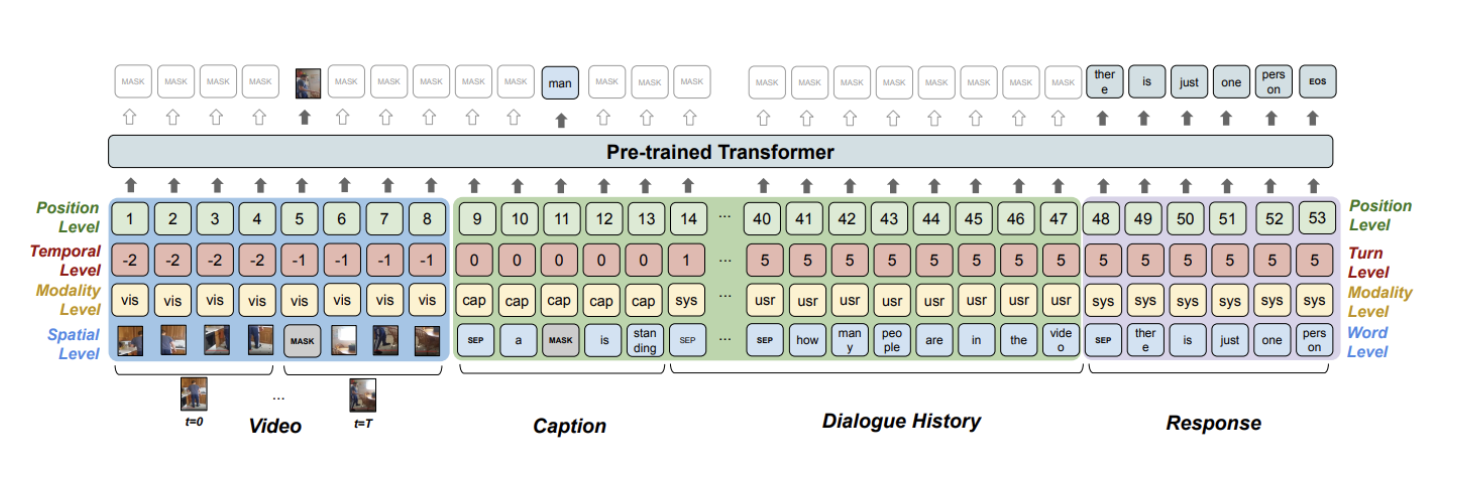
Pre-trained language models have shown remarkable success in improving various downstream NLP tasks due to their ability to capture dependencies in textual data and generate natural responses. In this paper, we leverage the power of pre-trained language models for improving video-grounded dialogue, which is very challenging and involves complex features of different dynamics: (1) Video features which can extend across both spatial and temporal dimensions; and (2) Dialogue features which involve semantic dependencies over multiple dialogue turns. We propose a framework by extending GPT-2 models to tackle these challenges by formulating video-grounded dialogue tasks as a sequence-to-sequence task, combining both visual and textual representation into a structured sequence, and fine-tuning a large pre-trained GPT-2 network. Our framework allows fine-tuning language models to capture dependencies across multiple modalities over different levels of information: spatio-temporal level in video and token-sentence level in dialogue context. We achieve promising improvement on the Audio-Visual Scene-Aware Dialogues (AVSD) benchmark from DSTC7, which supports a potential direction in this line of research.
Photon: A Robust Cross-Domain Text-to-SQL System
Jichuan Zeng, Xi Victoria Lin, Michael R. Lyu, Irwin King, Caiming Xiong, Richard Socher, and Steven C.H. Hoi
Natural language interfaces to databases(NLIDB) democratize end user access to relational data. Due to fundamental differences between natural language communication and programming, it is common for end users to issue questions that are ambiguous to the system or fall outside the semantic scope of its underlying query language. We present PHOTON, a robust, modular, cross-domain NLIDB that can flag natural language input to which a SQL mapping cannot be immediately determined. PHOTON consists of a strong neural semantic parser (63.2% structure accuracy on the Spider dev benchmark), a human-in-the-loop question corrector, a SQL executor and a response generator. The question corrector isa discriminative neural sequence editor which detects confusion span(s) in the input question and suggests rephrasing until a translatable input is given by the user or a maximum number of iterations are conducted. Experiments on simulated data show that the proposed method effectively improves the robustness of text-to-SQL system against untranslatable user input.
Live Demo
Efficient Constituency Parsing by Pointing
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li
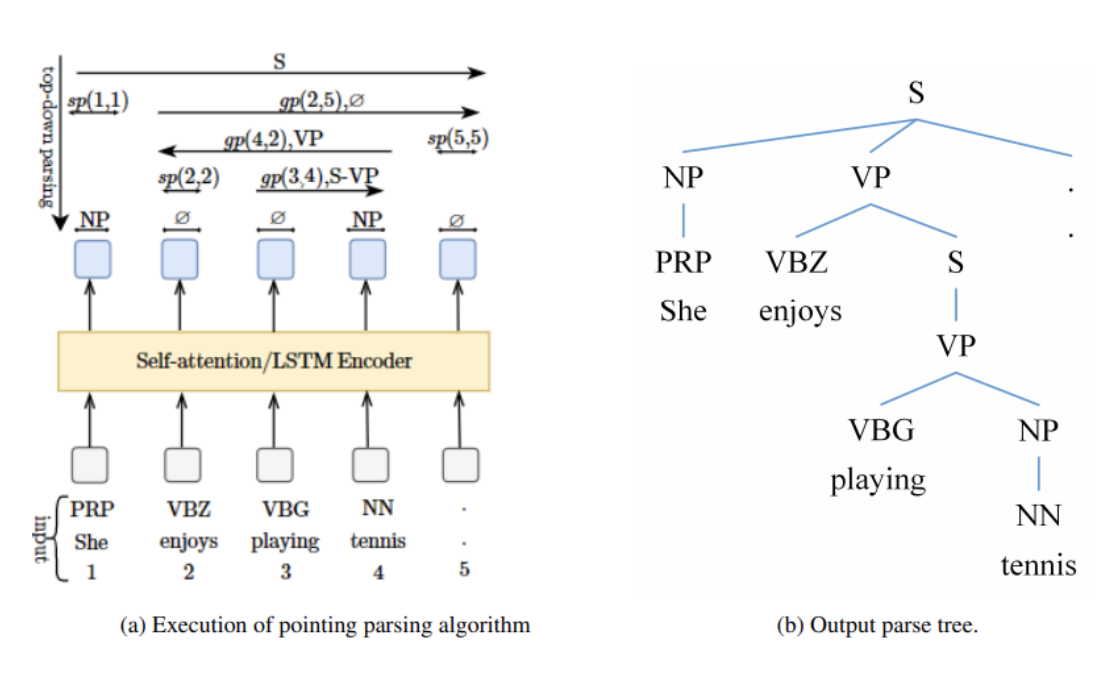
We propose a novel constituency parsing model that casts the parsing problem into a series of pointing tasks. Specifically, our model estimates the likelihood of a span being a legitimate tree constituent via the pointing score corresponding to the boundary words of the span. Our parsing model supports efficient top-down decoding and our learning objective is able to enforce structural consistency without resorting to the expensive CKY inference. The experiments on the standard English Penn Treebank parsing task show that our method achieves 92.78 F1 without using pre-trained models, which is higher than all the existing methods with similar time complexity. Using pre-trained BERT, our model achieves 95.48 F1, which is competitive with the state-of-the-art while being faster. Our approach also establishes new state-of-the-art in Basque and Swedish in the SPMRL shared tasks on multilingual constituency parsing.
Differentiable Window for Dynamic Local Attention
Thanh-Tung Nguyen, Xuan-Phi Nguyen, Shafiq Joty, and Xiaoli Li
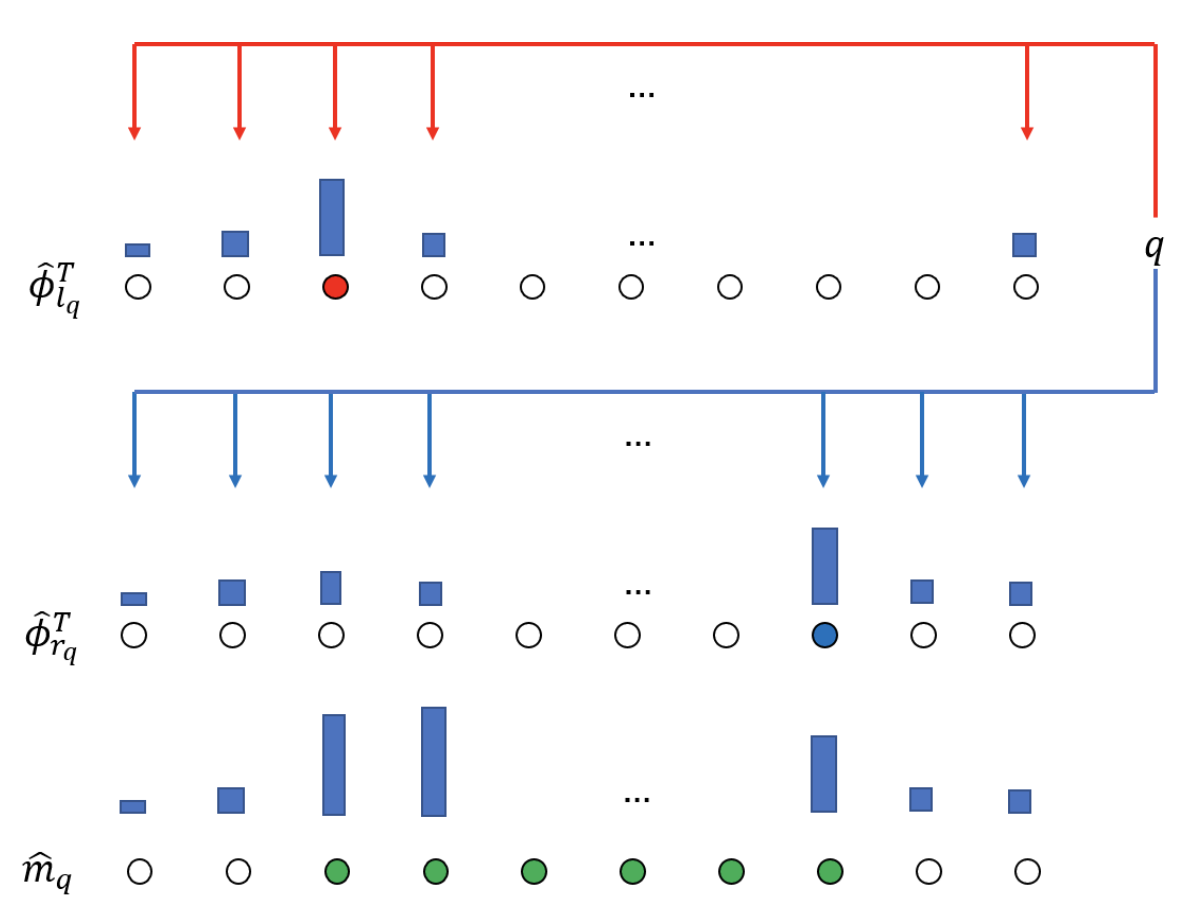
We propose Differentiable Window, a new neural module and general purpose component for dynamic window selection. While universally applicable, we demonstrate a compelling use case of utilizing Differentiable Window to improve standard attention modules by enabling more focused attentions over the input regions. We propose two variants of Differentiable Window, and integrate them within the Transformer architecture in two novel ways. We evaluate our proposed approach on a myriad of NLP tasks, including machine translation, sentiment analysis, subject-verb agreement and language modeling. Our experimental results demonstrate consistent and sizable improvements across all tasks.