 Blog Home
Blog HomeExplaining Solutions to Physical Reasoning Tasks
TL;DR: We show that deep neural models can describe common sense physics in a valid and sufficient way that is also generalizable. Our ESPRIT framework is trained on a new dataset with physics simulations and descriptions that we collected and have open-sourced.
Our paper has been accepted at ACL 2020. If you use our work, please cite our paper ESPRIT.
We humans are good at reasoning about the physical world using common sense knowledge, also known as qualitative physics reasoning. For example, we know that ice makes things slippery to walk on, that an object thrown up will come down due to gravity, and that an object pushed off a table traces a projectile path. We can also reasonably predict where that object will land. Neural networks lack this ability and are unable to reason about common sense qualitative physics.
In this joint work between Salesforce and Yale University, we propose an interpretable framework that represents complex physical interactions using low dimensional natural language representations. This could make it easier for neural networks to learn to reason about commonsense physical concepts such as gravity, friction, and collision. To equip AI systems with this ability, we collected a set of open-ended natural language human explanations of stylized physics simulations. The explanations included descriptions of the initial scene, i.e., before any time has passed, and a sequence of identified pivotal events in the simulated physical evolution of the system.
The resulting Explaining Solutions to Physical ReasonIng Tasks (ESPRIT) framework unifies commonsense physical reasoning and interpretability using natural language explanations. It consists of two phases:
- identifying the pivotal physical events in tasks, and
- generating natural language descriptions for the initial scene and the pivotal events.
In the first phase, our model learns to classify key physical events that are crucial to achieving a specified goal, whereas in the second phase, our model generates natural language descriptions of physical laws for the events selected in the first phase.
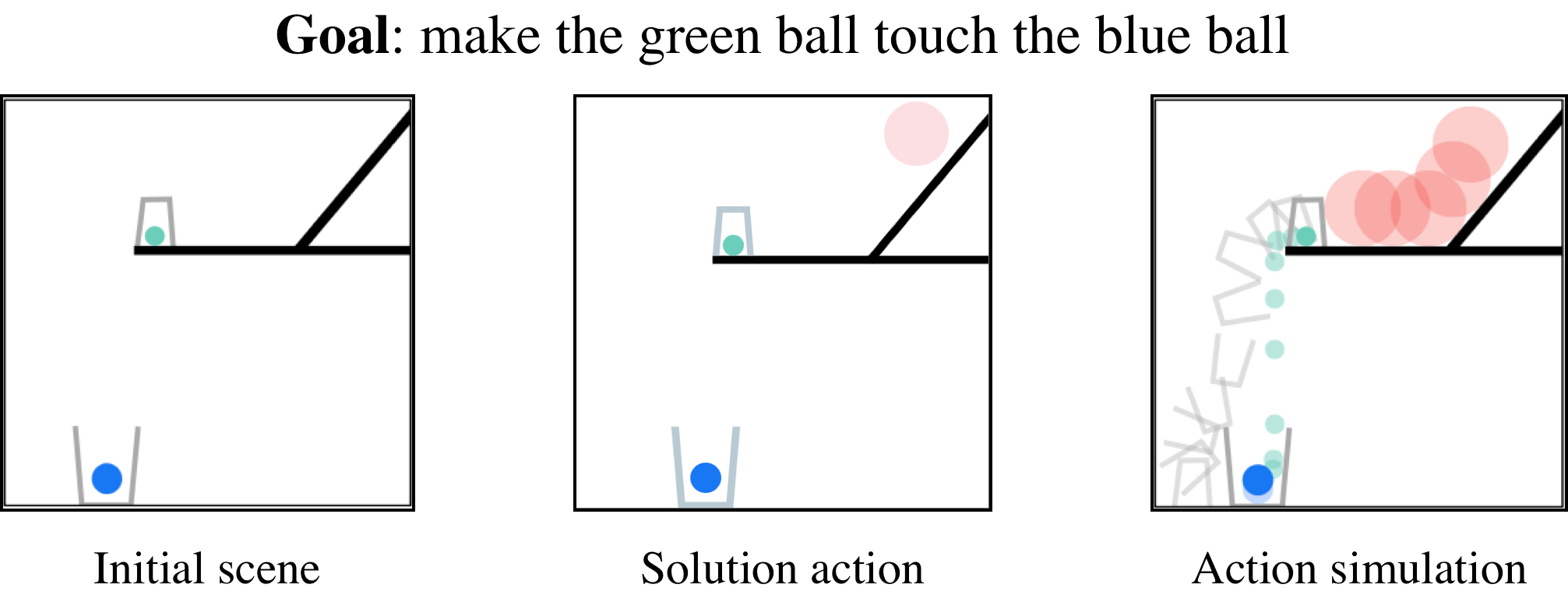
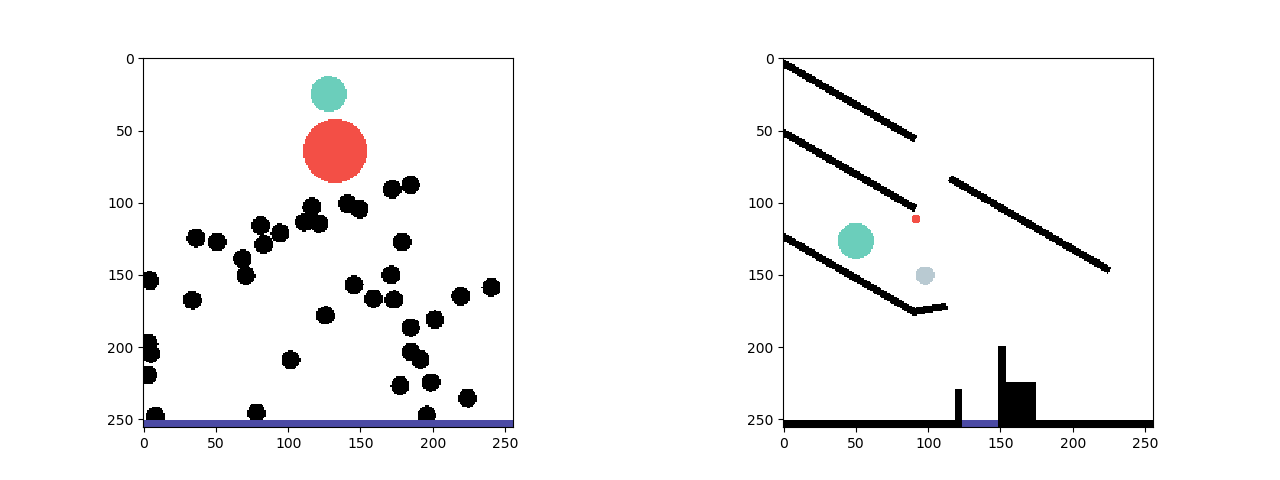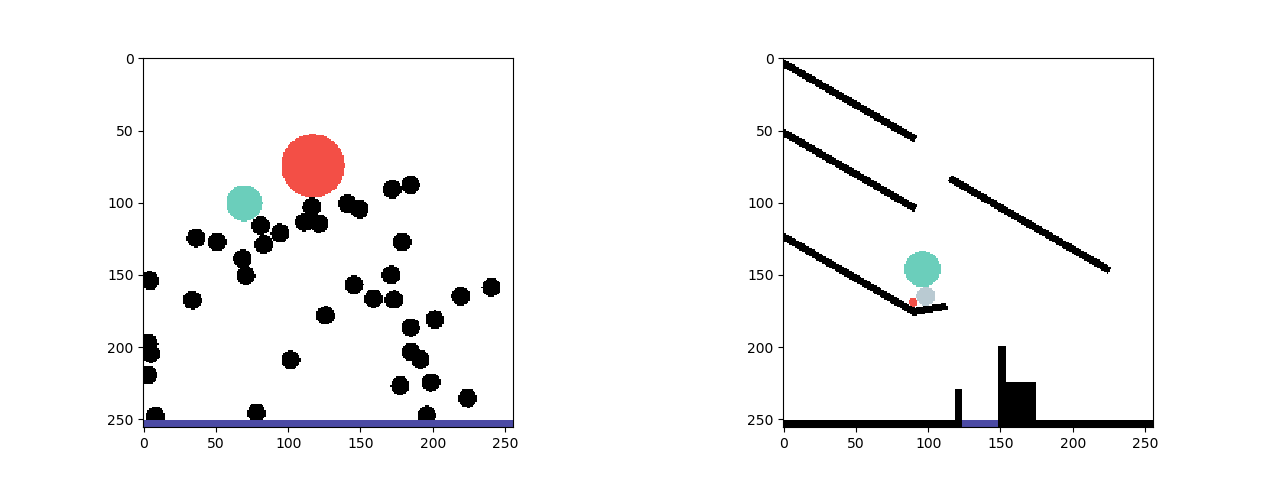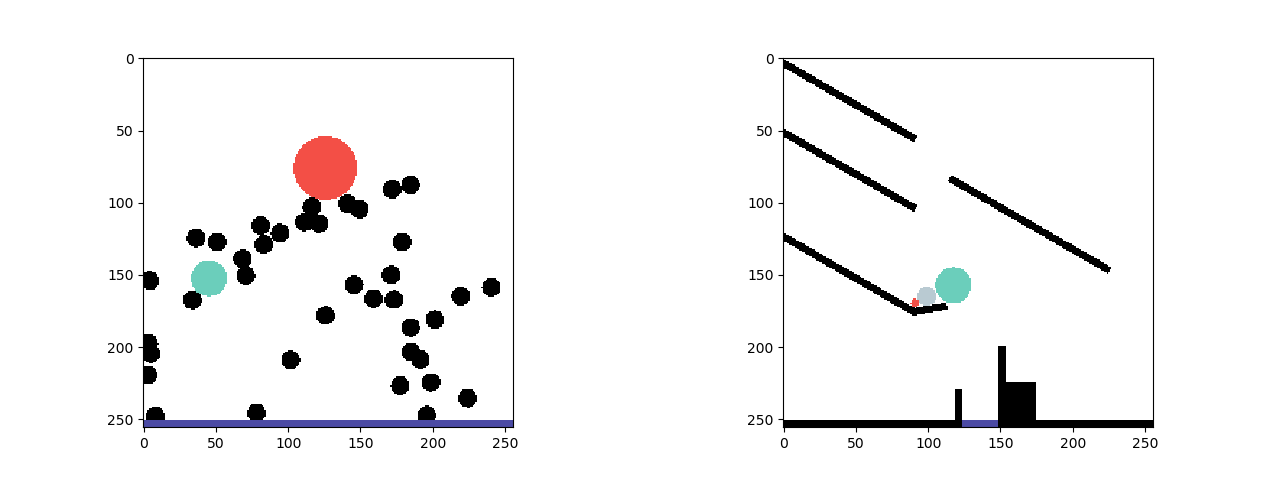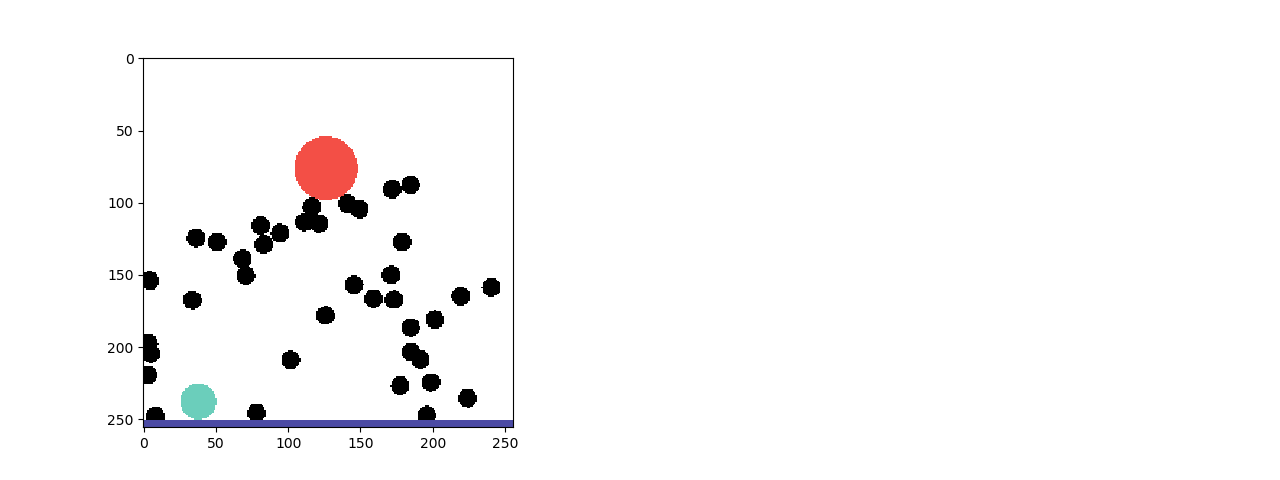
We show the effectiveness of ESPRIT on the PHYsical REasoning (PHYRE) benchmark (Bakhtin et al., 2019). PHYRE provides a set of physics simulation puzzles where each puzzle has an initial state and a goal state. The task is to predict the action of placing one or two bodies (specifically, red balls of variable positions and diameters) in the simulator to achieve a given goal. The figure above shows an example of a task with a specified goal.
The input to ESPRIT is a sequence of frames from a physics simulation. The output is a natural language narrative that reflects the locations of the objects in the initial scene and a description of the sequence of physical events that would lead to the desired goal state, as shown in the figure below.
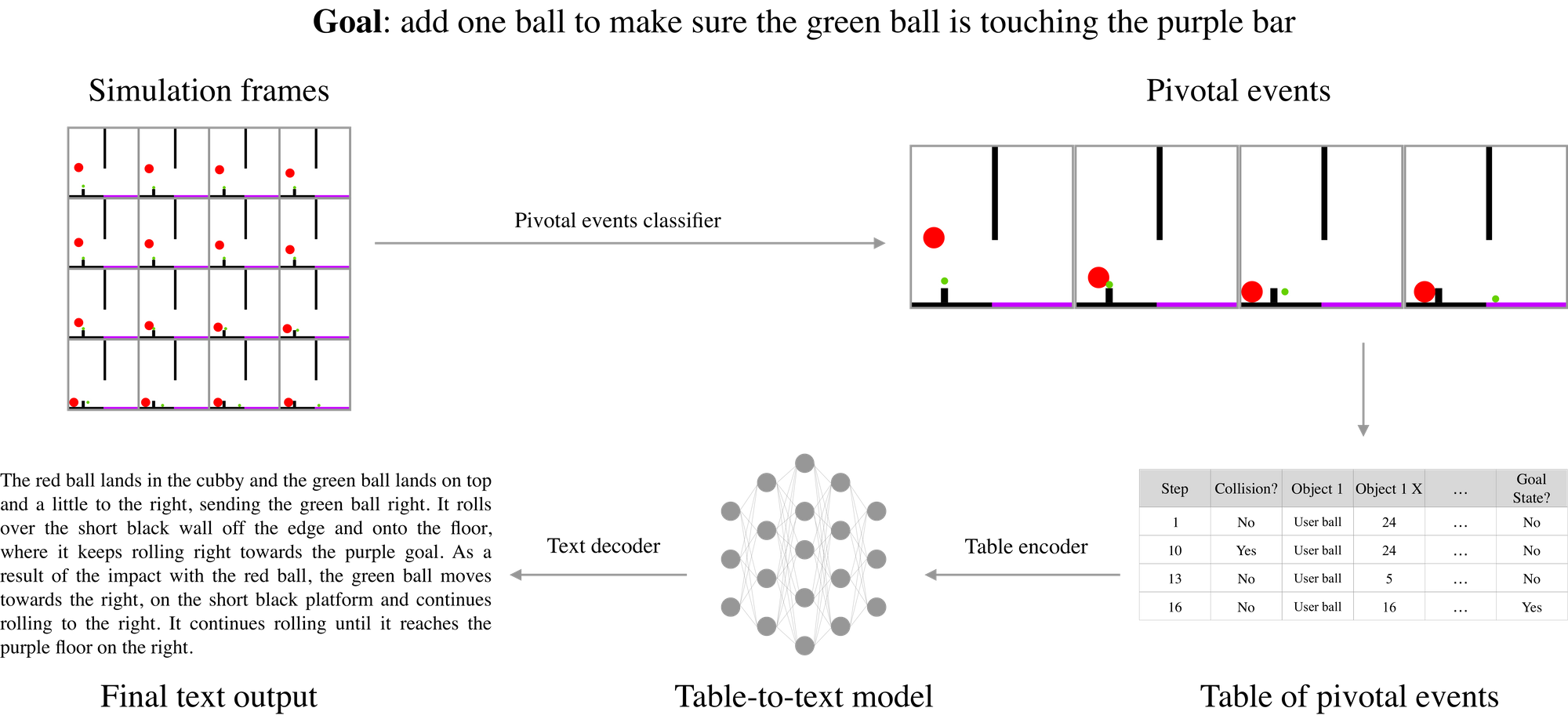
- Phase 1: The first phase of the framework uses a neural network classifier to identify salient frames from the simulation.
- Phase 2: For the second phase, we experimented with table-to-text models (Puduppully et al., 2019a,b) as well as pre-trained language models (LM) (Radford et al.,2018).
We evaluated our framework for natural language-generated reasoning using several automated and human evaluations with a focus on the understanding of qualitative physics and the ordering of a natural sequence of physical events. We found that our model achieves very high performance for phase one and that, for phase two, the table-to-text models outperform pre-trained language models on qualitative physics reasoning, Yet, there is a lot more room for improvement.
The three physical concepts at play in the simulations — friction, collision, and gravity — are either a cause or an effect of some collision. Since collisions were the most common physical event in the simulations (average of 54 per simulation), we decided to only record collisions. We asked annotators to pick pivotal or salient collisions by selecting all and only the collisions that are causally related to the placement of the red ball (solution action) and that are necessary for the completion of the goal. We also collected human annotations of natural language descriptions for the initial scene and explanations for the sequence of salient collisions that were collected.
Results. Our three-layer MLP classifier for identifying pivotal frames gets an F1 of 0.9 using features about the objects involved in a collision, their position, velocity, and angle of rotation. We observed that automatic metrics (BLEU, ROUGE, METEOR) for natural language generation failed to capture the correctness and coverage of actual physical concepts or even the natural ordering in which physical events occur in a given simulation. For example, a ball is pushed and then it falls down. Both our fine-tuned table-to-text model and language model perform very similarly on these metrics, but their generations are semantically very different. As a result, we proposed two human evaluation metrics to test for validity and coverage of physical concepts.
Evaluating validity. For evaluating the validity of explanations for pivotal events, we showed humans:
- the generated text for a task,
- the initial state of that task, and
- three distractor initial states generated from the same task but with positions of the red ball that do not solve the task.
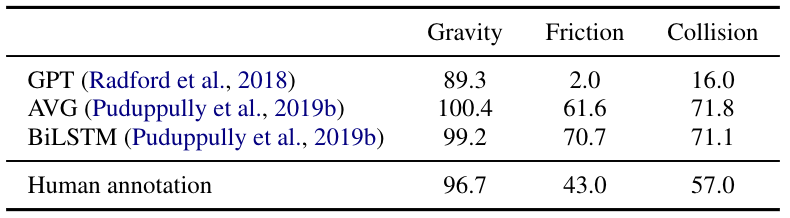
Then, we asked them to select the correct initial state with the red ball that would eventually reach the task goal. A good explanation should be correlated with high human accuracy to choose the correct solution. The table below shows the results obtained by each of our models as well as the results for humans evaluating human annotations of explanations. As shown, the ground truth human annotations are not perfect and lack fine-grained details. This is because of reporting bias, i.e., humans rarely state events that are obvious or commonsense (Forbes and Choi, 2017).

Evaluating coverage. To measure coverage, we showed humans only the natural language description of the simulation and asked them to select words that would imply any of the three concepts. For example, “rolling” or “slipping” would imply friction, “falling” would imply gravity, “hit” would imply collision, etc. We note that many physical concepts are very abstract and difficult to even notice visually, let alone describe in natural language. For example, moving objects slow down due to friction, but this physical concept is so innate that humans would not generally use words that imply friction to describe what they see. This metric gives us an overview of what degree of coverage the text generation models have for each of the three physical concepts. The table below shows the results obtained. Top words identified by humans from natural language generations of table-to-text models are “falls,” “drop,” “slope,” “land” for gravity; “roll,” “slide,” “trap,” “travel,” “stuck,” “remain” for friction; and “hit,” “collide,” “impact,” “land,” “pin,” “bounce” for collisions.
We hope that the dataset we collected will facilitate research in using natural language for physical reasoning.
AI models that can meaningfully reason about common sense qualitative physics could be interpretable and more robust, as they might focus on the parts of physical dynamics that are relevant for generalization to new scenarios. Such systems are widely applicable to self-driving cars or tasks that involve human-AI interactions, such as robots performing everyday human tasks like making coffee or even collaboratively helping with rescue operations.
Nazneen Fatema Rajani*, Rui Zhang*, Yi Chern Tan, Stephan Zheng, Jeremy Weiss, Aadit Vyas, Abhijit Gupta, Caiming Xiong, Richard Socher and Dragomir Radev.
ESPRIT: Explaining Solutions to Physical Reasoning Tasks.
In Proceedings of the 2020 Conference of the Association for Computational Linguistics (ACL2020).
References:
- Ratish Puduppully, Li Dong, and Mirella Lapata. 2019a. Data-to-text generation with content selection and planning. In AAAI.
- Ratish Puduppully, Li Dong, and Mirella Lapata. 2019b. Data-to-text generation entity modeling. In ACL.
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language under-standing by generative pre-training. Technical report, OpenAI.
- Maxwell Forbes and Yejin Choi. 2017. Verb physics: Relative physical knowledge of actions and objects. In ACL.