 Blog Home
Blog HomeBurn After Reading: Preserving Privacy Using Online Adaptation for Cross-Domain Streaming Data
AUTHORS: Zeyuan Chen, Ran Xu, Luyu Yang, Donald Rose
TL;DR: Many methods designed to preserve online privacy propose complex security measures to protect sensitive data. We believe that not storing any sensitive data is the optimal way to preserve privacy, so we propose a “burn after reading” online framework: user data samples are immediately deleted after they’re processed. Even though user data are unlabeled and not stored, our model can adapt to the novel samples very well and achieves state-of-the-art performance on four domain-adaptation benchmarks.
Background
The pandemic has made the internet even more ubiquitous in our lives, and along with its many benefits comes a new reality: it’s extremely hard to escape one’s past now that every photo, status update, and tweet lives forever in the cloud. Face it: your face (along with other data) is out there, and hard to get rid of.
But changes may be afoot. Recommender systems that actively explore user data with data-driven algorithms have sparked debate about whether the right to privacy should take priority over convenience. And we have the Right to Be Forgotten (RTBF), which gives individuals the right to ask organizations to delete their personal data.
Since machine learning models use a lot of data, a valid question is whether there are ways to protect the privacy of the people associated with that data. We believe the answer is yes, and it’s fertile ground for researchers to explore. For example, here are two approaches:
- Don’t store any user data: One privacy-preserving paradigm that seems promising yet challenging: build a model that adapts well to novel samples without storing any user data. This can be formulated as an Unsupervised Domain Adaptation (UDA) problem (a special form of transfer learning): a machine learning model is trained on abundant labeled data (the “source domain”) and needs to adapt to customer data (the “target domain”), which might not be similar to the source domain (the target domain contains unlabeled data insufficient for training).
- Only store limited user data: Recently, many solutions have been proposed that try to preserve privacy in the context of deep learning, mostly focused on Federated Learning (FL). FL allows asynchronous update of multiple nodes, in which sensitive data is stored only on a few specific nodes.
Limitations of Existing Work
While the above approaches show promise, they also face challenges and drawbacks:
- The don’t-store-user-data approach has the “online-UDA problem”: To achieve the goal of preserving online privacy, the target-domain data needs to be discarded right after the model sees it, but that means it won't be available if the model wants to use it later — in contrast to the offline-UDA, where user data can be stored and accessed later by the model.
- FL’s method of storing data on only a few nodes has the “leaking data” problem: Recent studies show that private training data could be leaked or exploited due to the gradients-sharing mechanism deployed in distributed models.
Leaking data is, of course, never a good thing - and that’s why we argue that not storing any sensitive data is the optimal method of preserving privacy (deleting user data after use), which necessitates an online framework.
However, existing online learning frameworks cannot meet this need without addressing the distribution shift from source to target domains. This task, which is seemingly an extended setting of UDA, cannot simply be solved by an online implementation of the offline UDA methods. To begin with, existing offline UDA methods rely heavily on the rich combinations of cross-domain mini-batches that gradually adjust the model for adaptation, which the online streaming setting cannot afford to provide. In particular, many existing methods require discriminating a large number of source-target pairs to achieve the adaptation. Recently, state-of-the-art offline methods show promising results by exploiting target-oriented clustering, but that requires offline access to the entire target domain.
The upshot is that the online UDA task needs new solutions in order to succeed, given the scarcity of data from the target domain.
Our Solution
We believe we’ve found a new and innovative approach. In this work:
- We argue that not storing any sensitive data is the best practice for preserving privacy and ensuring overall security.
- We propose an online framework that “burns after reading” — that is, user data is immediately deleted after being used in the machine learning process.
- More specifically, we train deep neural networks on labeled public data (“source domain”) and adapt them to perform well on unlabeled private data (“target domain”) - but we only keep data around as long as it's needed for training and testing. After that, the data's deleted. (See figure below.)
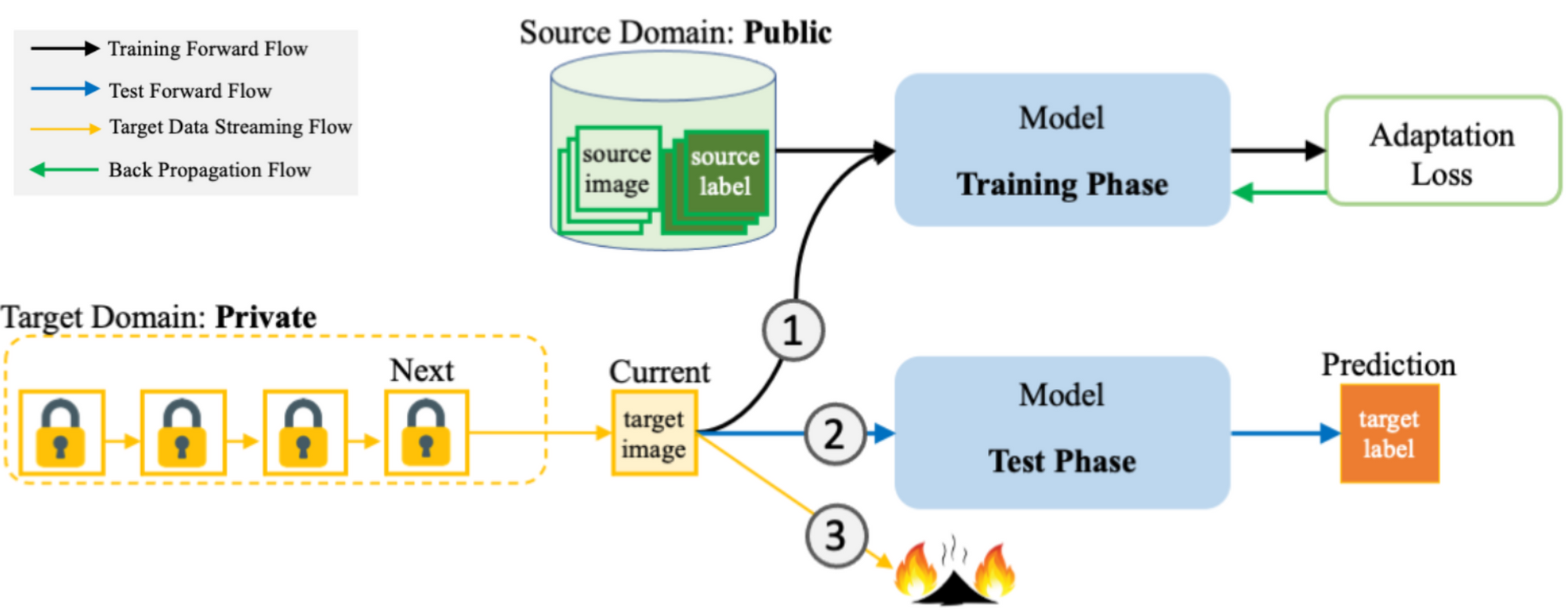
- Similar to the UDA problem, we need to handle the inevitable data distribution shift (in other words, the differences) between the source and target domains.
- It's called “data distribution shift” because usually the data distribution is shifted gradually rather than changed abruptly.
- For example, if we have a model to recognize texts on driver's licenses, some states may change their formats after a few years. Our model should be able to handle the new formats (the “distribution shift”) as well.
- Another example: people may want to train models on synthetic data and still want them to perform well on real images (as shown in the figure below). However, there’s a large domain gap between the synthetic and real images.

In addition to the distribution shift issue, we focus on the fundamental challenge of the online task—the lack of diverse cross-domain data pairs.
- To address this challenge, we propose a novel Cross-Domain Bootstrapping algorithm (or CroDoBo for short).
- The goal of CroDoBo: increase data diversity across domains and fully exploit the valuable discrepancies among the diverse combinations of source and target data samples.
Deeper Dive
How Our Method Works
We aim straight at the most fundamental challenge of the online task—the lack of diverse cross-domain data pairs—and propose a novel algorithm based on cross-domain bootstrapping for online domain adaptation. At each online query, we increase data diversity across domains by bootstrapping the source domain to form diverse combinations with the current query. To fully exploit the valuable discrepancies among the diverse combinations, we train a set of independent learners to preserve the differences. We later integrate the knowledge of these learners by exchanging their predicted pseudo-labels on the current target query to co-supervise the learning on the target domain, but without sharing the weights to maintain the learners’ divergence. We obtain more accurate prediction on the current target query by an average ensemble of the diverse expertise of all the learners.
The figure below shows an overview of our proposed CroDoBo algorithm. CroDoBo adapts from a public source domain to a streaming online target domain. At each timestep j, only the current j-th query is available from the target domain. CroDoBo bootstraps the source domain batches that combine with the current j-th query in order to increase the cross-domain data diversity. The learners (w) exchange the generated pseudo-labels (y) as co-supervision.

Once the current query is adapted in the training phase, it is tested immediately to make a prediction. And then comes the privacy-preserving part: each target query is deleted after being tested (note the flame icons in the lower left of the figure, on the “j-1” box, indicating that data is deleted once it’s processed).
Example images of the source domain are from Fashion-MNIST, adapting to the target domain Deep-Fashion.
Offline vs. Online
Given the labeled source data and unlabeled target data drawn from the target distribution, both offline and online adaptation aim at learning a classifier that makes accurate predictions on the target domain. The offline adaptation assumes access to every data point in both the source and target domains, and needs to train the model on all of those data points before making inferences.
However, for online adaptation, we can only assume access to the entire source domain, while data for the target domain arrives in a random streaming fashion of mini-batches. Each mini-batch (or what we call a “query”) is adapted, tested, and then erased without replacement to preserve privacy.
The fundamental challenge of the online task is limited access to the training data at each inference query, compared to the offline task. Undoubtedly, online adaptation faces a significantly smaller data pool and less data diversity, which means the training process of the online task suffers from two major drawbacks:
- First, the model is prone to underfitting on the target domain due to the limited exposure, especially at the beginning of training.
- Second, due to the erasure of “seen” batches, the model lacks the diverse combinations of source-target data pairs that enable the deep network to find the optimal cross-domain classifier.
The goal of our proposed method is to minimize these drawbacks of the online setting. We first propose to increase data diversity by cross-domain bootstrapping, while data diversity is preserved in multiple independent learners. Then we fully exploit the valuable discrepancies of these learners by exchanging their expertise on the current target query to co-supervise each other.
Cross-Domain Bootstrapping
The diversity of cross-domain data pairs is crucial for most prior offline methods to succeed. Since the target samples cannot be reused in the online setting, we propose to increase the data diversity across domains by bootstrapping the source domain to form diverse combinations with the current target domain query. At a high level, the bootstrap simulates multiple realizations of a specific target query given the diversity of source samples. The bootstrapping brings multi-view observations on a single target query.
Exploit Discrepancies via Co-Supervision
After the independent learners have preserved the valuable discrepancies of cross-domain pairs, the question now is how to fully exploit the discrepancies to improve the online predictions on the target queries. On the one hand, we want to integrate the learners’ expertise into one better prediction on the current target query. On the other hand, we hope to maintain their differences. We train the learners jointly by exchanging their knowledge on the target domain as a form of co-supervision. Specifically, the learners are trained independently with bootstrapped source supervision, but they exchange the pseudo-labels generated for target queries.
Evaluating Our Method
Dataset and Evaluation Metrics
We consider two metrics for evaluating online domain-adaptation methods: online average accuracy and one-pass accuracy. The online average is an overall estimate of the streaming effectiveness. The one-pass accuracy measures after training on the finite sample how much the online model has deviated from the beginning. A one-pass accuracy much lower than the online average indicates that the model might have overfitted to the fresh queries, but compromised its generalization ability to the early queries.
We conducted the experiments on four benchmarks.
VisDA-C is a classic benchmark adapting from synthetic images to real.
COVID-DA is adapting CT image diagnosis from common pneumonia to the novel disease.
WILDS-Camelyon17 is a large-scale medical dataset that contains histopathology images with patient population shift from source to target.
Fashion-MNIST to DeepFashion. Due to the lack of cross-domain fashion prediction datasets, we propose to evaluate adapting from these two. We select six fashion categories shared between the two datasets, and design the task as adapting from grayscale samples of Fashion-MNIST to real-world commercial samples from DeepFashion.
Below are image samples from these benchmarks and a qualitative comparison between our method (CroDoBo) and existing state-of-the-art (SOTA) methods.

Main Results
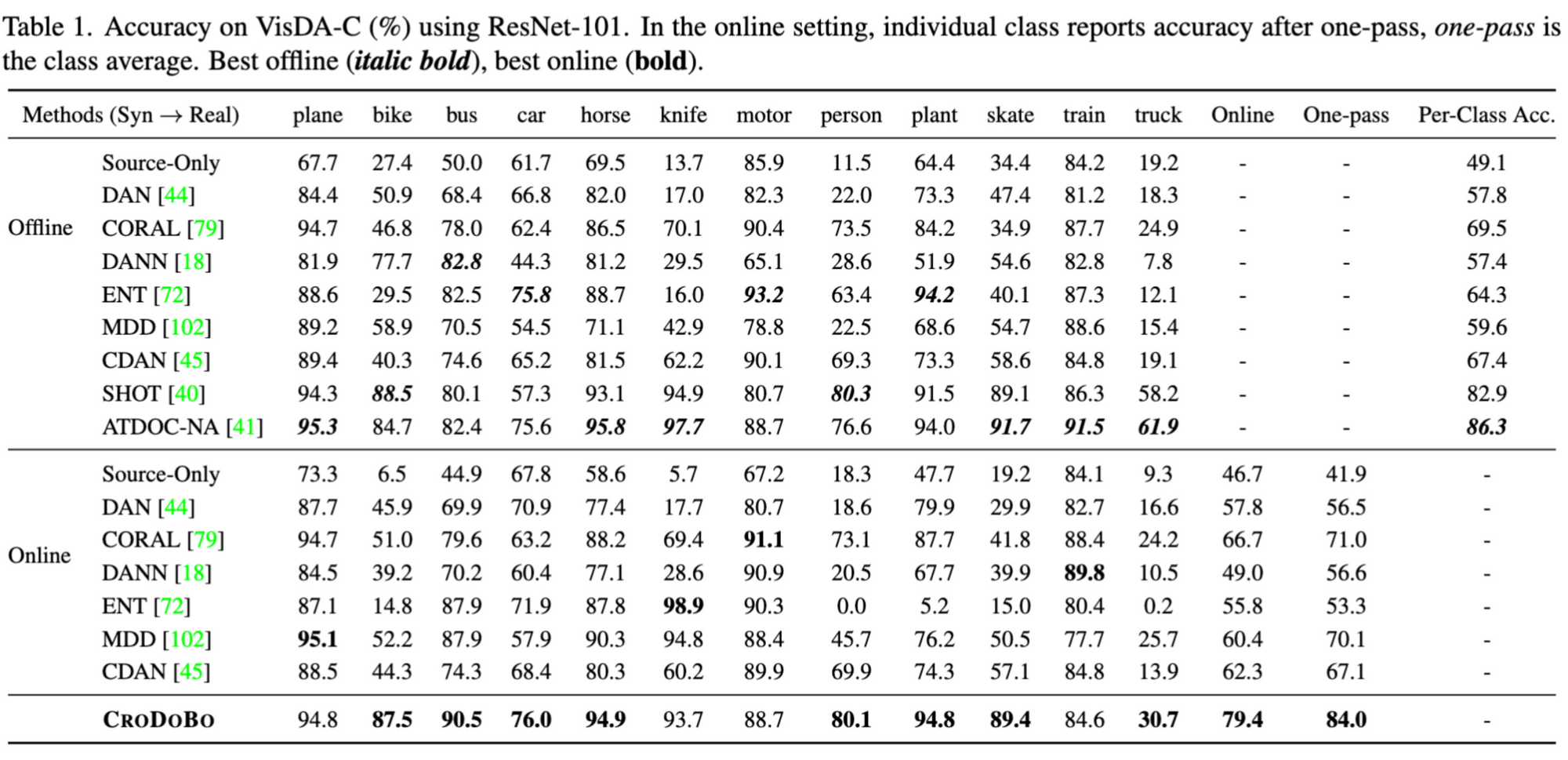
We are pleased to report that CroDoBo outperforms other methods in the online setting by a large margin, and is comparable to the offline result from the state-of-the-art approach ATDOC-NA. With regard to time efficiency, CroDoBo is superior to other approaches by achieving high accuracy in only one epoch.
The table below summarizes the results on VisDA-C, and we plot the online streaming accuracy in the figure below. For more results on other datasets, such as WILDS-Camelyon17, Fashion-MNIST to DeepFashion, etc., please read our research paper.

Results of online accuracy on VisDA-C. X-axis is the streaming timestep of the target queries. Each approach takes the same randomly perturbed sequence of target queries.
The Big Picture: Research and Societal Impacts
Our work proposes an online domain-adaptation framework in which target data is erased immediately after being processed. This is beneficial, both with regard to an individual’s right to be forgotten and related aspects of online privacy protection. However, while our method improves data privacy, there still is a risk of data leakage. Like most neural networks, someone could purposefully exploit the memorization effect of the deep neural network weights to restore private information. We will focus on mitigating this issue in future work.
In addition to a method to achieve increased security, we developed a novel online UDA algorithm to tackle the lack of data diversity (the diverse source and target data combinations); our method augments data to make it easy to adapt to an unknown target domain. We hope this approach can aid future research in UDA and related areas of AI and ML. The fact that our proposed method achieves state-of-the-art online results, and comparable results to the offline domain adaptation approaches, validates our approach as a useful and fruitful line of research. Future work to expand its capabilities (for example, we would like to extend CroDoBo to more tasks, such as semantic segmentation) should further increase its positive impacts.
The Bottom Line
Key takeaways and contributions:
- We propose an online domain-adaptation framework that enables user data to be deleted (rather than stored) after being processed. In other words, we’ve created a framework to implement the “right to be forgotten" in a machine learning context.
- We designed a novel algorithm to address the most fundamental challenge of the online adaptation setting: the lack of diverse source-target data pairs. Our Cross-Domain Bootstrapping (CroDoBo) approach increases the combined data diversity across domains.
- Our online domain-adaptation algorithm achieves new state-of-the-art online results, and comparable results to the offline setting.
- This latter achievement is significant because the offline setting allows access to a more complete set of data, whereas our online framework has access to less data.
- Despite being a simple framework, our method’s comparable performance to the offline setting suggests that it’s an excellent choice (even just for time efficiency), and a research area worthy of further exploration.
Explore More
Salesforce AI Research invites you to dive deeper into the concepts discussed in this blog post (links below). Connect with us on social media and our website to get regular updates on this and other research projects.
- Paper: Learn more about our work by reading our research paper (accepted by ECCV 2022)
- Code: Visit our Github page at https://github.com/salesforce/burn-after-reading
- Contact us: zeyuan.chen@salesforce.com
- Project site: https://www.loyo.me/projectpages/burnAfterReading/BurnAfterReading.html
- Follow us on Twitter: @SalesforceResearch, @Salesforce
About the Authors
Zeyuan Chen is a Lead Research Engineer at Salesforce Research. His research interests are in computer vision, robotics process automation (RPA), and multimodal foundation models.
Ran Xu is a Director of Applied Research at Salesforce Research. He leads computer vision and multimodal research, helps the team to transform research into AI products, and drives customer success.
During this work, Luyu Yang was a research intern at Salesforce Research. She received her Ph.D. degree from the computer science department at the University of Maryland. Her research interests include domain adaptation, noisy-label learning, and robust model learning.
Donald Rose is a Technical Writer at Salesforce Research. Specializing in content creation and editing, he works on multiple projects including blog posts, video scripts, news articles, media/PR material, writing workshops, and more. His passions include helping researchers transform their work into publications geared towards a wider audience, and writing think pieces about AI.
Glossary
- Unsupervised domain adaptation (UDA): The goal of UDA is to improve the performance of a model on a target domain (which contains insufficient and unlabeled data) by using the knowledge learned by the model from another related source domain (which has enough labeled data). This is a special form of transfer learning.
- Data bootstrapping: The idea is to estimate the true data distribution based on the empirical distribution of resampled data. This process resamples the original dataset to create many simulated ones. If sampled appropriately, the simulated datasets can be used to accurately estimate the true data distribution.
- Pseudo labels: Labels predicted by machine learning models trained on labeled data. They are an approximation of the real labels.