 Blog Home
Blog HomeOmniXAI: Making Explainable AI Easy for Any Data, Any Models, Any Tasks
TL;DR: OmniXAI (short for Omni eXplainable AI) is designed to address many of the pain points in explaining decisions made by AI models. This open-source library aims to provide data scientists, machine learning engineers, and researchers with a one-stop Explainable AI (XAI) solution to analyze, debug, and interpret their AI models for various data types in a wide range of tasks and applications. OmniXAI’s powerful features and integrated framework make it a major addition to the burgeoning field of XAI.
Background and Motivation: The Need for Explainable AI
With the rapidly growing adoption of AI models in real-world applications, AI decision making can potentially have a huge societal impact, especially for application domains such as healthcare, education, and finance. However, many AI models, especially those based on deep neural networks, effectively work as black-box models that lack explainability. This works to inhibit their adoption in certain critical applications (even when their use would be beneficial) and hamper people’s trust in AI systems.
This limitation - the opacity of many AI systems - led to the current surge in interest in Explainable AI (often referred to as XAI), an emerging field developed to address these challenges. XAI aims to explain how an AI model “thinks” — that is, XAI techniques (“explainers”) aim to reveal the reasoning behind the decision(s) that an AI model has made, opening up the black box to see what’s inside. Such explanations can improve the transparency and persuasiveness of AI systems, as well as help AI developers debug and improve model performance.
Several popular techniques for doing XAI have emerged in the field, such as LIME (Local Interpretable Model-agnostic Explanations), SHAP (Shapley Additive Explanations), and Integrated Gradients (IG is XAI in the domain of deep neural networks). Each method or "flavor" of XAI has their special abilities and features.
Limitations of Other XAI Libraries
Most existing XAI libraries support limited data types and models. For example, InterpretML only supports tabular data, while Captum only supports PyTorch models for images and texts.
In addition, different libraries have quite different interfaces, making it inconvenient for data scientists or ML developers to switch from one XAI library to another when seeking a new explanation method.
Also, a visualization tool is essential for users to examine and compare explanations, but most existing libraries don’t provide a convenient tool for visualizing and analyzing explanations.
OmniXAI: One-Stop ML Library Makes XAI Easy for All
We developed an open-source Python library called OmniXAI (short for Omni eXplainable AI), offering an “omni-directional” multifaceted approach to XAI with comprehensive interpretable machine learning (ML) capabilities designed to address many of the pain points in understanding and interpreting decisions made by ML models in practice.
OmniXAI serves as a one-stop comprehensive library that makes explainable AI easy for data scientists, ML researchers, and practitioners who need explanations for any type of data, model, and explanation method at different stages of the ML process (such as data exploration, feature engineering, model development, evaluation, and decision making).
As the name implies, OmniXAI combines several elements into one. In the discussion below, we’ll see how our approach allows users to take advantage of features present in several popular explanation methods, all within a single framework.
Deep Dive
Unique Features of OmniXAI
As shown in the figure below, OmniXAI offers a one-stop solution for analyzing different stages in a standard ML pipeline in real-world applications, and provides a comprehensive family of explanation methods.

The explanation methods can be categorized into “model-agnostic” and “model-specific”:
- “Model-agnostic” means a method can explain the decisions made by a black-box model without knowing the model details.
- “Model-specific” means a method requires some knowledge about the model to generate explanations — for instance, whether the model is a tree-based model or a neural network.
Typically, there are two types of explanations — local and global:
- Local explanation indicates why a particular decision was made.
- Global explanation analyzes the global behavior of the model instead of a particular decision.
The following table shows the supported interpretability algorithms in OmniXAI:
| Method | Model Type | Explanation Type | EDA | Tabular | Image | Text | Timeseries |
| Feature analysis | NA | Global | ✅ | ||||
| Feature selection | NA | Global | ✅ | ||||
| Partial dependence plot | Black box | Global | ✅ | ||||
| Sensitivity analysis | Black box | Global | ✅ | ||||
| LIME [1] | Black box | Local | ✅ | ✅ | ✅ | ||
| SHAP [2] | Black box | Local | ✅ | ✅ | ✅ | ✅ | |
| Integrated Gradients (IG) [3] | PyTorch or TensorFlow | Local | ✅ | ✅ | ✅ | ||
| Counterfactual | Black box | Local | ✅ | ✅ | ✅ | ✅ | |
| Contrastive explanation | PyTorch or TensorFlow | Local | ✅ | ||||
| Grad-CAM [4] | PyTorch or TensorFlow | Local | ✅ | ||||
| Learning-to-explain (L2X) | Black box | Local | ✅ | ✅ | ✅ | ||
| Linear models | Linear models | Global/local | ✅ | ||||
| Tree models | Tree models | Global/local | ✅ |
Some other key features of OmniXAI:
- Supports feature analysis and selection — for example, analyzing feature correlations, checking data imbalance issues, selecting features via mutual information
- Supports most popular machine learning frameworks or models, such as PyTorch, TensorFlow, scikit-learn, and customized black-box models
- Includes most popular explanation methods, such as feature-attribution/importance explanation (LIME [1], SHAP [2], Integrated Gradients (IG) [3], Grad-CAM [4], L2X), counterfactual explanation (MACE [5]), partial dependence plots (PDP), and model-specific methods (linear and tree models)
- Can be applied on tabular, vision, NLP, and time-series tasks.
The table below summarizes these powerful features of OmniXAI, and shows how OmniXAI compares to other existing explanation libraries, such as IBM’s AIX360, Microsoft’s InterpretML, and Alibi. Note that OmniXAI is the only one of these libraries to include all of methods listed (see second and third columns).
| Data Type | Method | OmniXAI | InterpretML | AIX360 | Eli5 | Captum | Alibi | explainX |
| Tabular | LIME | ✅ | ✅ | ✅ | ✅ | |||
| SHAP | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Partial dependence plot | ✅ | ✅ | ||||||
| Sensitivity analysis | ✅ | ✅ | ||||||
| Integrated Gradients | ✅ | ✅ | ✅ | |||||
| Counterfactual | ✅ | ✅ | ||||||
| L2X | ✅ | |||||||
| Linear models | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Tree models | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ||
| Image | LIME | ✅ | ✅ | |||||
| SHAP | ✅ | ✅ | ||||||
| Integrated Gradients | ✅ | ✅ | ✅ | |||||
| Grad-CAM | ✅ | ✅ | ✅ | |||||
| Contrastive explanation | ✅ | ✅ | ✅ | |||||
| Counterfactual | ✅ | ✅ | ||||||
| L2X | ✅ | |||||||
| Text | LIME | ✅ | ✅ | ✅ | ||||
| SHAP | ✅ | ✅ | ||||||
| Integrated Gradients | ✅ | ✅ | ✅ | |||||
| Counterfactual | ✅ | |||||||
| L2X | ✅ | |||||||
| Timeseries | SHAP | ✅ | ||||||
| Counterfactual | ✅ |
Other notable features of OmniXAI:
- In practice, users may choose multiple explanation methods to analyze different aspects of AI models. OmniXAI provides a unified interface so they only need to write a few lines of code to generate various kinds of explanations.
- OmniXAI supports Jupyter Notebook environments.
- Developers can add new explanation algorithms easily by implementing a single class inherited from the explainer base class.
- OmniXAI also provides a visualization tool for users to examine the generated explanations and compare interpretability algorithms.
OmniXAI’s Design
The key design principle of OmniXAI is that users can apply multiple explanation methods and visualize the corresponding generated explanations at the same time. This principle makes our library:
- easy to use (generating explanations by writing just a few lines of code)
- easy to extend (adding new explanation methods easily without affecting the library framework), and
- easy to compare (visualizing the explanation results to compare multiple explanation methods).
The following figure shows the pipeline for generating explanations:

Given an AI model (PyTorch, TensorFlow, scikit-learn, etc.) and data (tabular, image, text, etc.) to explain, one only needs to specify the names of the explainers they want to apply, the preprocessing function (e.g., converting raw input features into model inputs), and the postprocessing function (e.g., converting model outputs into class probabilities for classification tasks). OmniXAI then creates and initializes the specified explainers and generates the corresponding explanations. To visualize and compare these explanations, one can launch a dashboard app built on Plotly Dash.
Example Use Cases
Ex.1: Explaining Tabular Data for Data Science Tasks
Let's consider an income prediction task. The dataset used in this example is the Adult dataset including 14 features, such as age, workclass, and education. The goal: predict whether income exceeds $50K per year on census data.
We train an XGBoost classifier for this classification task, then apply OmniXAI to generate explanations for each prediction given test instances. Suppose we have an XGBoost model with training dataset "tabular_data" and feature processing function "preprocess", and we want to analyze feature importance, generate counterfactual examples, and analyze the dependence between features and classes.
The explainers applied in this example are LIME, SHAP for feature attribution/importance explanation, MACE for counterfactual explanation, and PDP for partial dependence plots. LIME, SHAP, and MACE generate local (instance-level) explanations, such as showing feature importance scores and counterfactual examples for each test instance; PDP generates global explanations, showing the overall dependence between features and classes. Given the generated explanations, we can launch a dashboard for visualization by setting the test instances, the generated local and global explanations, the class names, and additional parameters for visualization.
The following figure shows the explanation results generated by multiple explainers (LIME, SHAP, MACE, and PDP) given a test instance:
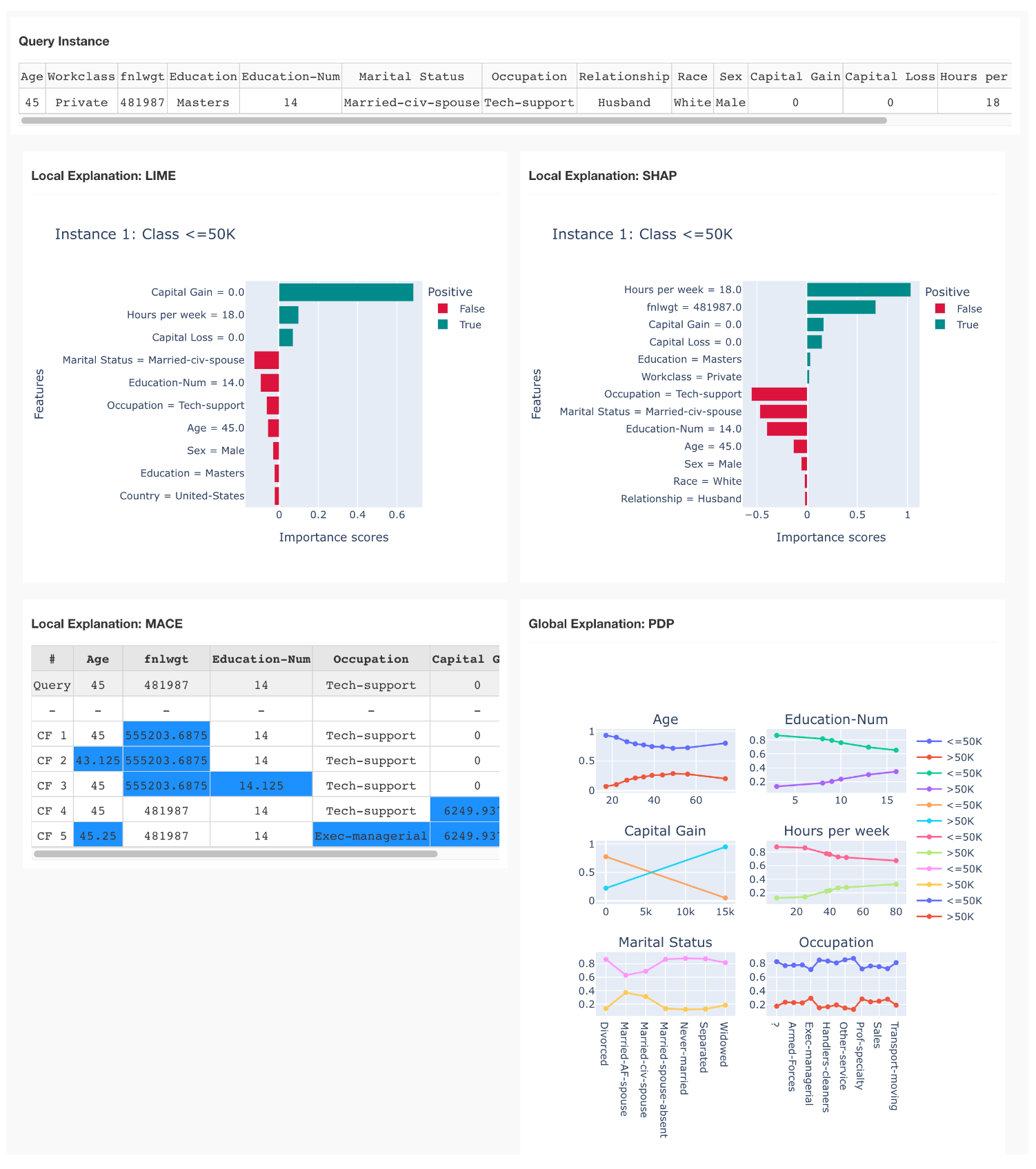
One can easily compare the feature-attribution explanations generated by LIME and SHAP: the predicted class is "< 50k" because "Hours per week = 18" (less than normal working hours), "Capital gain = 0" (no additional asset income), and "Capital loss" (people whose income is larger than 50k may have more investments).
MACE generates counterfactual examples, exploring "what-if" scenarios and obtaining more insights of the underlying AI model — for instance, if "Capital gain" increases from 0 to 6249, the predicted class will be "> 50k" instead of "< 50k".
PDP explains the overall model behavior — for instance, income will increase as "Age" increases from 20 to 45, then income will decrease when "Age" increases from 45 to 80; longer working hours per week may lead to a higher income; and married people have higher income (note: this is a potential bias in the dataset).
Overall, by using this dashboard, one can easily understand why such predictions are made, whether there are potential issues in the dataset, and whether more feature processing/selection is needed.
Ex.2: Explaining Image Data for Visual Recognition Tasks
Our next example is an image classification task. We choose a ResNet pre-trained on ImageNet for demonstration. For generating explanations, we apply the LIME, Integrated Gradients, and Grad-CAM explainers.
Note that we apply Grad-CAM with different parameters — for example, the target layers of "gradcam0" and "gradcam2" are "layer4[-1]" while the target layers of "gradcam1" and "gradcam3" are "layer4[-3]", and the label to explain for the first two Grad-CAM explainers is "dog" while for the other Grad-CAM explainers it's "cat".
The following figure shows the explanation results generated by these explainers. As you can see, Grad-CAM generates four local explanations (GRADCAM#0-#3, one for each of the different parameter scenarios), each with its own visualization.


Ex.3: Explaining Text Data for NLP Tasks
OmniXAI also supports NLP tasks. Let’s consider a sentiment classification task on the IMDb dataset where the goal is to predict whether a user review is positive or negative. We train a text CNN model for this classification task using PyTorch, then apply OmniXAI to generate explanations for each prediction given test instances. Suppose the processing function which converts the raw texts into the inputs of the model is "preprocess", and we want to analyze word/token importance and generate counterfactual examples.
The figure below shows the explanation results generated by explainers LIME, Integrated Gradients, and Polyjuice. Clearly, LIME and Integrated Gradients show that the word “great” has the largest word/token importance score, which implies that the sentence “What a great movie! if you have no taste.” is classified as “positive” because it contains the word “great”. The counterfactual method generates several counterfactual examples for this test sentence — such as, “what a terrible movie! if you have no taste.” — helping us understand more about the model’s behavior.

Ex.4: Explaining Time Series Anomaly Detection
OmniXAI can be applied in time series anomaly detection and forecasting tasks. It currently supports SHAP-value-based explanation for anomaly detection and forecasting, and counterfactual explanation for anomaly detection only. We will implement more algorithms for time-series-related tasks in the future.
This example considers a univariate time series anomaly detection task. We use a simple statistics-based detector for demonstration — e.g., a window of time series is detected as an anomaly according to some threshold estimated from the training data.
The following figure shows the explanation results generated by SHAP and MACE:

The dashed lines demonstrate the importance scores and the counterfactual example, respectively. SHAP shows the most important timestamps making this test time series detected as an anomaly. MACE provides a counterfactual example showing that it will not be detected as an anomaly if the metric values from 20:00 to 00:00 are around 2.0. From these two explanations, one can clearly understand the reason why the model considers it an anomaly.
The Big Picture: Societal Benefits and Impact
Using an XAI library such as OmniXAI in the real world should have a positive effect on AI and society, for multiple reasons:
- The decisions made by AI models in real-world applications such as healthcare and finance potentially have a huge societal impact, yet the lack of explainability in those models hampers trust in AI systems and inhibits their adoption. OmniXAI provides valuable tools to “open” AI models and explain their decisions to improve the transparency and persuasiveness of AI systems, helping customers understand the logic behind the decisions. This not only gives customers peace of mind and increased knowledge, but also fosters a general trust in AI systems, which helps speed the adoption of AI systems and bring their benefits to more areas of society.
- Real-world applications usually need to handle complicated scenarios, which means AI models may sometimes make unsatisfying or wrong decisions due to data complexity. When that happens, explaining why an AI model fails is vitally important. Such explanations not only help maintain customer confidence in AI systems, but also helps developers resolve issues to improve model performance. OmniXAI analyzes various aspects of AI models and figures out the relevant issues when a wrong decision is made, helping developers quickly understand the reasons behind failures and improve the models accordingly.
- While OmniXAI has many potential positive impacts, the misuse of OmniXAI may result in negative impacts. In particular, the OmniXAI library should not be used to explain misused AI/ML models or any unethical use case. It also should not be used to enable hacking of models through public prediction APIs, stealing black-box models, or breaking privacy policies.
The Bottom Line
- OmniXAI is designed to address many of the pain points in explaining decisions made by AI models.
- OmniXAI aims to provide data scientists, machine learning engineers, and researchers with a comprehensive one-stop solution to analyze, debug, and explain their AI models.
- We will continue to actively develop and improve OmniXAI. Planned future work includes more algorithms for feature analysis, more interpretable algorithms, and supports for more data types and tasks (for example, visual-language tasks and recommender systems). We will also improve the dashboard to make it more comprehensive and better to use.
- We welcome and encourage any contributions from the open source community.
Explore More
Salesforce AI Research invites you to dive deeper into the concepts discussed in this blog post (links below). Connect with us on social media and our website to get regular updates on this and other research projects.
- Paper: Learn more about OmniXAI by reading our research paper.
- Code: See our OmniXAI library Github page.
- Demo: Check out our Explanation Dashboard Demo.
- Tutorials: Check out more detailed examples and tutorials of OmniXAI.
- Documentation: Explore OmniXAI documentation.
- Contact us: omnixai@salesforce.com.
- Follow us on Twitter: @SalesforceResearch, @Salesforce.
Related Resources
[1] Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why should I trust you?”: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 1135–1144, 2016.
[2] Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 4765–4774. Curran Associates, Inc., 2017.
[3] Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, page 3319–3328. JMLR.org, 2017.
[4] Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. International Journal of Computer Vision, 128(2):336–359, Oct 2019.
[5] Wenzhuo Yang, Jia Li, Caiming Xiong, and Steven C.H. Hoi. MACE: An Efficient Model-Agnostic Framework for Counterfactual Explanation, 2022. URL https://arxiv.org/abs/2205.15540.
About the Authors
Wenzhuo Yang is a Senior Applied Researcher at Salesforce Research Asia, working on AIOps research and applied machine learning research, including causal machine learning, explainable AI, and recommender systems.
Steven C.H. Hoi is Managing Director of Salesforce Research Asia and oversees Salesforce's AI research and development activities in APAC. His research interests include machine learning and a broad range of AI applications.
Donald Rose is a Technical Writer at Salesforce AI Research. Specializing in content creation and editing, Dr. Rose works on multiple projects, including blog posts, video scripts, news articles, media/PR material, social media, writing workshops, and more. He also helps researchers transform their work into publications geared towards a wider audience.