 Blog Home
Blog HomeImproving end-to-end Speech Recognition Models
Speech recognition has been successfully depolyed on various smart devices, and is changing the way we interact with them. Traditional phonetic-based recognition approaches require training of separate components such as pronouciation, acoustic and language model. Since the models are all trained separately with different training objectives, improving one of the components does not necessarily lead to performance improvement of the whole system. This makes improving of the system performance difficult. End-to-End models address the aforementioned problem by jointly train all components together with a single objective, and thus simplifies the training process significantly. However, learning end-to-end models are also challenging, since
- The number of parameters is commonly in the order of millions, which makes it very easy to overfit.
- The training objective and testing metrics are commonly different due to optimization limitations, which may lead to inferior models.
We tackle these two challenges by 1) improving the regularization of the model during training, and 2) using policy learning to optimize directly on the performance metric. Both approaches are highly effective and improve the performance of the end-to-end speech model significantly.
Our end-to-end speech model
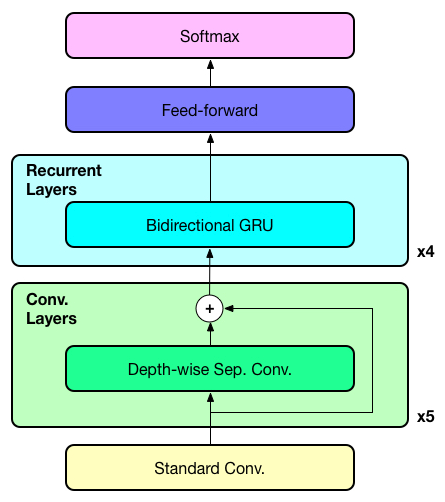
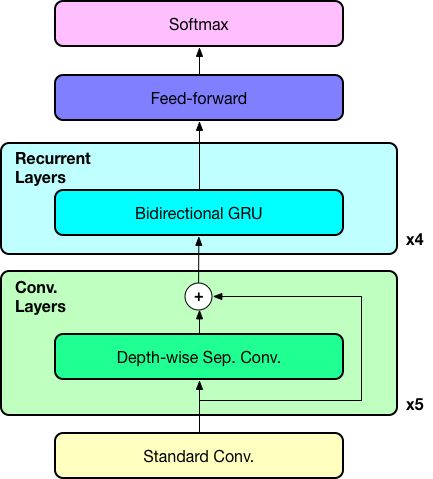
As shown in Fig. 1, our model is composed of six convolution layers and four bidirectional recurrent layers. We use depth-wise separable convolution since it is computationally more efficient, and has also demonstrated its effectiveness in various computer vision tasks. Residual connections are introduced between the covolution layers to help the gradient flow during training. Additionally, batch normalization is applied to all layers to accelerate training convergence.
Improving performance via regularization
Data augmentation is an effective method for regularizing the model. It is widely applied on image recognition tasks, where randomly cropped, rotated images are automatically generated as additional training data. Similarly, for speech recognition, we can also generate additional data by modifying the original utterences while still keep the transcription intact. Speed perturbation is a commonly used method for doing data augmentation in speech recogntion, where the play rate of the audio is randomly changed. However, in speed perturbation, since the pitch is positively correlated with the speed, it is not possible to generate audio with higher pitch but slower speed and vice versa. This may not be ideal, since it reduces the variation in the augmented data, which in turn may hurt performance. Therefore, to get increased variation in our data, we separate the speed perturbation into two independent components — tempo and pitch. By keeping the pitch and tempo separate, we can cover a wider range of variations. Additionally, we also generate noisy versions of the data. To generate such data, we add random white noise to the audio signal. Volume of the audio is also randomly modified to simulate the effect of different recording volumes. To further distort the audio, it is also randomly shifted by a small amount (i.e. less than 10ms). With a combination of the above approaches, we can synthetically generate a large amount of data that captures different variations.
Another effective regularizing strategy is dropout, which prevents the co-adaptation of hidden units by randomly zero-ing out a subset of inputs for that layer during training. The original dropout proposed by Hinton et al. works well in feed-forward networks, however, it hardly finds any success when applied to recurrent neural networks. We use a dropout variant that is specifically designed for recurrent networks from Gal and Ghahramani. In this variant, instead of randomly zero-ing out a subset of the inputs randomly across time, a fixed dropout mask is used across all time steps for a particular sample.
To investigate the effectiveness of these two regularization techniques, we perform experiments on the Wall Street Journal (WSJ) and LibriSpeech datasets. The input to the model is a spectrogram computed with a 20ms window and 10ms step size. As can be seen from table 1 below, both regularization techniques are quite effective, bring us greater than 15% relative performance improvement over baseline consistently. When we combine these two method, we get over 23% relative performance improvement across all datasets.
| Regularization Method | WSJ | LibriSpeech | ||||
|---|---|---|---|---|---|---|
| WER | Improvement | test-clean | test-other | |||
| WER | Improvement | WER | Improvement | |||
| Baseline | 8.38% | -- | 7.45% | -- | 22.59% | -- |
| +Augmentation | 6.63% | 20.88% | 6.31% | 15.30% | 18.59% | 17.70% |
| +Dropout | 6.50% | 22.43% | 5.87% | 21.20% | 17.08% | 24.39% |
| +All regularization | 6.42% | 23.39% | 5.67% | 23.89% | 15.18% | 32.80% |
Improving performance via policy learning
The end-to-end models are commonly trained to maximize the likelihood of data. The log likelihood reflects the log probability of getting the whole transcription completely correct. What it ignores are the probabilities of the incorrect transcriptions. In other words, all incorrect transcriptions are considered to be equally bad, which is clearly not the case. Furthermore, the performance metrics typically aim to reflect the plausibility of incorrect predictions. This results in a disparity between the optimization objective of the model and the (commonly discrete) evaluation criteria. For example, word error rate penalizes less for transcription that has less edit distance to the ground truth label. This mismatch is mainly attributed to the inability to directly optimize the criteria.
One way to remedy this mismatch is to view the above problem in the policy learning framework. In this framework, we can view our model as an agent and the training samples as the environment. The parameters of the model defines a policy, the model interacts with the environment by following this policy. The agent then performs an action based on its current state, in which case the action is the generated transcription and the state is the model hidden representation of the data. It then observes a reward that is defined from the evaluation metric. In this way, the likelihood of a transcription is weighted according to its reward. In other words, transcriptions that lead to higher rewards (i.e. better evaluation metric) would be preferred over the ones that result in lower rewards.
To test the effectiveness of policy learning, we conduct our experiments on the WSJ and LibriSpeech datasets. We use the best previous models as baselines and compare them against models that are trained with policy learning. It is clear from the result (see table 2), policy learning consistently improves the model performance on both datasets. Combined with the regularization techniques, we improved the model performance by ~30% on all datasets.
| Method | WSJ | LibriSpeech | ||||
|---|---|---|---|---|---|---|
| WER | Improvement | test-clean | test-other | |||
| WER | Improvement | WER | Improvement | |||
| Baseline | 6.42% | -- | 5.67% | -- | 15.18% | -- |
| Policy Learning | 5.53% | 13.86% | 5.42% | 4.41% | 14.70% | 3.16% |
Conclusion
We show that the performance of the end-to-end speech models can be improved significantly by performing proper regularization and adjustment to the training objective. In particular, we demonstrate that proper use of data augmentation and recurrent dropout leads to significant better generalization performance of the model. Additionaly, with policy learning, we can futher closing the gap between the training objective and the testing metric. Combining all these techniques we achived a relative performance improvement of ~30% across all datasets over the baseline.
Citation credit
Yingbo Zhou, Caiming Xiong, and Richar Socher 2017.
Improved Regularization Techniques for End-to-End Speech Recognition