 Blog Home
Blog HomeOn the Diversity and Explainability of Enterprise App Recommendation Systems
Recommendation systems are common in the consumer world. For example, Netflix, YouTube, and other companies use these systems to recommend items you would probably like, based on data about you - such as what items you've consumed (e.g., watched) before.
But recommendation systems are not just for consumers. Enterprises use them as well, such as to recommend apps that customers might want, based on data about what they like or actions they have taken before.
This blog presents a new framework we've developed to improve the diversity and explainability of these enterprise app recommendation systems. But before we dive into our framework, let's go over some background basics.
The Basics of Enterprise App Recommendation
Salesforce AppExchange is the leading enterprise cloud-based app marketplace for developers and independent software vendor (ISV) partners to sell the apps built on the Salesforce platform, to help customers achieve measurable business goals in the cloud. In this work, we focus on an enterprise app recommendation problem with a new business use case, which aims to find a match between these three parties:
- Independent software vendors (ISV solutions/products): ISV partners provide applications on the Salesforce AppExchange for solving specific business problems.
- Customers (buyers): Customers can purchase, download, and install these apps on the Salesforce platform to solve their own business problems.
- Sales teams (sellers): The sales teams facilitate this transaction by analyzing the customers' needs and advising them on how to better meet their goals, thereby recommending the right application to the customers. To achieve this, they recommend specific apps to the customers based on the customers' goals and behaviors.
In short, ISVs have applications, customers have business problems. and the sales teams serve as a bridge between the two, recommending applications to solve customer problems.
The Problem with Manual App Recommendation
The above process works well in theory, but in practice, it may not always lead to an optimal outcome. Various issues can arise during the process of deciding on which applications to recommend. In general, manually analyzing a customer's preferences and selecting relevant apps has a number of inherent drawbacks:
- Tedious task: The tedious nature of this process means there’s the potential for human error; some data might be overlooked or discounted and certain features might not be leveraged while making a recommendation decision, and recommendation accuracy could suffer.
- Labor intensive: Manual app recommendation takes a great deal of human effort...
- Opportunity cost: ...which costs time and money that might be better applied to a different task.
- Lack of app diversity: A manual process means a strong probability of lower app diversity, since it's almost impossible for a human to manually browse the tens of thousands of apps available in the AppExchange.
Our Solution: New Approach, Novel Framework
To address the issues outlined above, we believe a data-driven approach is a better method to conduct app recommendation, necessary to improve and optimize this task and, in particular, to increase the diversity and explainability of app recommendation.
We have developed a novel framework that achieves these improvements by both improving aggregate recommendation diversity and generating recommendation explanations.

Goals of Our Framework
Our primary goal in developing our new framework is to assist the sales team in finding apps most relevant to their customers, allowing them to interact with the system and obtain more information, such as:
- Control recommendation diversity for exploring less popular but relevant apps in real-time
- Diversity provides more exposure opportunities for app vendors/developers.
- Explain why certain apps are recommended by generating recommendation explanations
- Explainability improves the transparency and trustworthiness of the recommender system.
Framework Benefits
The benefits of our framework include:
- The proposed model is simple yet effective; it can be
- trained in an end-to-end manner
- deployed as a recommendation service easily
- Our approach
- improves aggregate diversity without much reduction in recommendation accuracy
- generates reliable explanations that are comparable with the results obtained by LIME.
- For the customer-specific app recommendation, we ensure high accuracy by leveraging various kinds of features
- Examples: single/multi-group categorical, continuous, text, and installation history
- This achieves highly competitive results compared with other state-of-the-art models (like Wide & Deep and DIN) in industrial recommender systems.
- The features include customer demographics such as industry and location as well as usage metrics, consumption, and financial metrics.
System Overview
For a specific customer, here is how our system works (the main steps taken):

- To discover which apps the customer prefers, the sales team gives the apps recommendation engine the customer (user) ID and the diversity parameter.
- The diversity parameter controls the exploration for novel apps.
- The apps recommendation engine then submits this request to the model server.
- The model server generates the top “k” recommended apps and the corresponding explanations.
- The sales team:
- Receives the response from the apps recommendation engine
- Analyzes the results with the provided explanations
- Uses their experience to determine which apps should be recommended to the customer.
Different from other recommendation tasks, the sales team can:
- Dynamically control recommendation diversity for exploring novel apps
- Obtain the corresponding recommendation explanations in real-time.
Below is a wider view of the entire system, with the previous figure seen in the lower left:

Framework Details
The heart of our solution lies in its models, which consist of two main types:
- “Relevance model” for accuracy
- “Diversity and Explanation models” (DAE models) for diversity and explainability.
The relevance model learns the “similarity” between a user and an item, while the DAE models aim to control aggregate diversity and generate recommendation explanations.
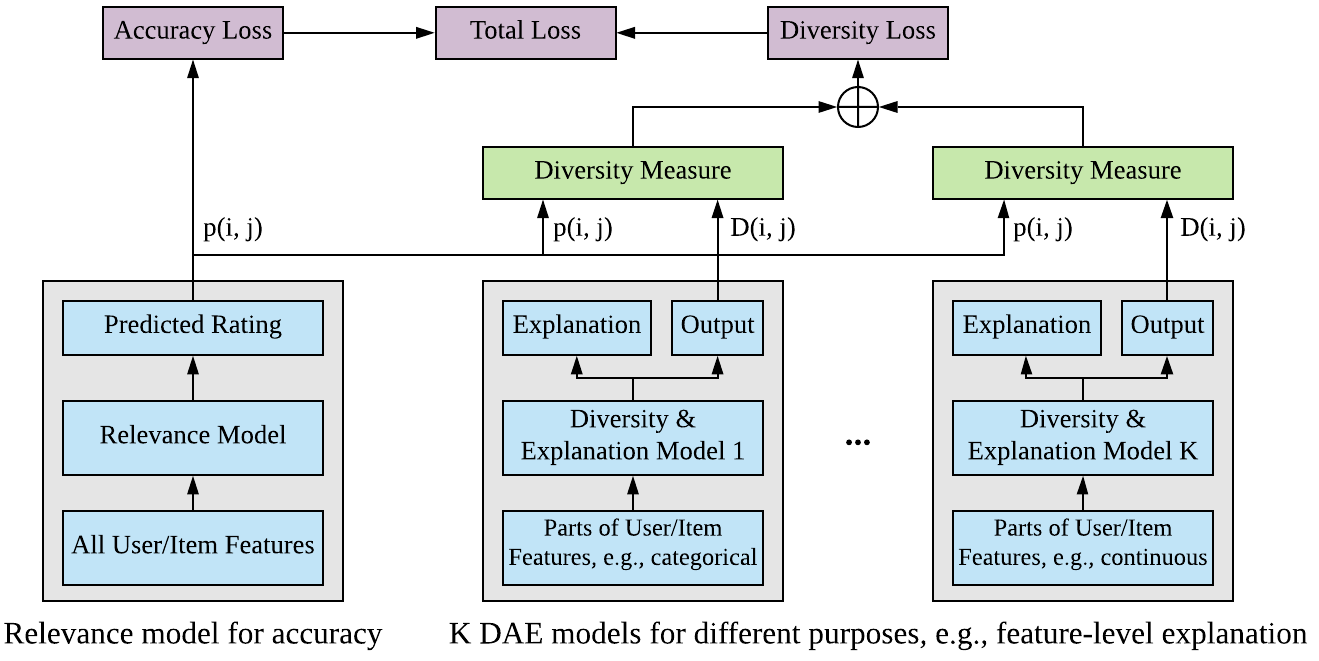
Three DAE Model Types
We designed three types of DAE models so that the sales team can judge whether the recommended apps are reasonable or not:
- “Hot” DAE model for extracting popular items: Its output measures the item popularity score. The explanation provided by this model is “item X is recommended because it is popular” if item X is in the hot item list.
- “Categorical” DAE model for categorical features, multi-group categorical features and user installation history: Its inputs include the candidate item ID and the user categorical features. It learns the feature importance score for each categorical feature. The explanation will be “item X is recommended because X has features A, B, etc.”
- “Continuous” DAE model for continuous-valued features: Learns feature importance scores for continuous-valued features. Provides explanations similar to the “categorical” DAE model.
Better (Focused) Explanations via Separate Explanation Models
One of the key innovations of our framework is to train separate post-hoc explanation models for learning disentangled explanations, meaning that each explanation model only focuses on one aspect of the explanation. For example, one model for extracting popular items, one model for feature-level explanations (highlighting important features) and another model for item-based explanations (highlighting relevant installed apps).
Each DAE model has a simpler model structure, trying to estimate the rating scores, e.g., P(i,j), generated by the relevance model. For instance, given User I and Item J, the output D(I,J) of a DAE model estimates the distribution of the rating score P(I,J). Because the DAE models approximate the rating scores, they can also be viewed as the post-hoc explanation models used to generate recommendation explanations. Suppose that we have a simple DAE model that takes item J as its input only (no User I info) and tries to approximate P(I,J), which means that this DAE model estimates the impersonalized popularity scores of the recommended items. Therefore, it is able to generate explanations such as “item J is recommended because it is popular”.
This also provides a convenient way to control recommendation diversity in real-time for exploring new apps:
- During prediction, the predicted rating of User I for Item J is P(I,J) - [w * q(I,J)]
- In this calculation (a kind of evaluation function), the bracketed quantity (factors learned by the DAE models) is subtracted from (reduces) the estimated rating score computed by the relevance model, in order to improve diversity (the formula tends to reduce the rating scores of popular items, giving more exposure to relatively unpopular items).
- Here, q(I,J) is drawn from D(I,J) — the output of the DAE models — and w controls the trade-off between diversity and offline accuracy (a larger w means more exploring for new items).
In real-world applications, if one only needs recommendations generated offline without interacting with the system, one can fix the diversity parameter in our framework (that is, keep w constant, instead of adjusting recommendation diversity in real-time) to generate recommendations and the corresponding explanations.
Examples of System Output
App Recommendation with Explanations
Here is an example of our system’s output, showing the recommended app and the corresponding explanations. Note how we provide both feature-level explanations and item-based explanations:
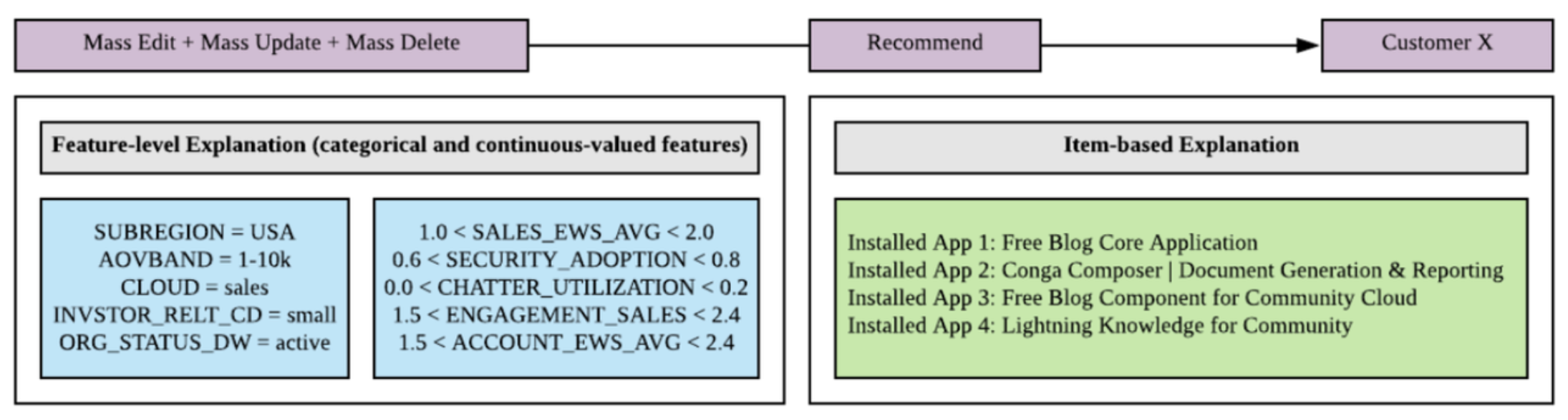
As the above figure shows, the app “Mass Edit + Mass Update + Mass Delete” is recommended to customer X, because:
- SUBREGION = USA, CLOUD = sales, etc. (Feature-level Explanation), and
- This customer has already installed “Free Blog Core Application”, “Conga Composer”, etc. (Item-based Explanation).
“Mass Edit + Mass Update + Mass Delete” is a developer tool for searching and mass editing multiple accounts, contacts, and custom objects, useful for cloud-based applications such as “Free Blog Core Application” and “Conga Composer” that handle large amounts of documents and contracts.
Closeup: Explanation
The table below shows an example of the generated feature-level explanation for the app “RingLead Field Trip – Discover Unused Fields and Analyze Data Quality”. The explanation has the template “app X is recommended because of features A, B, etc.”. We list the top 10 important categorical features learned by our model. This example shows that important features extracted by our method include CITY, COUNTRY, and REGION as well as market segment and account ID, which are reasonable for this case.
In the future, we plan to explore other types of explanations such as actionable insights, to further assist the sales team by improving explanation quality.

Sales Team User Study: Positive Feedback
In addition to supporting and funding basic AI research to benefit all of society, Salesforce also likes to apply its AI team’s innovative research to improve the company’s own operations, and so our app recommendation system has been deployed as a service for our sales teams. We did a user study of our system with our sales team and got very positive feedback. Due to privacy and confidentiality concerns, we can only show parts of our internal users' feedback, but here are some highlights:
- 88% | Overall Rating of AE Experience with App-Einstein
- 100% | Would Use This Tool
- 87% | They Trust the Information in App-Einstein
- 93% | Would Use Information Provided by App-Einstein to Engage with Their Customers
- 100% | Would Recommend App-Einstein to a friend
Some comments we received:
- “This tool is simple to use and I feel like it's another great one to have in my bag.”
- “The data is a direct reflection of what I know to be true in the account.”
Experiments: Evaluating Our Framework
We evaluated the performance of our framework on a private enterprise app recommendation dataset, using this dataset to compare our system with other approaches in terms of accuracy, diversity, and explainability.
When we compared our relevance model on the app recommendation dataset with three methods widely applied in industrial recommender systems (logistic regression, wide and deep model, and DIN model), our performance was either comparable to or better than the other three methods, using the accuracy metrics hit ratio (proportion of recommended apps that a user actually wants) and NDCG (compares different ranking functions to decide which is best). In addition, the experimental results demonstrated the importance of leveraging user installation history in our task, and verified the effectiveness of our model’s special module for learning item representation.
The next experiment evaluated the ability to control recommendation diversity. We compared our approach with different re-ranking methods: Reverse Predicted Rating (RPR), reverse click/installation counts (RCC), 5D ranking, and DIN model.
The aggregate diversity is measured by two metrics:
- the number of unique recommended items among all the users
- the average distance between the recommendation results of two different users.
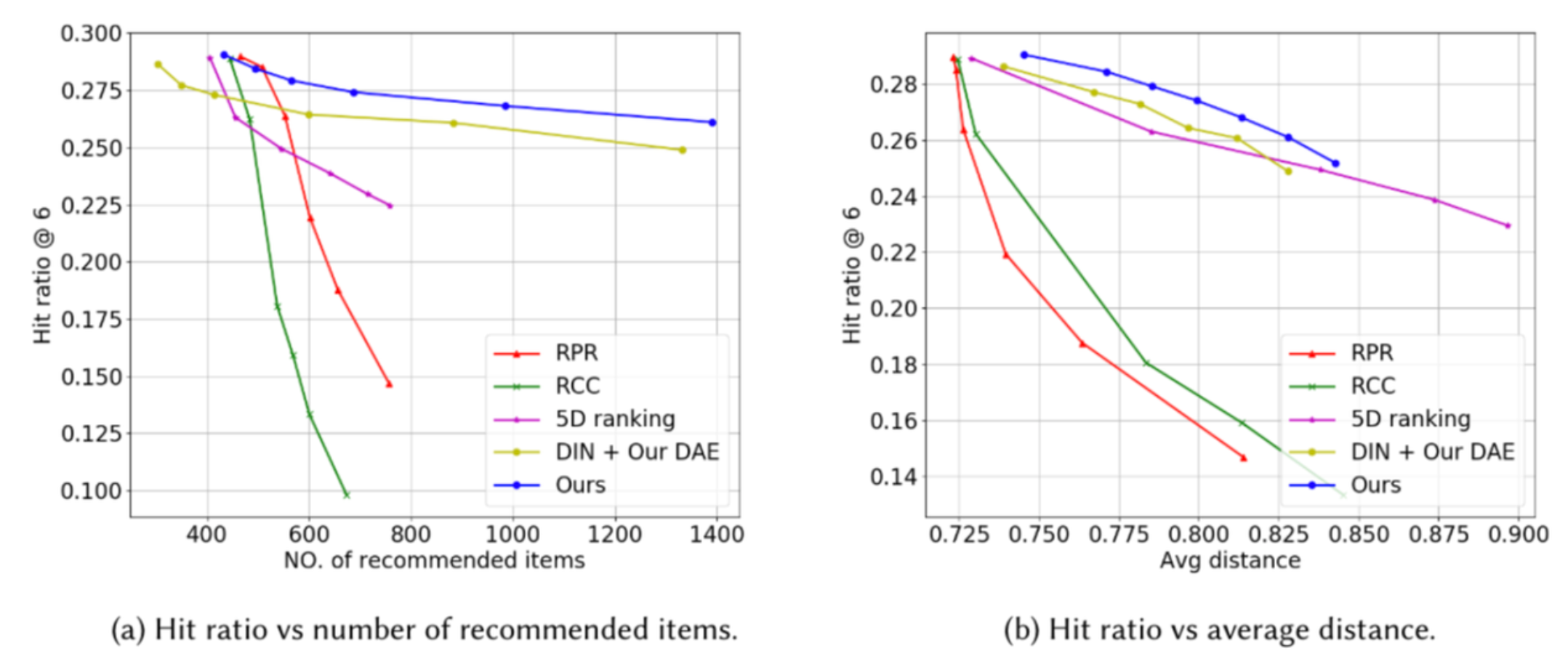
The above figure shows the comparison between our approach and the re-ranking methods. For the app recommendation dataset, our method performs much better: it can recommend about 1000 items without reducing the hit ratio much, while the re-ranking methods can only recommend about 800 items at most with a certain level of accuracy.
Note that we also conducted the experiments by replacing our relevance model with DIN (“DIN + Our DAE”, yellow line), and the results mirrored those of our original unaltered system (blue line), demonstrating that our framework can support other recommendation models as well.
The Impact
The above experiments validated the efficacy of our approach, and the latter result was especially impactful. We saw that, for the app recommendation dataset, our method can recommend about 1000 items without an appreciable reduction in the hit ratio. The encouraging upshot of this is that using our approach enables you to increase the diversity of app recommendations, without a marked decrease in performance.
The experiments also showed that our DAE models can be successfully combined with other recommendation models, by simply replacing our relevance model with a different one. This is also an impactful result, because it demonstrates that our framework can be applied to other generic recommender systems for both improving diversity and generating explanations.
The Bottom Line
- In app recommendation, sales teams are the bridge connecting developers (ISVs) and their apps with the customers who apply them to solve business problems. Our recommender system acts as an intelligent assistant to the sales team, helping recommend relevant apps to customers for their businesses and increasing the likelihood of improving sales revenue.
- In addition to recommendation accuracy, recommendation diversity and explainability are equally (if not more) crucial, since they provide more exposure opportunities for app developers and improve the transparency and trustworthiness of the recommender system.
- To enable sales teams to explore unpopular but relevant apps and understand why such apps are recommended, we propose a novel framework for improving aggregate recommendation diversity and generating recommendation explanations, which supports a wide variety of models for improving recommendation accuracy. Two main keys to our framework:
- We train separate explanation models for learning disentangled explanations (each explanation model only focuses on one aspect of the explanation).
- When our DAE model learns item popularity scores, it has a function that reduces the rating scores of popular items, leading to increased app diversity (in other words, this built-in function is designed to give more exposure to relatively unpopular items).
- The model in our framework is simple yet effective, can be trained in an end-to-end manner, and can be deployed as a recommendation service easily.
- Experiments on public and private datasets demonstrated the effectiveness of our framework and solution.
Acknowledgments
This blog is based on a research paper (“On the Diversity and Explainability of Recommender Systems: A Practical Framework for Enterprise App Recommendation”) that appears in Proceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM 2021).
Explore More
- Read more details about our research in our research paper
- Contact Wenzhuo Yang at wenzhuo.yang@salesforce.com
- Follow us on Twitter: @SalesforceResearch , @Salesforce
- Visit our main website to learn more about all of the exciting research projects Salesforce AI Research is working on: https://www.salesforceairesearch.com
About the Authors
Wenzhuo Yang is a Senior Research Engineer at Salesforce Research, who focuses on solving real-world problems with advanced machine learning techniques. His interests include recommender systems, explainable AI, and time series analysis.
Vena Li is a Director of Applied Research at Salesforce Research. Her research interests include recommender systems, autoML, and data-centric AI. She leads both research as well as cross-organizational collaborations to bring AI to production.
Steven C.H. Hoi is currently the Managing Director of Salesforce Research Asia at Salesforce and oversees Salesforce's AI research and development activities in APAC. His research interests include machine learning and a broad range of AI applications.
Donald Rose is a Technical Writer at Salesforce AI Research. He works on writing and editing blog posts, video scripts, media/PR material, and other content, as well as helping researchers transform their work into publications geared towards a wider (less technical) audience.