 Blog Home
Blog HomeAligning Diffusion Models to Human Preferences

TLDR
Learning from human preferences, specifically Reinforcement Learning from Human Feedback (RLHF) has been a key recent component in the development of large language models such as ChatGPT or Llama2. Up until recently, the impact of human feedback training on text-to-image models was much more limited. In this work, Diffusion-DPO, we bring the benefit of learning from human feedback to diffusion models, resulting in a state-of-the-art generative text-to-image model. This closes the gap between the StableDiffusion family of open-source models and closed models such as Midjourney v5 (the most current at the time of this project) and opens the door to a new generation of aligned text-to-image models.
In summary:
- We adapt the Direct Preference Optimization (DPO) training method to text-to-image models
- DPO-tuned StableDiffusion-XL models far outperform their initialization and are comparable to closed-source model such as Midjourney and Meta’s Emu
- Public implementations of the training code and resulting models
Introduction
The story of alignment (i.e. alignment with human goals/preferences/ethics) in Large Language Models (LLMs) is very different than alignment in text-to-image (T2I) models. While the most powerful current LLMs such as GPT4, Bard, and Llama2 all specifically cite alignment via RLHF as a key component of their training preferences, state-of-the-art T2I models are primarily trained via a single simple objective: learning to denoise images. In some cases, such as the StableDiffusion family of models, a second stage of learning to denoise visually appealing imagery is used to bias the model towards “higher aesthetic value” generations. While useful, this is a stark contrast between LLMs and T2I models. The field of the former has many recipes for incorporating human feedback into their models with huge benefits, while the latter largely has empirically justified or ad hoc approaches.
Method: Diffusion-DPO
One of the key differences in diffusion (T2I) generation from language generation is what the incremental unit of generation is. In LLMs it’s a single token (word, word-part, or other chunk of text) which ultimately will be a part of the final generation. In diffusion models, each incremental model decision steers a noisy generation towards a clean denoised version (see our blog on prior work EDICT for more of an introduction to diffusion models). This means that there can be many paths to the same image, which changes the meaning and importance of sequential diffusion steps.
To consider how to apply RLHF to diffusion models, we turned to a recent development in preference tuning for LLMs called Direct Preference Optimization (DPO). DPO enables directly learning a model to become “optimal” with respect to a dataset of human preferences which greatly simplifies the RLHF pipeline. This is a much simpler framework than traditional RLHF methods which require learning a “reward” model to evaluate and critique the generative models outputs. The DPO objective boils down to a simple criteria: tune the model to be more likely to output the preferred data and less likely to output unpreferred data.
The key math behind Diffusion-DPO is formulating what “more likely” means for diffusion models. The conclusion (after some chunky math) turns out to be pretty simple: diffusion models are trained to denoise images and if you give a diffusion model a noisy image to denoise the “likelihood” of the clean image scales with how good of a denoising estimate your model made. In other words, the DPO-Diffusion objective is tune the model to be better at denoising preferred data and relatively worse at denoising unpreferred data.
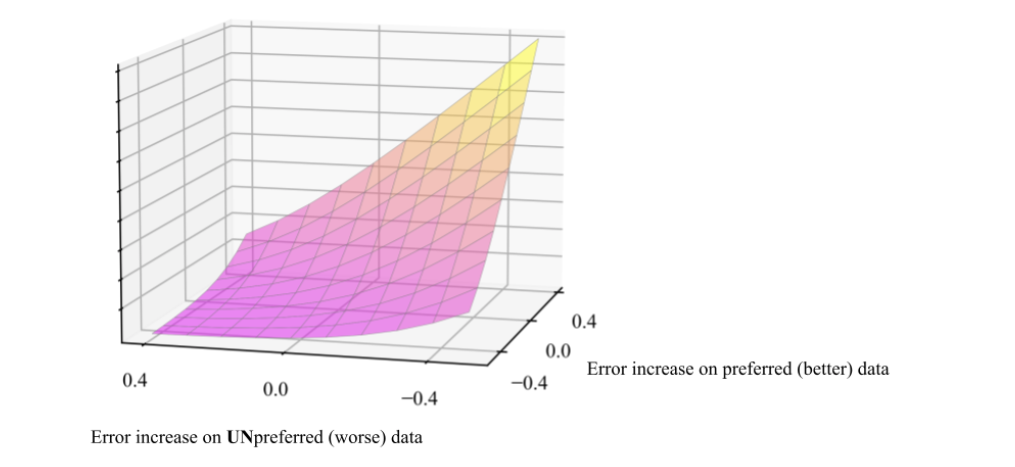
The error increase/decrease (getting better/worse) is measured by performance relative to a “reference” or initialization model. In our experiments we mainly use StableDiffusion-XL-1.0, we’ll just refer to this specific model as “SDXL”. We use SDXL as a starting point and train it on the Pick-a-Pic dataset which consists of collected pairs of preferences between two generated images from the same caption.
Results
We first visually compare the generations of our DPO-tuned SDXL model (DPO-SDXL) with the original SDXL. We see that DPO-SDXL is both more faithful to the given prompt and produces extremely high-quality imagery which is very pleasing to humans, in other words the model has become aligned to our preferences! Note that preferences are not universal, but it seems like a love for detailed exciting imagery is a common shared preference across a broad swath of users.

To rigorously test our model, we use two prompt benchmarks: PartiPrompts and HPS. These are prompting benchmarks for 1632 and 800 captions respectively. We generate SDXL and DPO-SDXL images for each caption, and ask 5 human labelers to vote on which they
- Generally like better
- Find more visually appealing
- Think is better aligned to the target prompt
We collect 5 responses for each comparison and choose the majority vote as the collective decision.

We see that DPO-SDXL significantly improves on SDXL, winning approximately ⅔ of the time.
Comparison to state-of-the-art closed-source models
While our results on the academic benchmarks demonstrate the effectiveness of aligning diffusion models to user preferences, we also want to understand if the alignment process helps close the gap on powerful closed-source models. Closed-source models like Midjourney and Meta’s Emu have been shown to be able to generate significantly better images than the open-source alternatives. We now explore if DPO-tuned SDXL is competitive with Midjourney and Emu. Since their training datasets and (in case of Midjourney) training recipes are not available, these are not apples-to-apples comparisons, but rather an effort to document the relative performance of different models.
Midjourney is a very powerful and popular closed-source text-to-image generation system known for the high quality of its generations. We evaluate how SDXL and SDXL-DPO compare with Midjourney in terms of user preferences. We compare these models to Midjourney 5.1 (the latest model available at the time of our experiments) using a collection of 346 Midjourney-generated images hosted on Kaggle. We generate images using SDXL and SDXL-DPO using the same prompts and ask crowdworkers to choose an image between Midjourney and SDXL in pairwise preference, by asking the following question: “Which image do you prefer?”. We collect 5 responses for each comparison and choose the majority vote as the collective decision.
Users prefer Midjourney 5.1 to SDXL by a substantial margin (58% to 42%), but after tuning SDXL with DPO, user preference for SDXL improves significantly — SDXL-DPO is selected over Midjourney 51% of the time. These results indicate that DPO-tuning enables an open-source model to match the performance of the powerful closed-source Midjourney models.
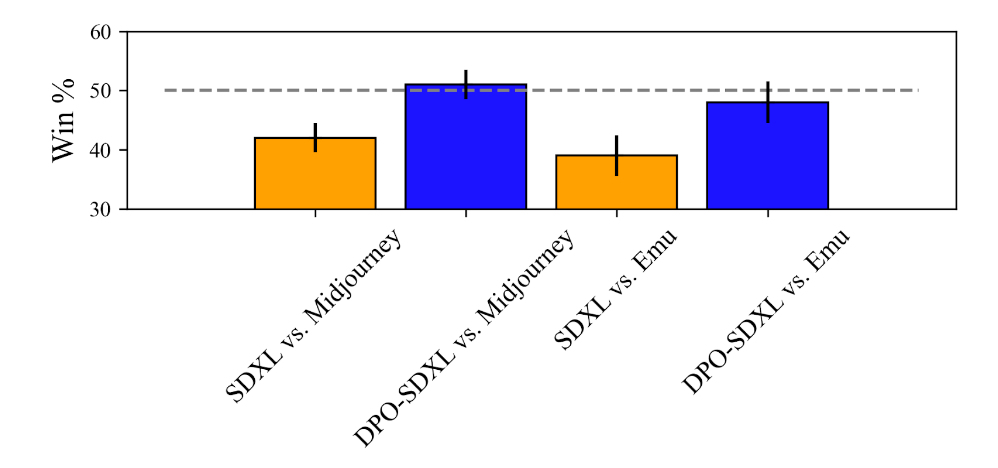
Next, we compare SDXL and SDXL-DPO to Emu, a recent model developed and hosted by Meta. We compare the models using a 200 caption randomly selected subset of Partiprompts (browser interaction is a slow way of collecting data) by employing the same crowdsourcing protocol used for Midjourney. Emu is preferred over vanilla SDXL by a significant margin (61% to 39%), mirroring the results reported in the Emu paper. In contrast, SDXL-DPO is able to close down the gap to Emu. Emu is preferred by a much narrower margin to SDXL-DPO (54% to 46%) and in fact, the breakeven point falls within the 1-standard-deviation error bar.
These results demonstrate the power of preference learning in diffusion models. Despite training in an offline set-up on a limited dataset, Diffusion-DPO closes the gap between the state-of-the-art open-source and closed-source models.
Real-time Generation: Diffusion-DPO goes Turbo
Diffusion models can be sped up by distilling their knowledge through an additional process that enables generation of realistic images with only a few function calls. The preeminent model of this class is SDXL Turbo which generates images in only 1-4 steps. DPO also can benefit this type of model a lot. Using the exact same DPO loss (just modifying some of the settings to align with the original SDXL Turbo training) we're able to substantially improve SDXL Turbo's 4-step generations.The development of this model is still in progress, but the early version shown here wins 55% of the comparisons on PartiPrompts.
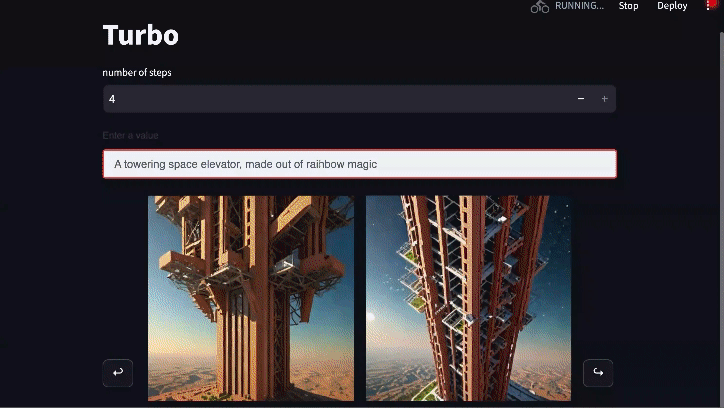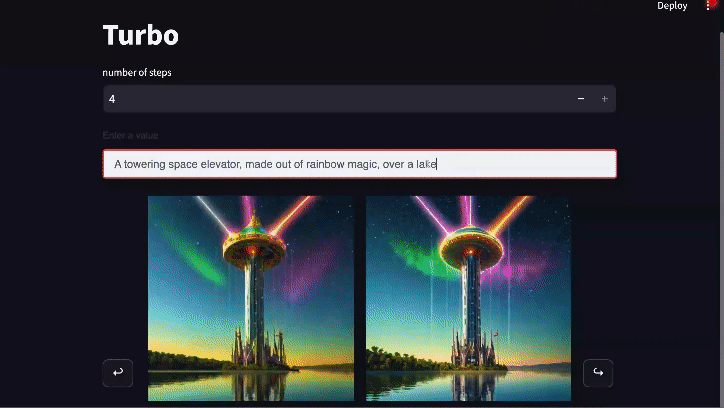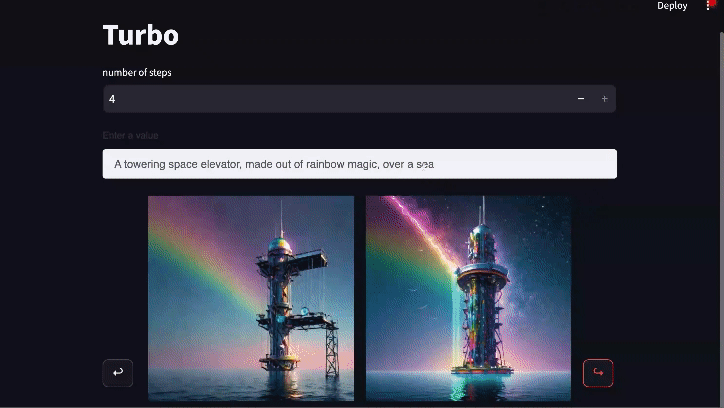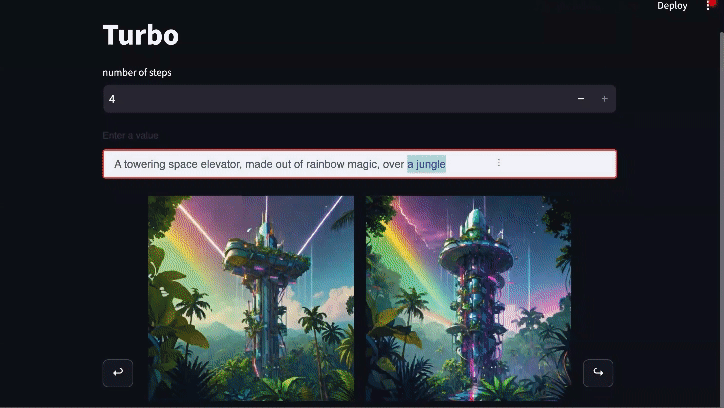

Video link for full-length version of above gif (2x speed from original)
Emergent areas of improvement
One of the most common complaints about AI-generated images is the appearance of people. As humans, aberrations in rendered human appearance really stand out to us. Interestingly, we see that these preferences are reflected in our training dataset which result in substantial improvement on people generation as shown below. Given that these changes are fairly incidental as part of generic alignment, targeted improvement is an exciting path for future development.

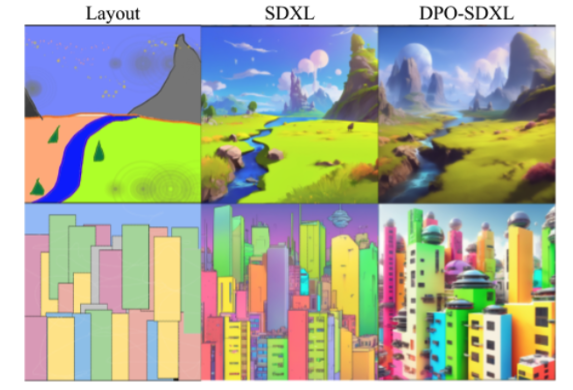
Generation from color layouts
Stroke-based generation using SDEdit is an interesting testing ground of our model’s learned tendencies. In this setting a color layout (left) is used as a reference in generating an image according to the prompts Fantasy landscape, trending on artstation (top) and High-resolution rendering of a crowded colorful sci-fi city (bottom). DPO-SDXL generates much more visually exciting imagery than the initialization model SDXL.
The bottom line
- Diffusion-DPO enables alignment of diffusion models to human goals/values
- This training process closes the performance gap of StableDiffusion-XL-1.0 to closed-source frameworks such as Midjourney v5 or Emu.
- Common complaints such as person generation emerge as improvements when training on human preferences
Looking ahead, there are many paths that preference optimization in diffusion models will go down. The work presented here is still practically at a proof-of-concept scale: it’s expected that pushing the scale of training could even further improve models. Furthermore, there are many varieties of preference/feedback that can be used here. We only covered generic human preference here, but experiment from our paper that attributes such as text faithfulness or visual appeal can be dedicatedly optimized for. That’s not even considering more targeted objectives such as personalization. RLHF has been a huge and rapidly growing field in language models and we’re extremely excited to both continue developing these types of diffusion approaches and seeing works from the broader research community as well.
The authors of the research paper discussed in this blog were Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik.
Explore More
Models: Trained and released by Meihua Dang SDXL SD1.5
Code: Integrated into diffusers: https://github.com/huggingface/diffusers/tree/main/examples/research_projects/diffusion_dpo
Paper: Arxiv