 Blog Home
Blog HomeEDICT: Accurate Text-Guided Image Editing with Diffusion Models
TL;DR: Text-to-image diffusion models are very adept at generating novel images from a text prompt, but current adaptations of these methods to image editing suffer from a lack of consistency and faithfulness to the original image. Many of these discrepancies can be traced to the difficulty of inverting the process of image generation. We present a new drop-in algorithm called Exact Diffusion Inversion via Coupled Transformations (EDICT) that performs text-to-image diffusion generation with an invertible process given any existing diffusion model. Using intermediate representations inverted from real images, EDICT enables a wide range of image edits—from local and global semantic edits to image stylization—while maintaining fidelity to the original image structure.
Background
Recently, the world of image generation has exploded with the introduction of extremely powerful text-to-image models. These models are neural networks that take description text as input and produce a corresponding picture such as those below from StableDiffusion.

These models aren’t one-trick ponies; they also can be used to edit existing images! This is the aspect that we’ll dive into and show some exciting improved abilities courtesy of our new method called EDICT (check out our paper for more technical discussions, this blog will keep things pretty light).
First, let’s talk about what these neural networks do to generate an image from some text. The class of models we’re talking about today (Diffusion Models) have been trained to recover an image from noise (static); given an image with noise added (what we call a “noisy image”) and a description of the image, the model returns a cleaned-up version of the image.

Left: The target image the model is trying to recover. Right: Noisy versions of the image fed to the model with the given caption below.
How does denoising images help generate new images? The trick is that when we want a totally new generation, we can just give the model a pure noise image and tell it a description of what we want to see. The network hasn’t been trained to ever not find anything, so it will hallucinate out a real image from the noise! Instead of doing this process in one step, we take incremental sequential denoising steps to allow the network to craft finer-grain details. Here’s an example with the same caption as above:

Motivation
Image editing turns out to, in many ways, be a tougher problem than image generation. The key issue is one of expectations: if I ask a model to produce “A cat surfing”, I’m usually happy with the resulting image as long as it contains a cat surfing. I don’t care what kind of cat it is, whether it’s standing (in proper surf form) or falling into the water (as is this author’s typical surf form).
If I ask for an image to be edited, however, I want a lot of aspects of the image to remain the same. Let’s say I have a photo of a dog surfing, and I want to edit this particular photo to be a cat surfing;

I’m going to be a lot more picky about the edit! It would be nice if the surfboard stayed the same color, the lifejacket the same pattern, and the water the same shape. This pickiness is hard to enforce though - recall from above that these models are trained to recover images from noise. To edit an image, you add noise to that image to make it look like a partial generation, and then perform generation with the new text criteria.
So how do we find the noise to add? The main method used, called img2img in the community and SDEdit formally, simply adds random noise (again, static) to the image and performs the generation like so. Check it out below:

This works pretty well, but we also lose a lot of the detail in the waves and lifejacket. In creating EDICT, we wanted to come up with an editing method that really focused on maintaining those fine details. And here’s our result!

So what powers this new approach?
Edification: EDICT Edits
The core idea behind EDICT is simple: instead of adding noise at random to get the intermediate representation, we want to find a “noisy” image that will exactly result in the original image if we give it the original prompt and perform the generation process. The intuition is that if we then tweak the text slightly (such as changing Dog→Cat) while keeping the rest of the sentence the same the unchanged text will result in unchanged imagery. The generation process should play out as before, except with a dog instead of a cat.

To find such a “noisy” image the generation process can be reversed. We still ask the network “what noise should I remove here?”, but instead of actually removing the noise, we add a copy of that noise in and then query the model again with the now-noisier image. This baseline sometimes works, but is really unstable as seen below.

This is because the model won’t exactly make the same decision at slightly different points. These errors propagate causing rather large errors as we see above.
This process can be stabilized by not giving the model text to decode with (this is called unconditional inversion), however we lose a lot of detail since the model has a lot of latitude to make new decisions given the new prompt. Notice that the patterns on the surfboard and lifejacket are both gone, as is the wave texture:

In EDICT, we make the conditional (text-based) inversion exact. We do this by making two copies of the image and alternately updating each one with information from the other in a reversible way. We describe this as Exact Diffusion Inversion via Coupled Transforms, which is where the name EDICT came from.

You can think of this like a game of leapfrog - x leapfrogs over y going forwards, but if x wants to go backwards it can look over its shoulder and see where y is, thus figuring out where it (x) must have been previously.

And here’s the result!
We see that the reconstruction works perfectly in the top row, and in the bottom row we get an edit that preserves the non-cat details. Success!

Results
We’ve seen Dog→ Cat, what about Dog→ A specific breed of dog? Here we try with a half-dozen different breeds:

These examples are really interesting because it shows how much EDICT preserves the background in the first and third row or the text at the bottom.
EDICT can do more than just change domestic mammals to other domestic mammals though, it can also do:
Content addition (Adding something to a scene)

Context changes (preserving an object and putting it into a new scene)

Pose changes (deforming an object into a new shape, this is extremely challenging for diffusion-based methods!)
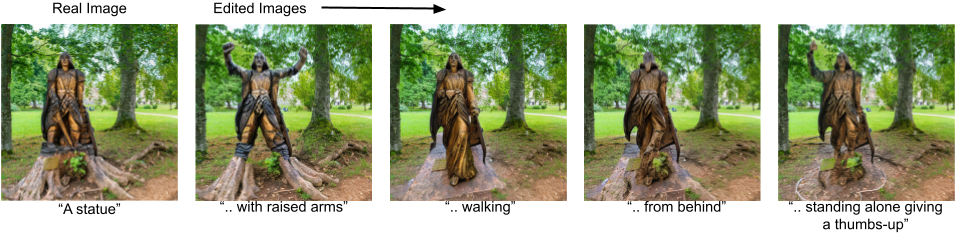
Style changes (keeping the depicted content the same but in a different media or setting)

Deeper Dive
We’ll use this section to talk more concretely about the math behind EDICT. Generally, a image generation diffusion step has the equation:
x’ = a * x + b * f(x)
where a and b are set coefficients, x is the (currently noisy) image, and f(x) is a noise-finding function. As these steps get smaller, x and x’ at any given step aren’t too different from each other, meaning f(x) and f(x’) are closer together too.
Normal diffusion inversion approximately solves for x in the above equation as:
a* x = x’ - b * f(x) → x = (x’ - b * f(x) ) / a
We can’t know f(x) if we don’t know x, so f(x’) is substituted in.
x ~= (x’ - b * f(x’) ) / a
Now in practice, as we saw, this process doesn’t work so well when f is relying on a text description too.
We want to be able to work with complex and dynamic functions f without sacrificing stability. To do so, we copy x into another sequence y and follow the update rule.
x’ = a * x + b * f(y)
y’ = a * y + b * f(x’)
Now consider us having, x’ and y’, can we solve for x and y? The answer is yes!
y = (y’ - b * f(x’) ) / a
x = (x’ - b * f(y) ) / a
So this process is exactly invertible no matter how many steps we take! We do find that the sequences x and y can drift apart in practice; we assumed f(x) and f(y) were nearly equal which is similar to the assumption on f(x) and f(x’) that we saw derail naive inversion attempts. To mitigate this problem, we also introduce averaging steps to improve consistency (see our paper for further discussion).
In total, this gives us a process that closely mirrors that of the normal diffusion process, but all while being fully invertible.
Impacts
Editing is generation with expectations of consistency and EDICT offers a way to maintain that consistency while performing a variety of edits. Up to this point, editing techniques have struggled much more with being faithful to the original image while incorporating the desired edits.
From a business perspective, EDICT will help graphic designers by offering a low-input way to make sophisticated edits. Many content-preserving editing tools require manual masking, while EDICT achieves this solely through text input. This can greatly reduce user input time and can even automate entire classes of edits.
There is also an increasingly large artistic community growing around generative AI, with many text prompts being extremely intricate to achieve the desired results. The structure of text fed to EDICT for editing allows for changing small aspects of a description while preserving the other elements; this fine-grain control should speed up and enhance artistic generative AI cycles.
There are ethical considerations that need be noted. EDICT can be applied to any diffusion model, and diffusion models can be trained on any type of image data. Even typically used datasets can contain biases such as those concerning gender or race; and results from EDICT will reflect the biases of the pretrained diffusion model that it is paired with. Additionally, EDICT is just an algorithm and has no filter for inappropriate or harmful images if the text-to-image model that it is based on does not either. Inappropriate content or misinformation could be generated by this algorithm if paired with such a model and disseminated as real.
The Bottom Line
- Text-to-image generation models are rapidly improving, but specialized techniques are need to enable text-guided image-to-image generation.
- Inverting the generative process of diffusion models offers a way to change some aspects of the content while preserving others.
- Prior to now, the inversion process was inexact and had a severe tradeoff of stability/realism with faithfulness to the original image.
- By tracking two copies of the image instead of just one, we are able to achieve exact inversion using a method we call Exact Diffusion Inversion via Coupled Transforms, or EDICT for short.
- EDICT allows for a large range of edits that preserve non-edited components of the image.
There will be more applications of invertible diffusion processes outside of image editing. Inverting collections of real images to noise can allow us to study the collections of corresponding noise (known as the latent space) and gain better understandings about the workings of diffusion models. Invertibility is a very mathematically useful property, so there are tons of applications!
Explore More
Code: https://github.com/salesforce/EDICT
About the Authors
Bram Wallace is a Research Scientist at Salesforce AI. His research focuses on both generative and discriminative vision-based multimodal learning. He particularly enjoys working with methods and models that can be applied/adapted to a broad variety of tasks.
Akash Gokul is an AI Resident at Salesforce AI. He is currently working on improving multimodal generative models.
Nikhil Naik is a Director of Research at Salesforce AI. His research interests are in computer vision, natural language processing, and their applications in sciences. His current work focuses on generative modeling and multimodal representation learning.
Glossary
- Text to image generation: The process of creating an image from scratch which matches input text
- (text-guided) Image editing: The process of creating a new version of a given image which matches input text
- Noise: Random changes to some quantity; can think of adding static (gaussian white noise) to an image
- Diffusion models: A class of neural network models that have been trained to denoise images given a description of the content. These can be used for text-to-image generation by feeding them a description along with an image of pure random noise
- Invertible function: A function where the inputs are exactly recoverable from the outputs.