 Blog Home
Blog HomeUnify Profiles with Salesforce Data Cloud Identity Resolution Soft-Matching






Salesforce Data Cloud, the first real-time CRM, is turning your data into real-time customer magic. You might have witnessed how our AI research is powering intelligent experiences with Identity Resolution for Fuzzy Matching featured at Dreamforce.
The goal of identity resolution is to identify the same individuals across datasets and unify their profiles. But, this can be a challenging problem. Data collected from multiple sources can be erroneous, contain different features, and sometimes, an individual may be represented by numerous variations on their name. For example, in one data set, there may be an individual named “Mr. John Smith” and in another data set, that same individual may be “J. Smith”. Matching on first names is a challenging component of identity resolution. Using state-of-the-art large language models (LLMs), we have enabled this critical component, which we call fuzzy first-name matching.
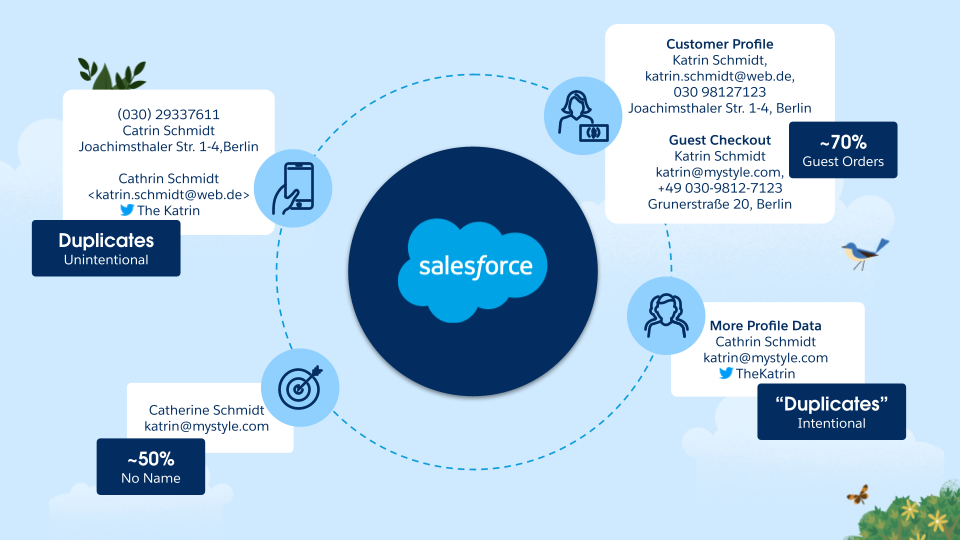
And now, we’ve enhanced user customization and control in fuzzy first name matching with soft-matching, generally available today! Our soft-matching capability generates a score for pairs of names that indicates the confidence that the pair represents the same person. For example, the pair “Susan” and “Sue” will have a high confidence score, whereas the pair “Susan” and “Michelle” will have a much lower confidence score.
Generating scores for name pairs gives users the flexibility to choose the rigor of their fuzzy match criteria based on their specific use cases. Across industries or domains, customers face different identity resolution requirements. In the medical field, for instance, the risk of confusing Johnathan Smith’s records with those of John Smith could be detrimental. On the other hand, an industry such as retail might be more flexible and want to ensure users fall into as many relevant segments as possible.
Now, let’s take a closer look at how our soft-matching works. After configuring data sources, users can now choose the level of rigor for fuzzy first name matching. The levels of rigor from which to choose are low precision, medium precision, and high precision. Below we show some examples of low, medium, and high-precision matches.
To develop this new soft-matching capability, we enhanced our previous fine-tuned LLM with an additional regularized multilayer perceptron (MLP). This MLP was trained to align name-pair similarity scores and embeddings produced by our fine-tuned LLM with labeled first-name pairs. Our approach is also supported by enhanced domain-specific rules.
With first name soft-matching together with matching rules on important features such as address and phone number, we have delivered the flexibility our customers covet with the performance they expect. Check out our soft-matching capability today!
Acknowledgments:
- Salesforce AI: Shelby Heinecke, Zhiwei Liu, Huan Wang, Vera Serdiukova
- Data Cloud: Anthony Yeung, Shouzhong Shi, Torrey Teats, Stanislav Georgiev, Suresh Thalamati, Blake Cecil, Erin Wagner Tidwell
Explore More
Salesforce AI invites you to dive deeper into the concepts discussed in this blog post (links below). Connect with us on social media and our website to get regular updates on this and other research projects.
- Project site: www.salesforceairesearch.com/projects/data-cloud-identity-resolution
- Salesforce AI Website: salesforceairesearch.com
- Follow us on Twitter: @SFResearch, @Salesforce