 Blog Home
Blog HomeWeighted Transformer Network for Machine Translation
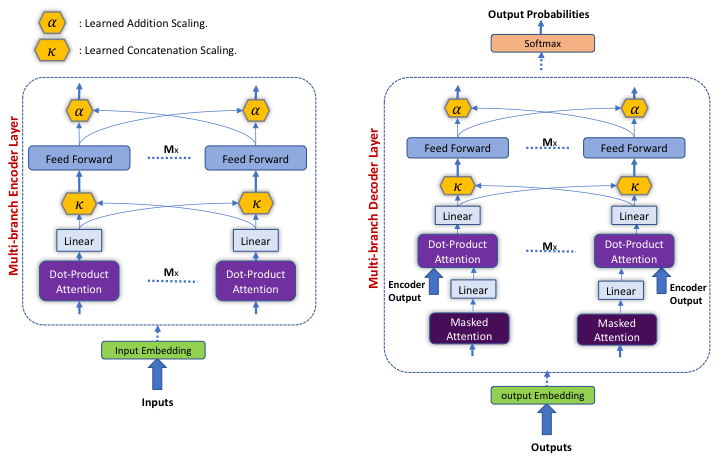
Most neural architectures for machine translation use an encoder-decoder model consisting of either convolutional or recurrent layers. The encoder layers map the input to a latent space and the decoder, in turn, uses this latent representation to map the inputs to the targets. Such sequence-to-sequence tasks have been quite successful in a variety of applications beyond machine translation, including summarization and speech recognition. These models, due to the high cost of convolution or recurrence computation, tend to have high per-iteration cost. The Transformer network proposed by Vaswani et al. (2017) was able to avoid recurrence and convolution and used only self-attention and feed-forward layers, which tend to be relatively faster. Specifically, the authors use several independent heads of self-attention in each layer to map the input sequences. Using this architecture, the authors demonstrate a greatly improved performance along with orders-of-magnitude faster training time. However, despite this success, the Transformer network still requires a large number of parameters and training iterations to converge. We propose the Weighted Transformer, a Transformer with modified attention layers, that not only outperforms the baseline network in BLEU score but also converges 15 − 40% faster. Specifically, we replace the multi-head attention by multiple self-attention branches that the model learns to combine during the training process. The complete model is shown in Figure 1, and the modified self-attention layer in Figure 2. Our model improves the state-of-the-art performance by 0.5 BLEU points on the WMT 2014 English-to-German translation task and by 0.4 on the English-to-French translation task.
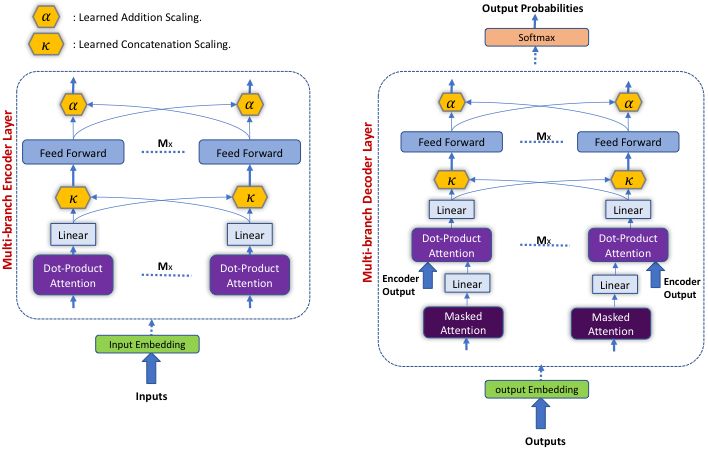
The weighted transformer
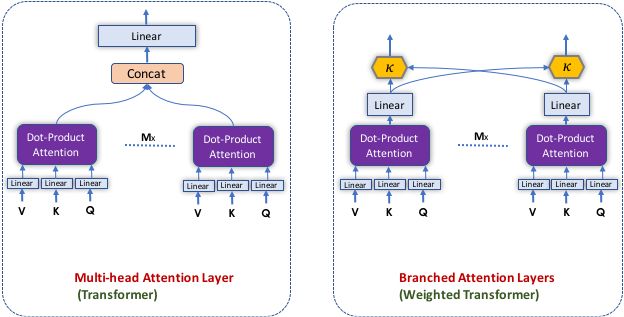
The proposed Weighted Transformer gives importance to different attention heads and feed-forward branches via two types of layers, the Concatenation Scaling layer (κ) and the Addition Scaling layer (α). We require each of these variables to be non-negative and also add to 1. Due to this, the values for the variables can be interpreted as selection probabilities that the model learns to modify. In Figure 1, κ can be interpreted as a learned concatenation weight and α as the learned addition weight. The role of κ is to scale the contribution of the various heads before α is used to sum the feed-forward branches in a weighted fashion.
The Concatenation Scaling layer contains a set of M scalar weights, where M attention heads are fed as an input to this layer. During the forward propagation, each attention head output tensor is multiplied by the corresponding scalar single weight. Then, all the outputs from this layer are concatenated to each other in the same input order. Similarily, the Addition Scaling layer contains a set of M scalar weights, where M is the number of feed-forward branches fed as an input to this layer. During forward propagation, each feed-forward branch output is multiplied by the corresponding scalar single weight. Afterwards, all outputs from this layer are added together and normalized. This in turn eases the optimization process and cause the branches to learn decorrelated input-output mappings which reduces co-adaptation and improves generalization. Additionally, using the Concatenation Scaling and the Addition Scalingdon't add significant number of parameters to the network.
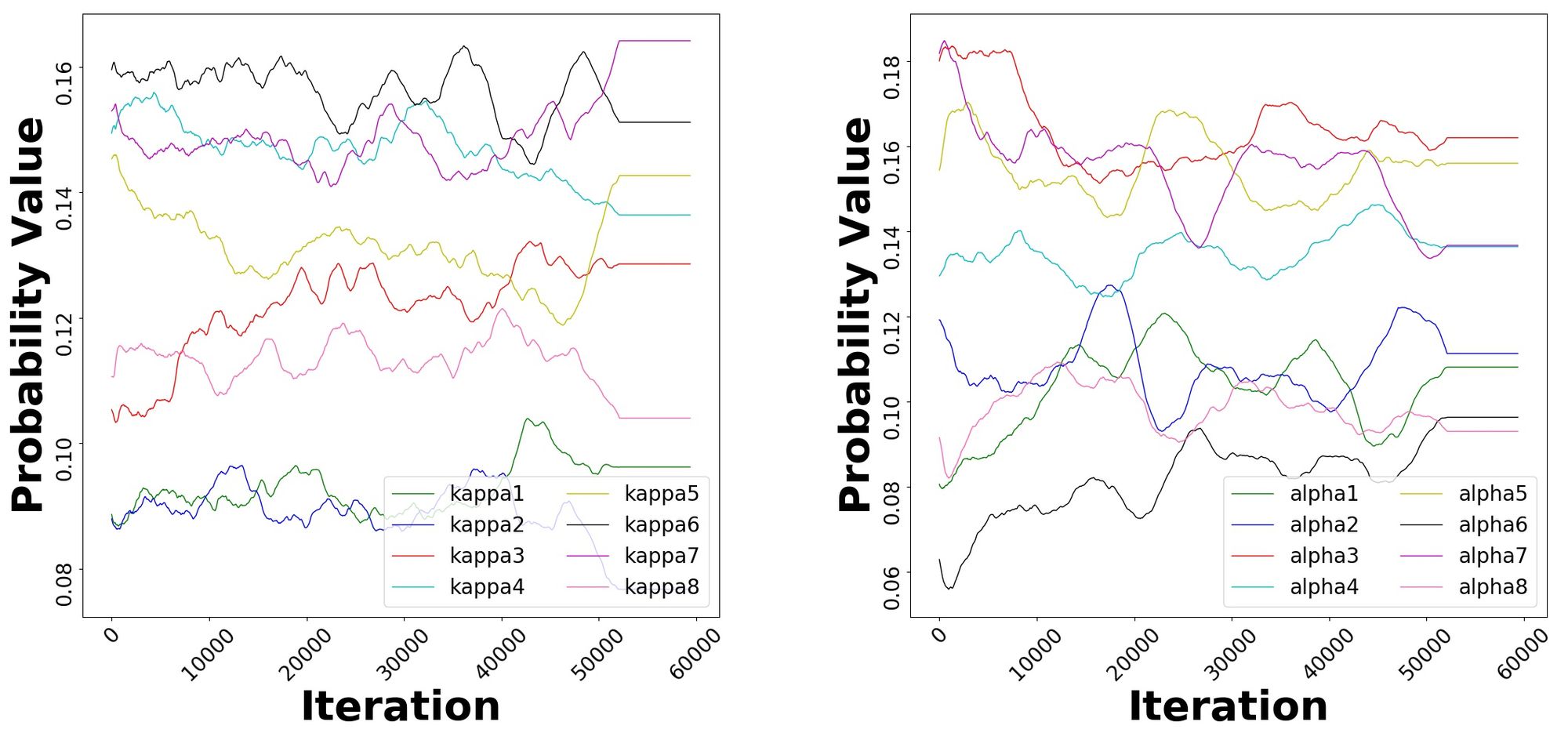
In Figure 3, we present the behavior of the weights (α, κ) of the second encoder layer of a Weighted Transformer model for the English-to-German newstest2013 task. We notice that in terms of relative weights, the network indeed prioritizes some branches more than others. Further, the relative ordering of the branches changes over time suggesting that the network is not purely exploitative. A purely exploitative model would prefer a subset of the branches throughout the training process. This is undesirable since it reduces the effective capacity of the network. Similar results are seen for other layers, including the decoder layers.
Experiments
We benchmark our proposed architecture on the WMT 2014 English-to-German and English-to-French tasks. The WMT 2014 English-to-German data set contains 4.5M sentence pairs. The English-to-French contains 36M sentence pairs.
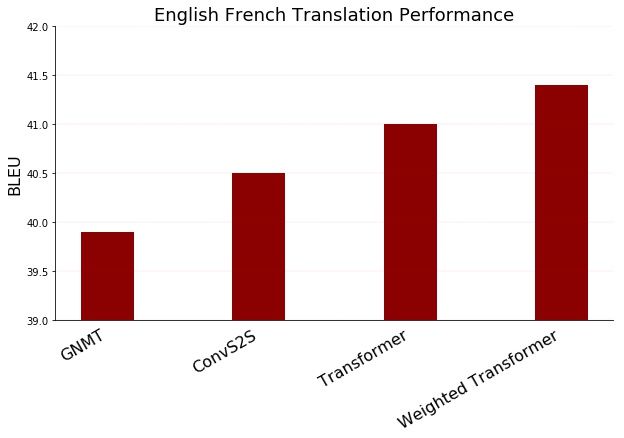
In our paper, we show that the Weighted Transformer outperforms the Transformer network in addition to outperforming both recurrent and convolutional models on academic English to German and English to French translation benchmarks.

Conclusion
We presented the Weighted Transformer for machine translation that trains faster and achieves better performance than the original Transformer network. The proposed architecture replaces the multi-head attention in the Transformer network by a multiple self-attention branches whose contributions are learned as a part of the training process. We report numerical results on the WMT 2014 English-to-German and English-to-French tasks and show that the Weighted Transformer improves the state-of-the-art BLEU scores by 0.5 and 0.4 points respectively.
Citation credit
Karim Ahmed, Nitish Shirish Keskar and Richard Socher. 2017.
Weighted Transformer Network for Machine Translation