 Blog Home
Blog HomeUniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild
UniControl is accepted to NeurIPS’23.
Other authors include Yingbo Zhou, Huan Wang, Juan Carlos Niebles, Caiming Xiong, Silvio Savarese, Stefano Ermon, and Yun Fu.
Is it possible for a single model to master the art of creating images from sketches, maps, diagrams, and more? While diffusion-based text-to-image generators like DALL-E-3 have showcased remarkable results from natural language prompts, achieving precise control over layouts, boundaries, and geometry remains challenging using just text descriptions. Now, researchers have developed UniControl, a unified model capable of handling diverse visual conditions ranging from edges to depth maps within one unified framework.

Background
Text-to-image (T2I) synthesis has exploded in capability recently through advances in deep generative models. Systems like DALL-E 2, Imagen, and Stable Diffusion can now generate highly photorealistic images controllable by natural language prompts. These breakthroughs are powered by diffusion models which have proven extremely effective for text-to-image generation.
However, control using just text prompts is barely precise for spatial, structural and geometric attributes. For example, asking to "add a large purple cube" relies on the model's implicitly learned understanding of 3D geometry. Recent approaches like ControlNet introduced conditioning on additional visual signals like segmentation maps or edge detections. This enables explicit control over image regions, boundaries, object locations, etc.
But each ControlNet model only handles one specific visual condition, like edges or depth maps. Extensive retraining is needed to expand capabilities. Supporting diverse controllable inputs requires developing specialized models for each task. This bloats parameters, limits knowledge sharing, and hinders cross-modality adaptation or out-of-domain generalization.
Motivation
There is a pressing need for unified models that can handle diverse visual conditions for controllable generation. Consolidating capabilities in a single model would greatly improve training and deployment efficiency without needing multiple task-specific models. It also allows exploiting relationships across conditions, like depth and segmentation, to improve generation quality.
For example, depth estimation relies heavily on understanding semantic segmentation and global scene layout. A unified model can better leverage these relationships compared to isolated task models. Furthermore, adding new modalities to individual models incurs massive retraining, while a consolidated approach could generalize more seamlessly.
The core challenge is to overcome the misalignment between diverse conditions like edges, poses, maps, etc. Each requires operations specialized to its characteristics. Trivially mixing diverse inputs in one model fails due to this feature mismatch. The goal is to develop a unified architecture that generalizes across tasks while adapting their conditioning components appropriately. Crucially, this needs to be achieved without requiring extensive retraining whenever expanding to new capabilities.
Methods
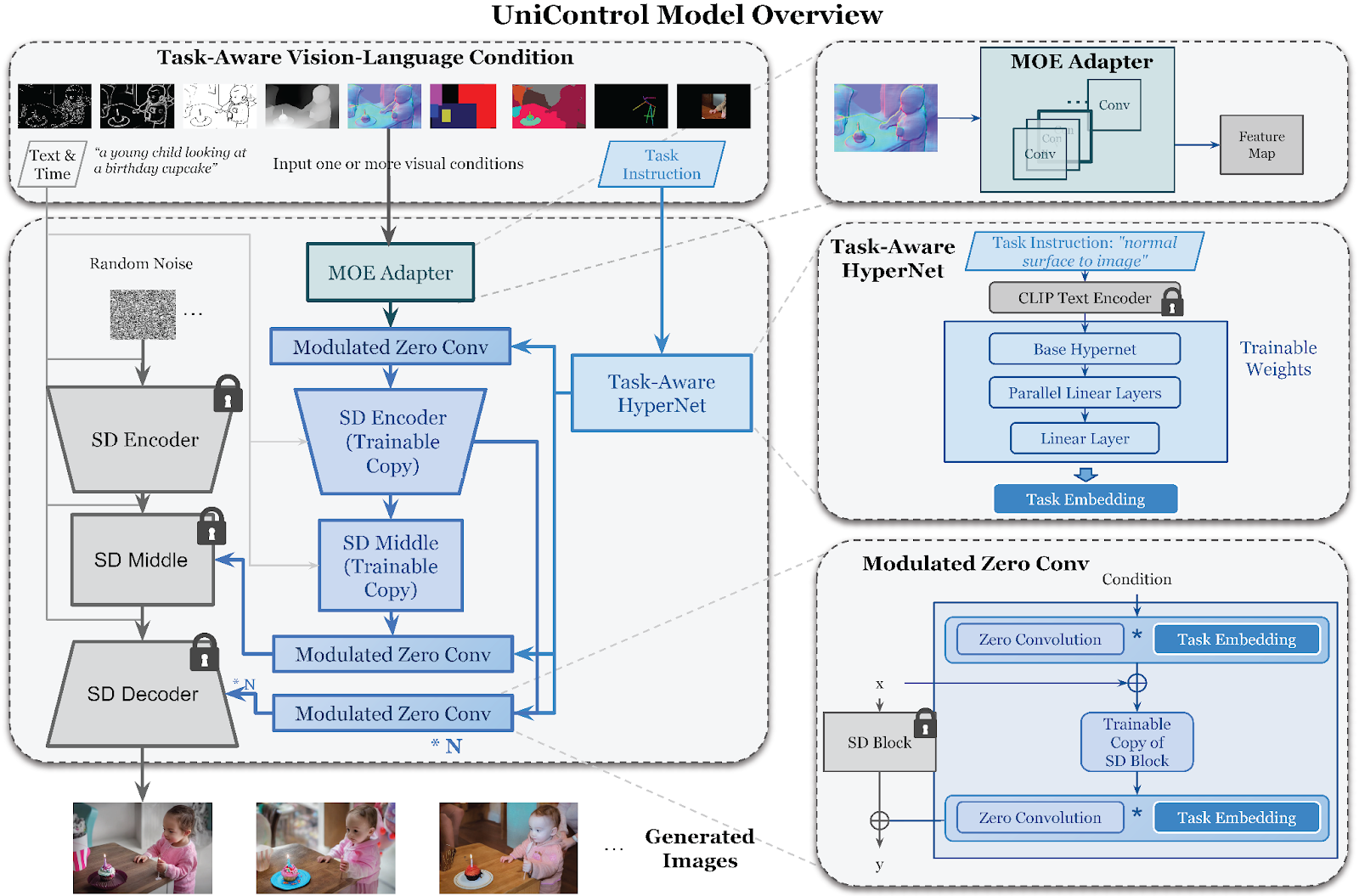
The proposed UniControl introduces two new components to enable unified multi-task controllable generation:
1. Mixture-of-Experts Adapters: Parallel convolutional modules, one per task, that adapt to each condition's visual features.
2. Task-Aware HyperNetwork: Dynamically modulates the convolution kernels of a base model given embeddings of task instructions.
UniControl is trained on twelve distinct tasks spanning edges, regions, maps, and more. The overall model architecture remains consistent across tasks, while the conditioning components specialize.
Mixture-of-Experts Adapters
The adapters provide dedicated pathways for each task to process its visual features appropriately. This overcomes the misalignment between diverse conditions needing specialized handling.
For example, a segmentation map pathway focuses more on spatial semantic relations than 3D geometry. In contrast, a depth adapter will emphasize global layout and surface orientations. With separate adapters per task, UniControl can extract nuanced representations tailored to each input type.
This modularization mimics a mixture-of-experts. Each adapter acts as a specialized "expert" for its task. Parallel pathways avoid conflicting objectives that would arise from entangled handling of all conditions. The model dynamically composites outputs from relevant adapters according to the input task.
Task-Aware HyperNetwork
The HyperNetwork enables dynamic modulation of UniControl based on the specified task. It inputs instructions like "depth map to image" and outputs embedding vectors. These embeddings can specialize the model by modulating its convolution kernels based on the task.
For example, depth conditioning may modulate early layers to focus more on global layout and geometry. In the meanwhile, edge adaptation may emphasize higher-frequency details at later stages. The HyperNetwork allows UniControl to learn specialized understanding and processing of each task.
By conditioning on instructions, it also enables generalization to novel tasks at test time. The relationships learned during multi-task training allow sensible modulation even for unseen tasks. Composing embeddings from related known tasks facilitates zero-shot transfer.
Experiments
UniControl was trained on a diverse MultiGen-20M dataset with over 20 million image-text-condition triplets. Key results demonstrated:
- It outperforms single-task ControlNets on most tasks, benefitting from joint training. The unified design improves efficiency.
- It generalizes to unseen hybrid tasks like depth+pose without retraining by composing adapters.
- UniControl maintains 1.4B parameters while a set of single-task models (i.e., Multi-ControlNet) would require over 4B parameters.
- Zero-shot transfer to new tasks like colorization and inpainting succeeds by blending adapters from related tasks.


Video Demo
Explore More
arXiv: https://arxiv.org/abs/2305.11147
Code: https://github.com/salesforce/UniControl
Web: https://canqin001.github.io/UniControl-Page/
HF Space: https://huggingface.co/spaces/Robert001/UniControl-Demo
Contact: cqin@salesforce.com