 Blog Home
Blog HomeA Leap Forward in 3D Understanding: The ULIP and ULIP-2
TL;DR:
Imagine a world where machines comprehend 3D objects just as humans do. The ULIP (CVPR2023) and ULIP-2 projects, backed by Salesforce AI, are making this a reality by revolutionizing 3D understanding. ULIP uniquely pre-trains models with 3D point clouds, images, and texts, aligning them into a unified representation space. This approach enables state-of-the-art results in 3D classification tasks and opens up possibilities for cross-domain tasks like image-to-3D retrieval. Building on ULIP's success, ULIP-2 harnesses large multimodal models to generate holistic language counterparts for 3D objects, enabling scalable multimodal pre-training without the need for manual annotations. These groundbreaking projects are bridging the gap between the digital and physical worlds, propelling us one step closer to a future where AI can truly understand our world.
Background
The field of 3D understanding is a crucial aspect of artificial intelligence that focuses on enabling machines to perceive and interact with the world in three dimensions, much like humans do. This capability is vital for numerous applications, ranging from autonomous vehicles and robotics to virtual and augmented reality.
Historically, 3D understanding has posed significant challenges due to the complexity involved in processing and interpreting 3D data. The cost of collecting and annotating 3D data further compounds these challenges. Moreover, real-world 3D data often comes with its own set of complexities, including noise and incompleteness.
In recent years, advancements in AI and machine learning have opened up new possibilities in 3D understanding. One of the most promising developments is the use of multimodal learning, which involves training models on data from multiple modalities. This approach can help models capture a richer understanding of 3D objects by considering not just their shape, but also their appearance in images and their descriptions in text.
The ULIP and ULIP-2 projects, backed by Salesforce AI, are at the cutting edge of these advancements. These projects are pushing the potential in 3D understanding, setting new benchmarks for what's achievable in this exciting field.
Methods
The ULIP and ULIP-2 employ innovative and effective methods, harnessing the power of multimodal learning to enhance 3D understanding in a scalable way.
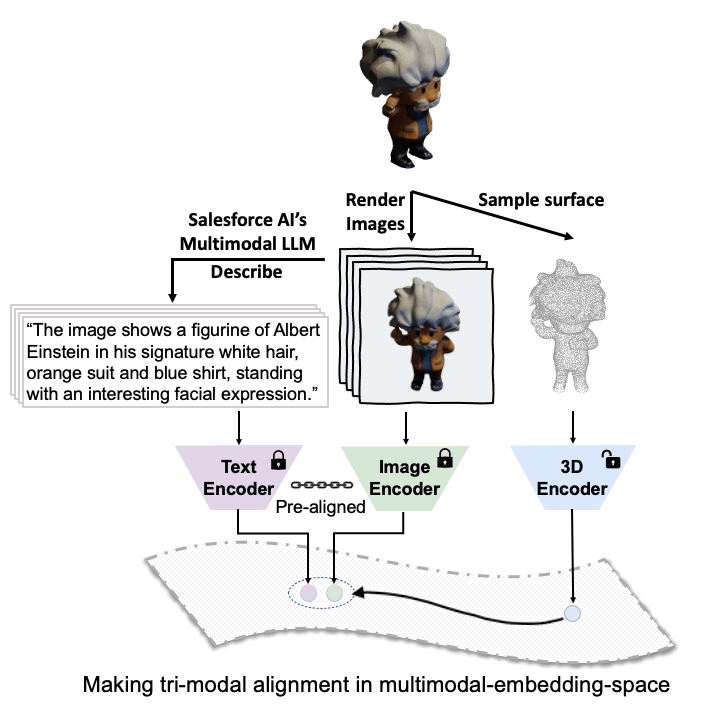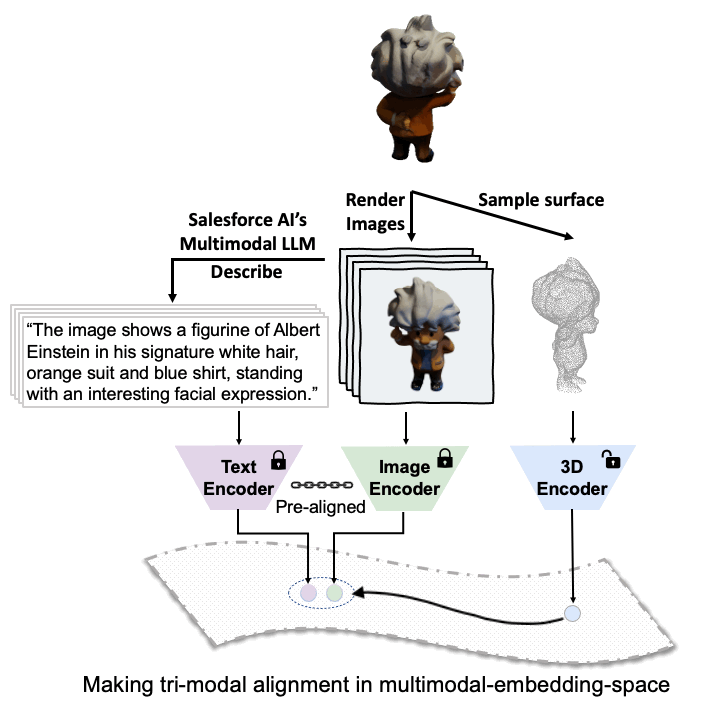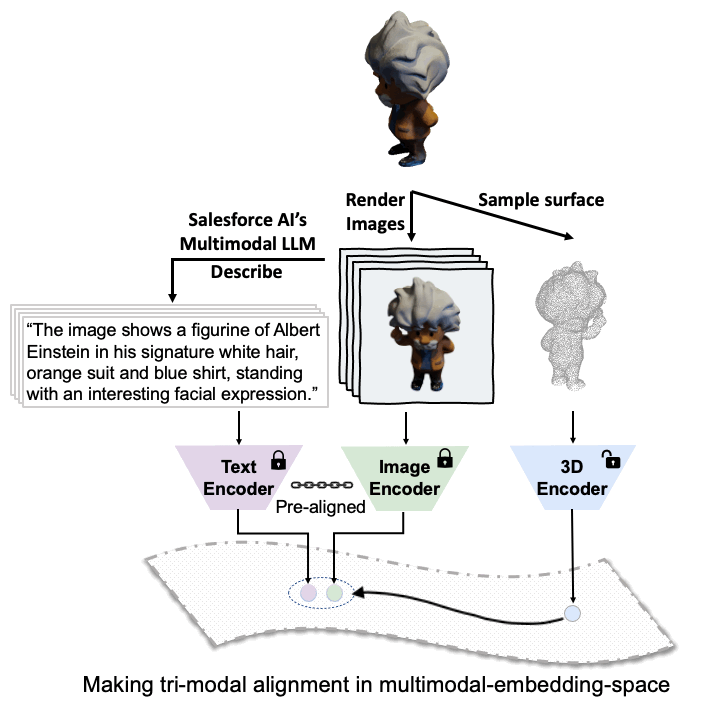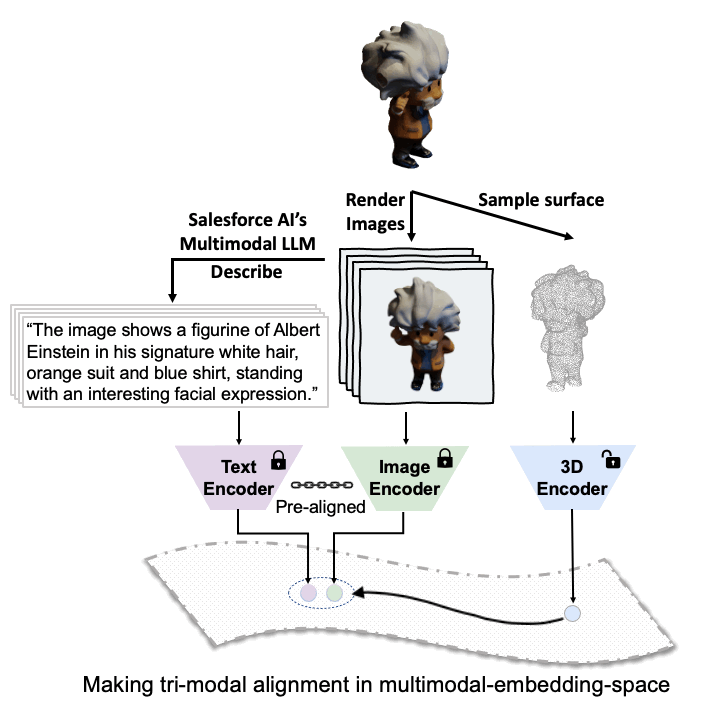
ULIP
The ULIP project (accepted by CVPR2023) uses a unique approach of pre-training models with triplets of images, text descriptions, and 3D point clouds. This method is akin to teaching a machine to understand a 3D object from different perspectives - how it looks (image), what it is (text description), and its physical structure (3D point cloud).
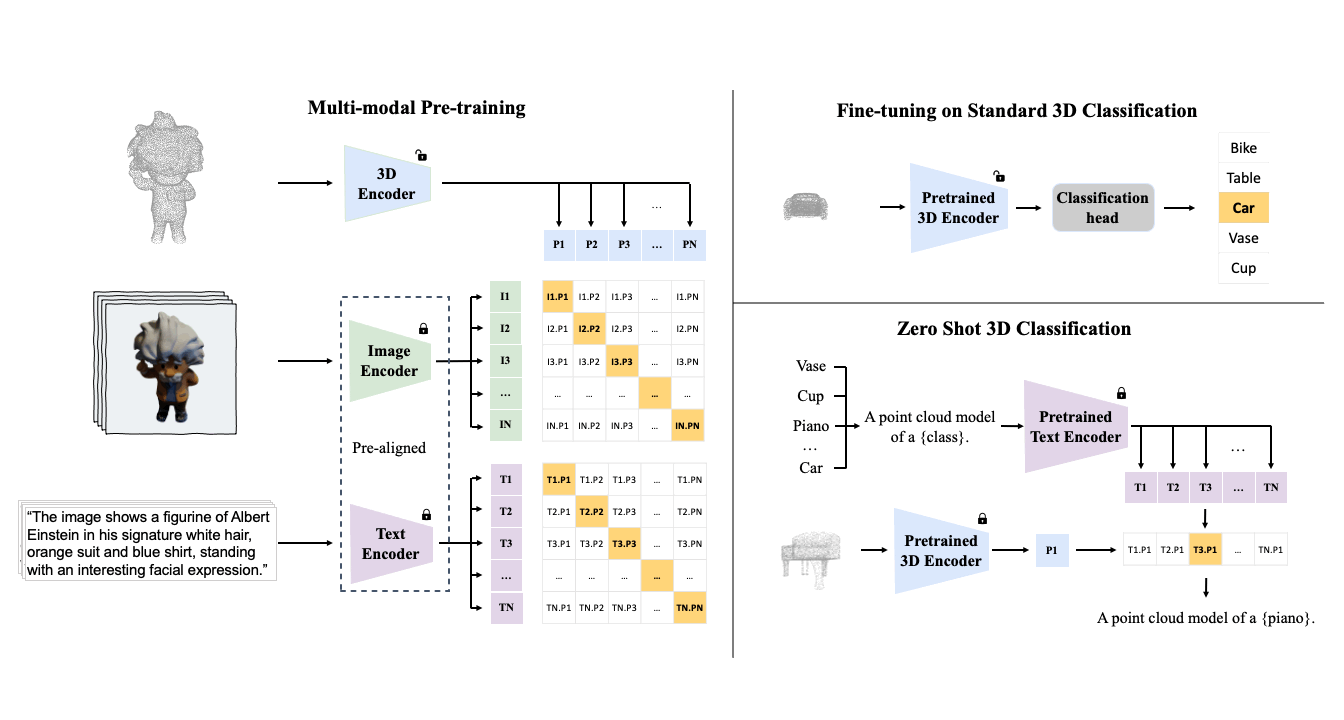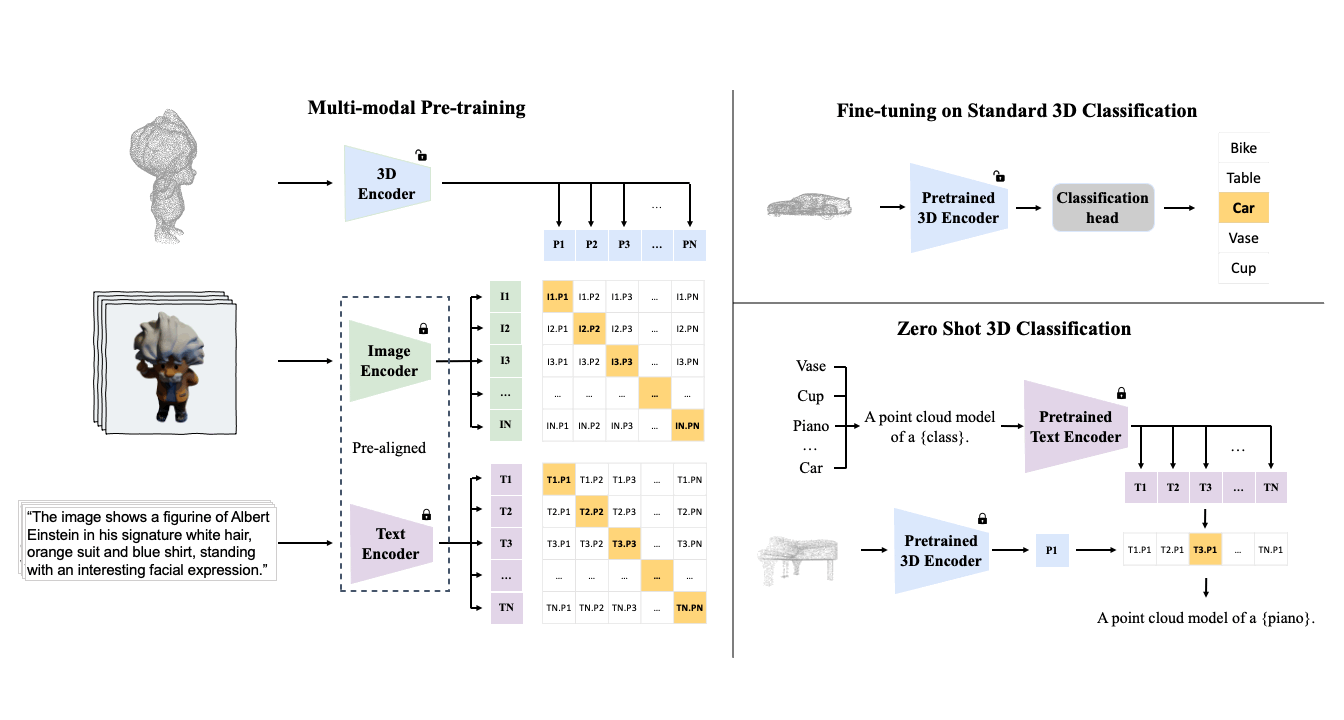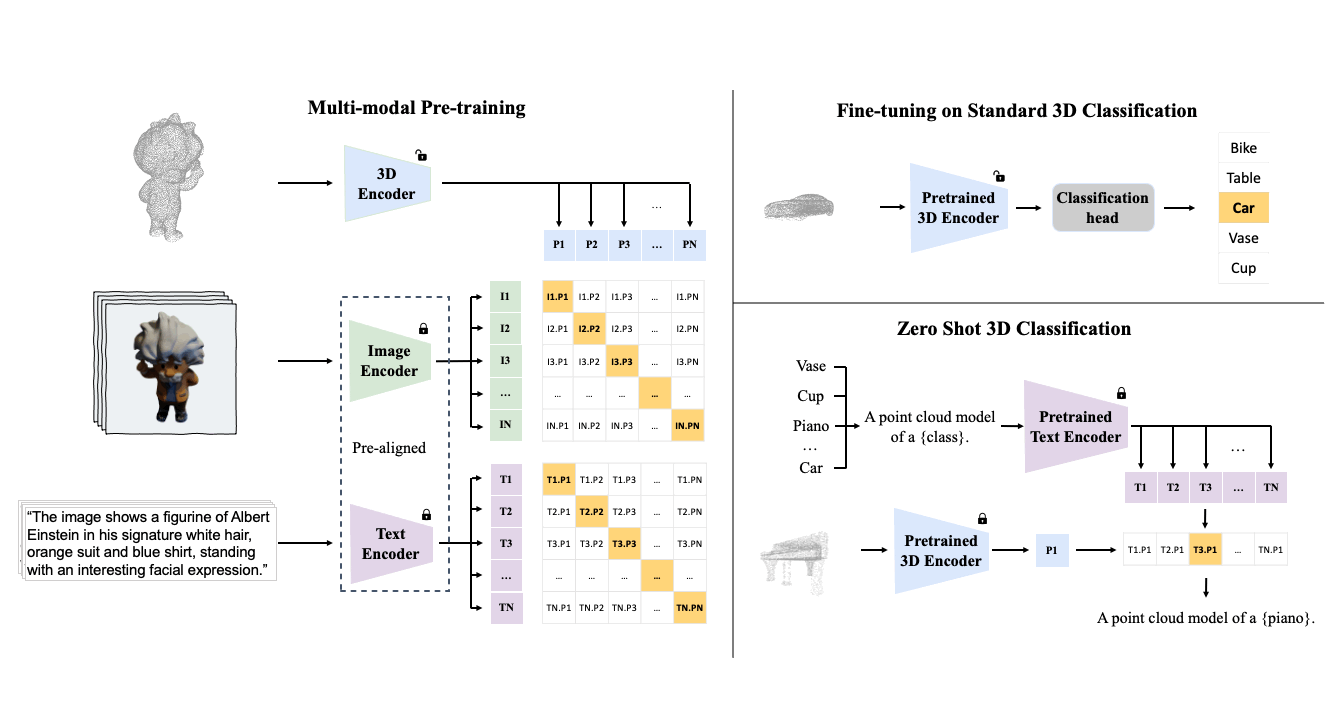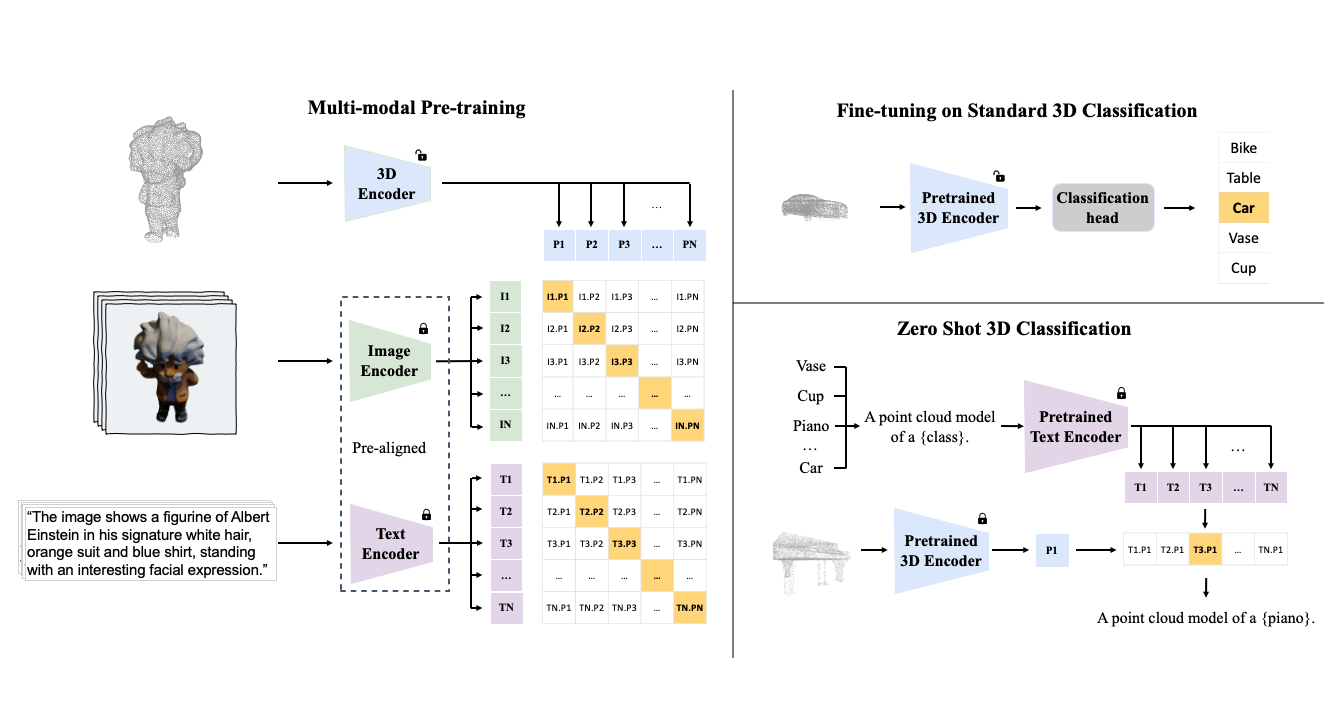
The key to ULIP's success is the use of pre-aligned image and text encoders such as CLIP, which is pre-trained on massive image-text pairs. These encoders align the features of the three modalities into a unified representation space, enabling the model to understand and classify 3D objects more effectively. This improved 3D representation learning not only enhances the model's understanding of 3D data but also enables cross-modal applications like zero-shot classification and image to 3D retrieval, as the 3D encoder gains multimodal context.
ULIP-2
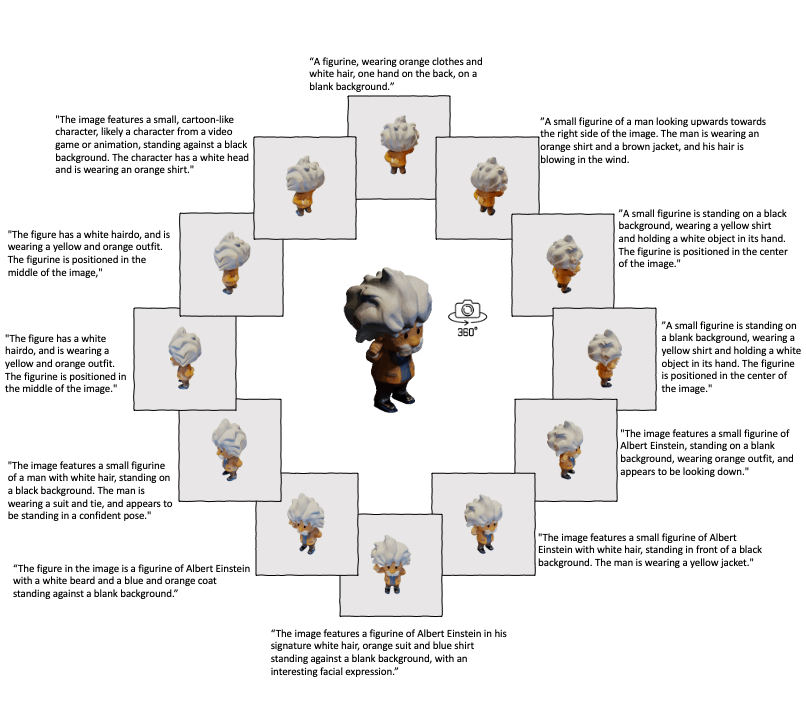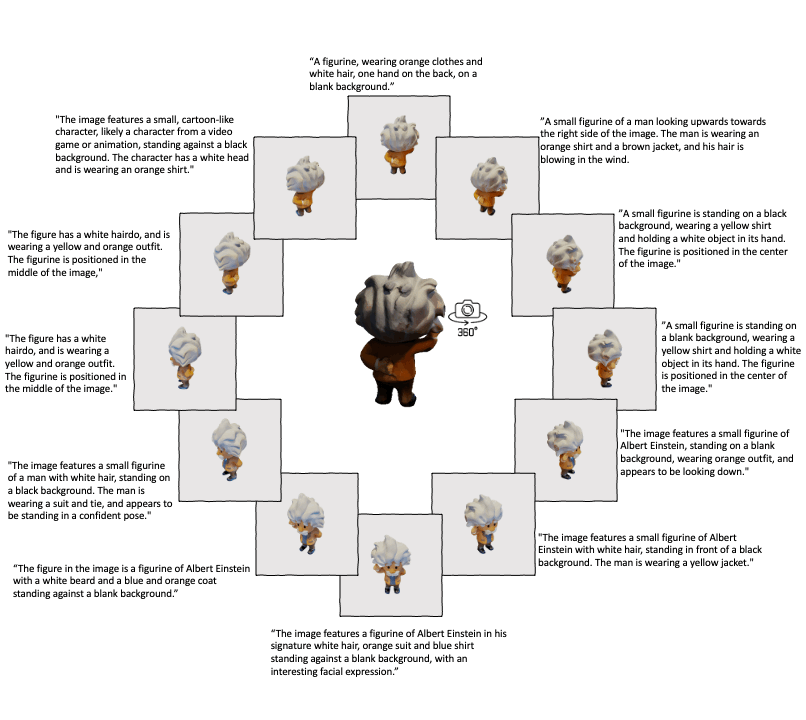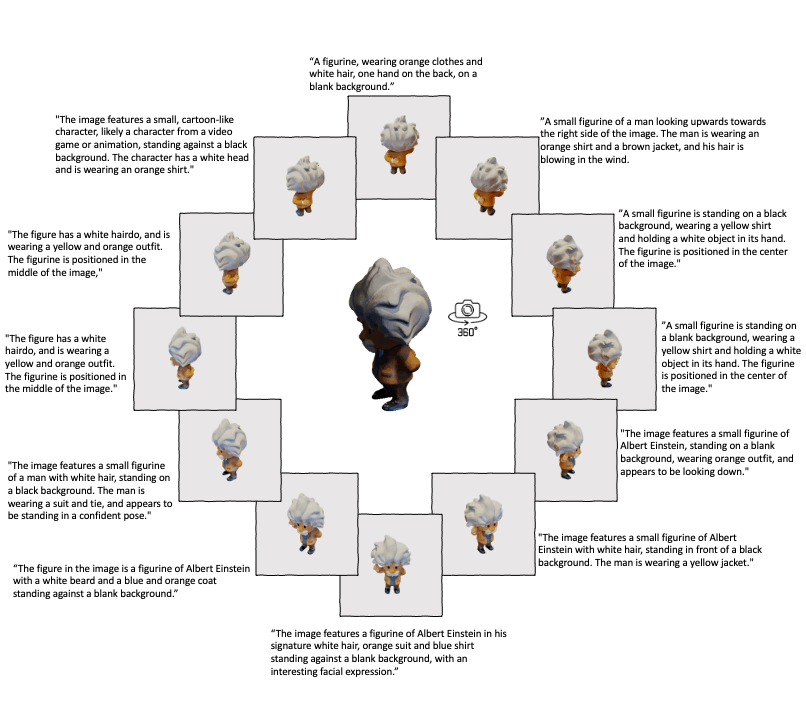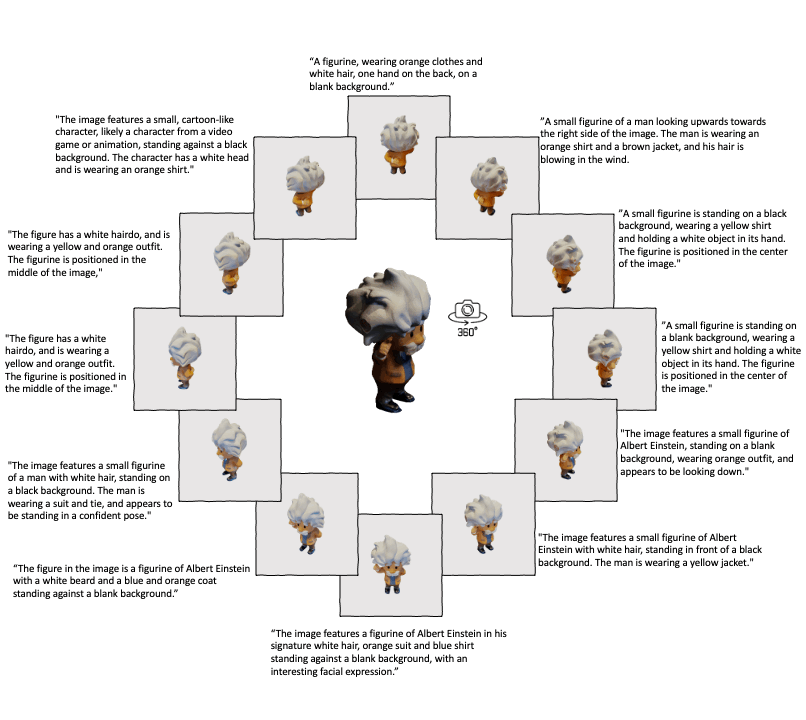
Building on the success of ULIP, ULIP-2 takes a step further by harnessing the power of modern large multimodal models. This method is scalable and does not require any manual annotations, making it more efficient and adaptable.
ULIP-2's approach involves generating holistic language descriptions for each 3D object, which are then used to train the model. This framework enables the creation of massive tri-modal datasets without the need for manual annotations, thereby unleashing the full potential of multimodal pre-training. We also release the generated tri-modal datasets: "ULIP-Objaverse Triplets" and "ULIP-ShapeNet Triplets".

The Bottom Line
The ULIP project and ULIP-2, backed by Salesforce AI, are transforming the field of 3D understanding. ULIP aligns different modalities into a unified space, enhancing 3D classification and enabling cross-modal applications. ULIP-2 takes it a step further, generating holistic language descriptions for 3D objects and creating massive tri-modal datasets without manual annotations. These projects are setting new benchmarks in 3D understanding, paving the way for a future where machines can truly understand our world in three dimensions.
Explore More
Arxiv pdf:
ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding
ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
Code and released tri-modal datasets:
https://github.com/salesforce/ULIP
Website:
https://tycho-xue.github.io/ULIP/
Follow us on Twitter: @SFResearch @Salesforce
Contact: Le Xue at lxue@salesforce.com