 Blog Home
Blog HomeThe Natural Language Decathlon

Introduction
Deep learning has significantly improved state-of-the-art performance for natural language processing tasks like machine translation, summarization, question answering, and text classification. Each of these tasks is typically studied with a specific metric, and performance is often measured on a set of standard benchmark datasets. This has led to the development of architectures designed specifically for those tasks and metrics, but it does not necessarily promote the emergence of general NLP models, those which can perform well across a wide variety of NLP tasks. In order to explore the possibility of such models as well as the tradeoffs that arise in optimizing for them, we introduce the Natural Language Decathlon (decaNLP). This challenge spans ten tasks: question answering, machine translation, summarization, natural language inference, sentiment analysis, semantic role labeling, relation extraction, goal-oriented dialogue, database query generation, and pronoun resolution. The goal of the Decathlon is to explore models that generalize to all ten tasks and investigate how such models differ from those trained for single tasks. For this reason, performance on the Decathlon is measured by an aggregate decaScore, which combines the standard metrics for each of the ten tasks.
We cast all ten tasks as question answering and present a new multitask question answering network (MQAN) that jointly learns them without any task-specific modules or parameters. MQAN shows improvements in transfer learning for machine translation and named entity recognition, domain adaptation for sentiment analysis and natural language inference, and zero-shot capabilities for text classification. In comparisons to baselines, we demonstrate that the MQAN’s multi-pointer-generator decoder is key to this success and performance further improves with an anti-curriculum training strategy. Though designed for decaNLP and general question answering, MQAN happens to perform well in the single-task setting regardless: it achieves state-of-the-art results on the WikiSQL semantic parsing task, second to state-of-the-art in goal oriented dialogue, the highest scores on SQuAD for a model that does not directly use span supervision, and performs well across all other tasks. All code for procuring and processing data, training and evaluating models, and reproducing experiments for decaNLP have been made publicly available.
Tasks
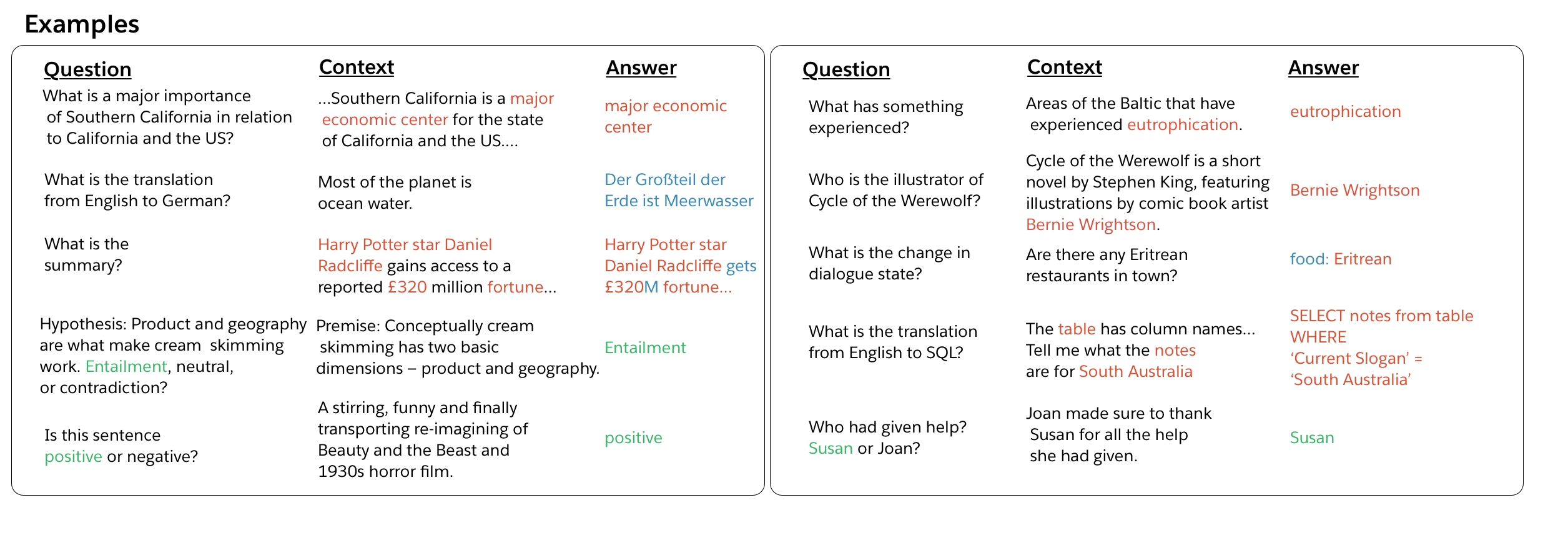
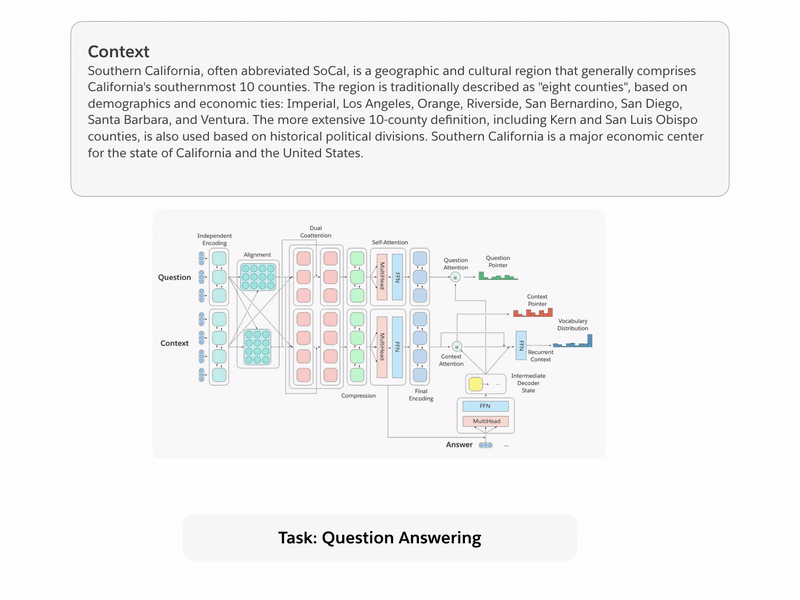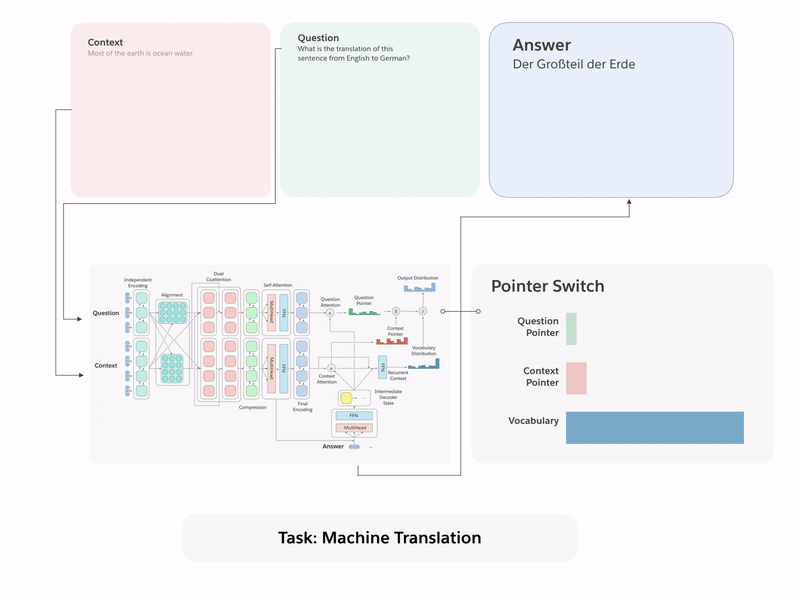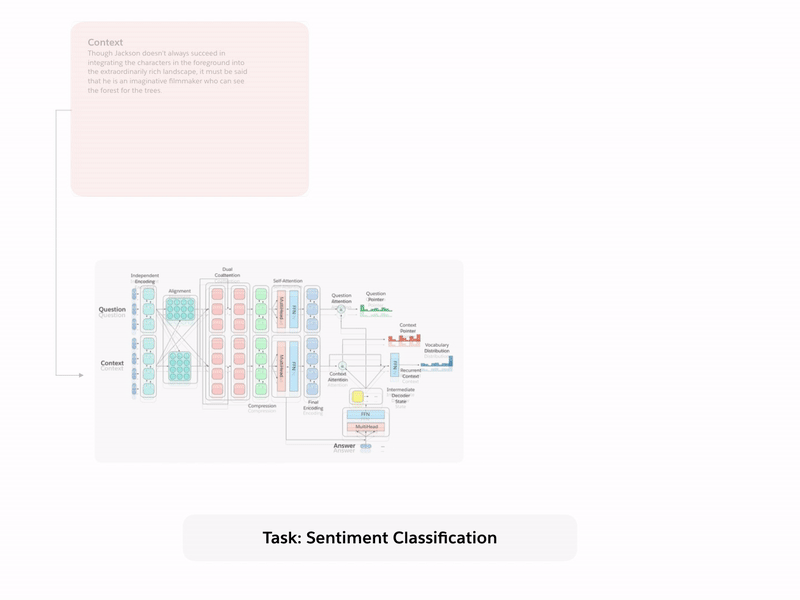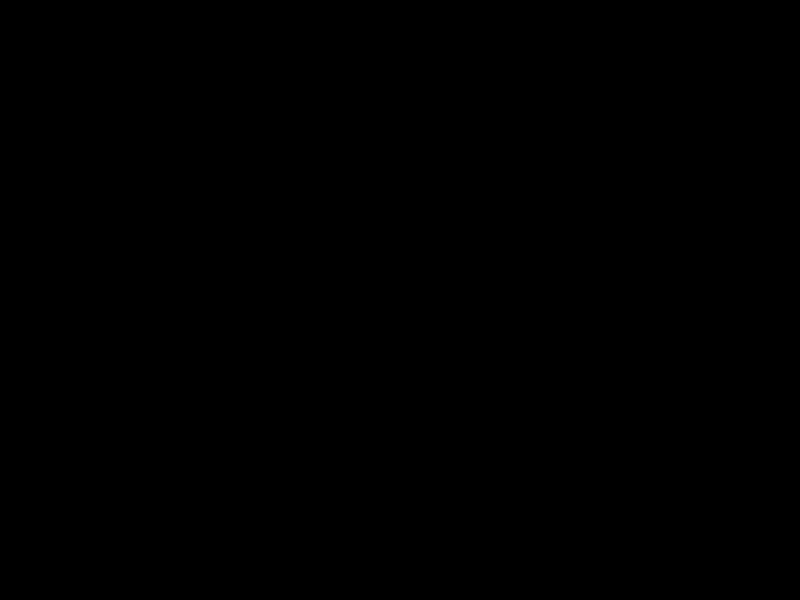
Let us begin by first discussing the tasks and their associated datasets. Our paper contains additional details that include a more thorough discussion of the historical background and recent work for each task. Sample input-output pairs for each of the tasks is presented in Figure 1.
Question Answering. Question answering (QA) models receive a question and a context that contains information necessary to output the desired answer. We use the original version of the Stanford Question Answering Dataset (SQuAD) for this task. Contexts are paragraphs taken from the English Wikipedia, and answers are sequences of words copied from the context.
Machine Translation. Machine translation models receive an input document in a source language that must be translated into a target language. We use the 2016 English to German training data prepared for the International Workshop on Spoken Language Translation (IWSLT), and we use the 2013 and 2014 test sets for our own validation and test sets, respectively. Examples are from transcribed TED presentations that cover a wide variety of topics with conversational language. This is a relatively small dataset for machine translation, but it is roughly the same scale as the datasets for other tasks. Nothing precludes the use of additional training resources, like machine translation data from the Workshop on Machine Translation (WMT) for decaNLP.
Summarization. Summarization models take in a document and output a summary of that document. Most important to recent progress in summarization was the transformation of the CNN/DailyMail (CNN/DM) corpus into a summarization dataset. We include the non-anonymized version of this dataset in decaNLP. On average, these examples contain the longest documents in decaNLP, and the force models to balance extracting directly from the context with generating answers from outside the context.
Natural Language Inference. Natural Language Inference (NLI) models receive two input sentences: a premise and a hypothesis. Models must then classify the inference relationship between the premise and hypothesis as one of entailment, neutrality, or contradiction. We use the Multi-Genre Natural Language Inference Corpus (MNLI), which provides training examples from multiple domains (transcribed speech, popular fiction, government reports) and test pairs from seen and unseen domains.
Sentiment Analysis. Sentiment analysis models are trained to classify the sentiment expressed by input text. The Stanford Sentiment Treebank (SST) consists of movie reviews with the corresponding sentiment (positive, neutral, negative). We use the unparsed, binary version so that dependencies on parsing must be made explicit for decaNLP models.
Semantic Role Labeling. Semantic role labeling (SRL) models are given a sentence and predicate (typically a verb) and must determine ‘who did what to whom,’ ‘when,’ and ‘where’. We use an SRL dataset that treats the task as question answering: QA-SRL. This datasets covers both news and Wikipedia domains, but we only use the latter in order to ensure that all data for decaNLP can be freely downloaded.
Relation Extraction. Relation extraction systems take in a text document and the kind of relation that is to be extracted from that text. In this setting, it is important that models can report that the relation is not present and cannot be extracted. As with SRL, we use a dataset that maps relations to a set of questions so that relation extraction can be treated as question answering: QA-ZRE. Evaluation of the dataset is designed to measure zero shot performance on new kinds of relations -- the dataset is split so that relations seen at test time are unseen at train time. This kind of zero-shot relation extraction, framed as question answering, makes it possible to generalize to new relations.
Goal-Oriented Dialogue. Dialogue state tracking is a key component of goal-oriented dialogue systems. Based on user utterances and system actions, dialogue state trackers keep track of which predefined goals the user has for the dialogue system and which kinds of requests the user makes as the system and user interact turn-by-turn. We use the English Wizard of Oz (WOZ) restaurant reservation task, which comes with a predefined ontology of foods, dates, times, addresses, and other information that would help an agent make a reservation for a customer.
Semantic Parsing. SQL query generation is related to semantic parsing. Models based on the WikiSQL dataset translate natural language questions into structured SQL queries so that users can interact with a database in natural language.
Pronoun Resolution. Our final task is based on Winograd schemas, which require pronoun resolution: "Joan made sure to thank Susan for the help she had [given/received]. Who had [given/received] help? Susan or Joan?". We started with examples taken from the Winograd Schema Challenge and modified them (resulting in the Modified Winograd Schema Challenge, MWSC) to ensure that answers were a single word from the context and scores are neither inflated nor deflated by oddities in phrasing or inconsistencies between context, question, and answer.
The Decathlon Score (decaScore)
Models competing on decaNLP are evaluated using an additive combination of task-specific metrics. All metrics fall between 0 and 100, so that the decaScore naturally falls between 0 and 1000 for ten tasks. Using an additive combination avoids the arbitrariness that might arise from our own bias in weighing different metrics. All metrics are case insensitive. We use normalized F1 (nF1) for QA, NLI, sentiment analysis, SRL and MWSC; an average of ROUGE-1, ROUGE-2 and ROUGE-L for summarization; corpus-level BLEU scores for machine translation; an average of a joint goal tracking exact match score and a turn based request exact match score for goal-oriented dialogue; a logical-form exact match score for semantic parsing on WikiSQL; and a corpus-level F1 for relation extraction with QA-ZRE.
In lieu of splitting the standard validation data, we have opted to require decaNLP models to submit to the original SQuAD platform for testing. Similarly, the MNLI test set is not public, and decaNLP models must evaluate test performance for MNLI through a Kaggle system.
Multitask Question Answering Network (MQAN)
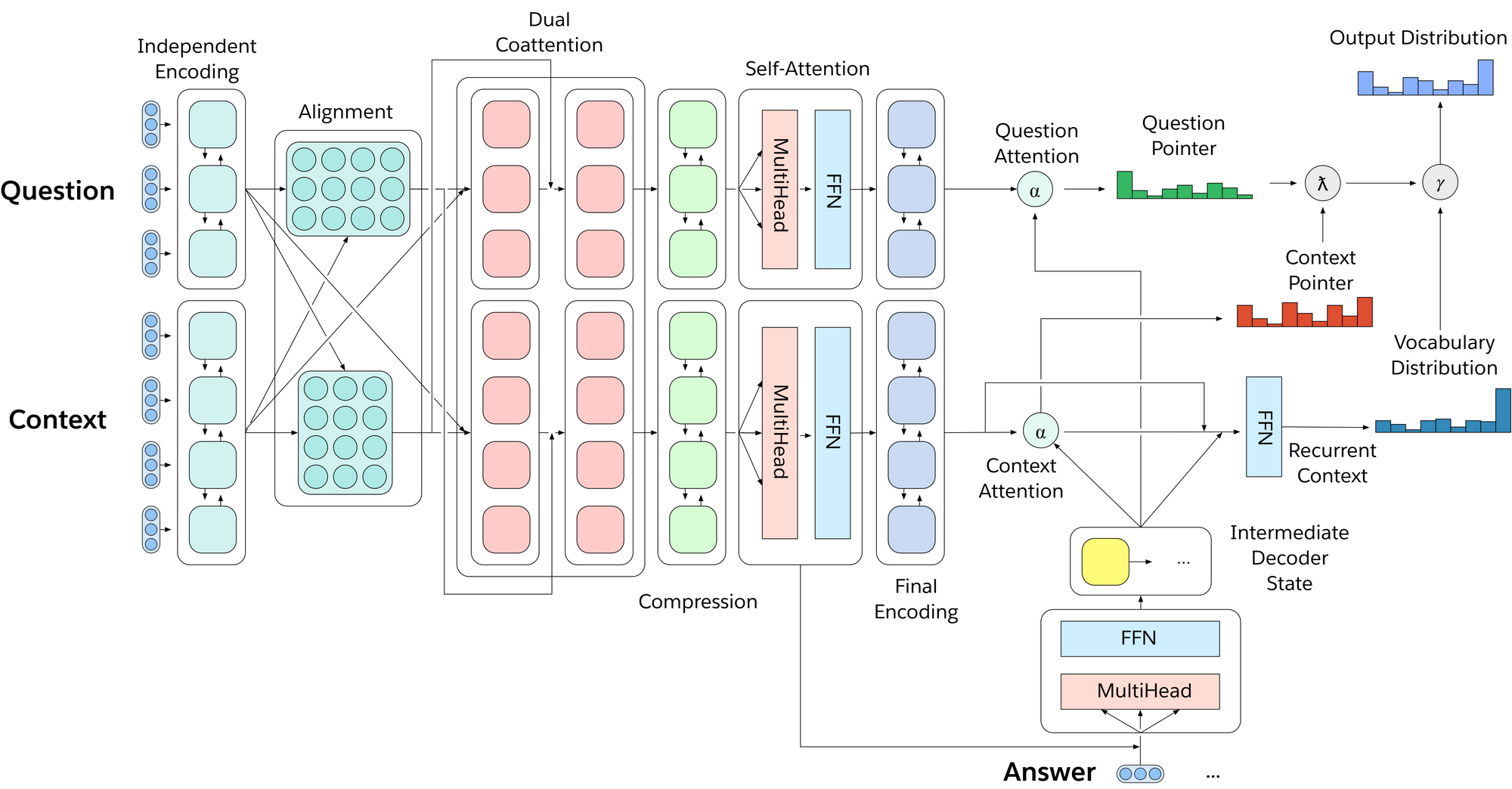
To effectively multitask across all of decaNLP, we introduce MQAN, a multitask question answering network, that contains no task-specific adaptations, parameters, or modules. Succinctly, MQAN takes in a question and context document, encodes both with a BiLSTM, uses dual coattention to condition representations for both sequences on the other, compresses all of this information with another two BiLSTMs to make higher layers more computationally feasible, applies self-attention to collect long-distance dependencies, and then uses a final two BiLSTMs to get final representations of the question and context. The multi-pointer-generator decoder uses attention over the question, context, and previously output tokens to decide whether to copy from the question, copy from the context, or generate from a limited vocabulary. Additional details regarding our model can be found in Section 3 of our paper.
Baselines and Results
In addition to MQAN, we experimented with several baseline approaches and computed their decaScores. The first baseline, S2S, is a sequence-to-sequence network with attention and pointer-generator . Our second baseline, S2S w/SAtt, is an S2S network with self-attention (Transformer) layers added between BiLSTM layers on the encoder side and between LSTM layers on the decoder side. Our third baseline, +CAtt, splits the context and question into two sequences and adds an additional coattention layers to the encoder side. MQAN is a +CAtt model with an additional question pointer, and so it is referred to as +QPtr in our baseline/ablation studies. For each of these models, we present two kinds of experiments. In the first, we report single-task performance of the model for all ten tasks. In the second, we present multitasking performance where the model is trained jointly across all tasks.
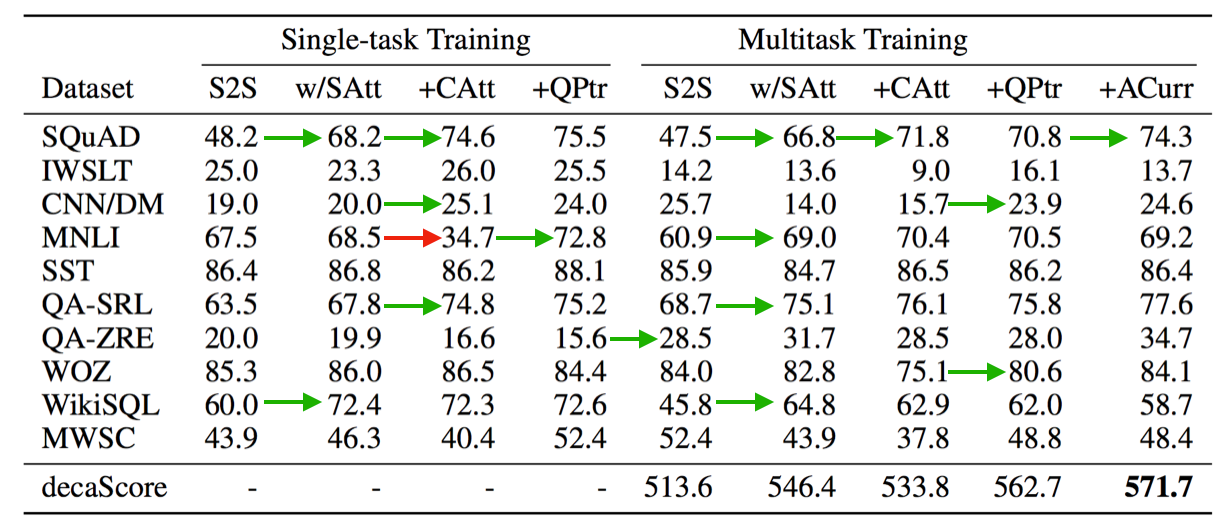
Comparing the results of these experiments highlights tradeoffs between multitasking and single-tasking as well as between the sequence-to-sequence and question answering approach to general NLP. Moving from an S2S to an S2S w/ SAtt provides the model with additional layers of attention for mixing the context and question in the single sequence input. This dramatically improves performance on SQuAD and WikiSQL while also boosting performance on QA-SRL. This alone is enough to achieve a new state-of-the-art performance for WikISQL. This also suggests that explicitly separating context and question might allow the model to build richer representations of both if it no longer has to implicitly learn how to separate their representations.
The next baseline uses the context and question as separate input sequences, and is equivalent to augmenting the S2S model with a coattention mechanism (+CAtt) that builds representations of both sequences separately. Performance on SQuAD and QA-SRL increases by more than 5 nF1 each. Unfortunately, this separation fails to improve other tasks, and it significantly hurts performance on MNLI and MWSC. For these two tasks, answers can be copied directly from the question rather than the context as in most of the other tasks. Because both S2S baselines had the question concatenated to the context, the pointer-generator mechanism was able to copy directly from the question. When the context and question were separated into two different inputs, the model lost this ability.
In order to remedy this, we add a question pointer (+QPtr) to the previous baseline, which gives the MQAN. This boosts performance on both MNLI and MWSC to much higher scores than even the S2S baselines achieved. It also improved performance on SQuAD, IWSLT, and CNN/DM. This model achieves a new state-of-the-art result on WikiSQL, is the second highest performing model for the goal-oriented dialogue datasets, and is the highest performing model on the SQuAD dataset that does not explicitly model the problem as span extraction, i.e. does use direct span supervision, which we see as a limitation for general purpose question answering.
In the multitask setting, we see similar results, but we also notice several additional striking features. QA-ZRE, zero-shot relation extraction, performance increases 11 points over the highest single-task models, which supports the hypothesis that multitask learning can lead to better generalization even in zero-shot cases. Performance on tasks that require heavy use of the generator portion of the pointer-generator decoder of S2S baselines drops by more than 50 percent until the question pointer is again added to the model. We hypothesize that this is particularly important in the multitask setting for two reasons. First, the question pointer makes use of a coattended question in addition to a coattended context. This separation allows crucial information about the question to flow directly into the decoder instead of through the coattended context. Second, with more direct access to the question, the model is able to more effectively decide when generating output tokens is more appropriate than copying.
Using an anti-curriculum training strategy that initially trains only for question answering, performance increases even further for decaNLP.
Zero-Shot and Transfer Learning Capabilities
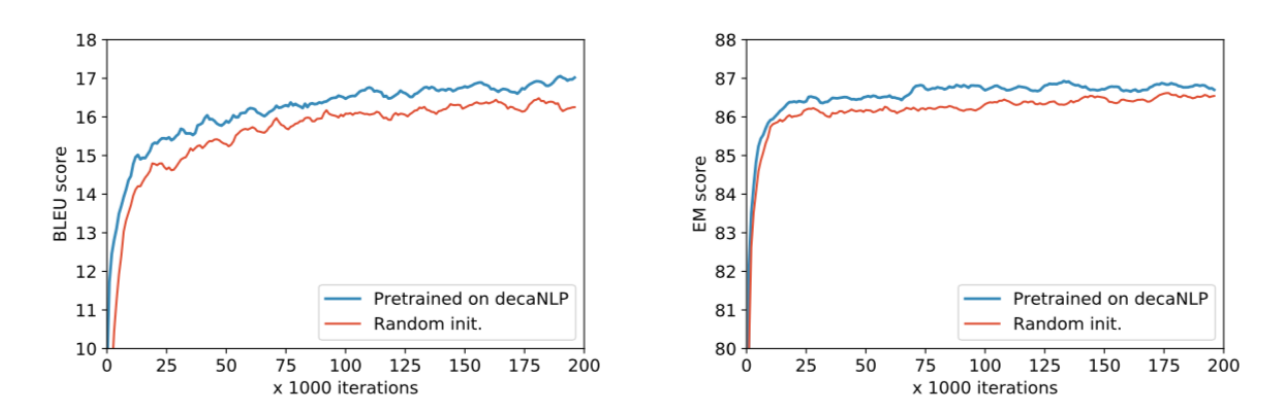
Given that our model is trained on rich and diverse data, it builds powerful intermediate representations that enable transfer learning. Relative to a randomly initialized model, our model pretrained on decaNLP enabled faster convergence and improved scores on several new tasks. We present two such tasks, named entity recognition and English-to-Czech translation in the figure above.
Our model also possesses zero-shotting capabilities for domain adaptation. Trained on decaNLP, our model adapted to the SNLI dataset to an exact match score of 62% without ever having seen training data. Because decaNLP contains SST, it can also perform well on other binary sentiment classification tasks. On Amazon and Yelp reviews, MQAN pretrained on decaNLP achieves exact match scores of 82.1% and 80.8%, respectively. Additionally, rephrasing questions by replacing the tokens for the training labels positive/negative with happy/angry or supportive/unsupportive at inference time, leads to only small degradation in performance because the model primarily relies on the question pointer for SST. This suggests these multitask models are more robust to slight variations in questions and tasks and can generalize to new and unseen classes.
Additional Details and Citation
For the sake of brevity, we direct an interested reader to our paper and its appendices for additional details regarding the tasks and their history, the model, training strategies, curriculum learning heuristics, analysis of the model activations, and related work. The paper, and its citation, are:
Bryan McCann, Nitish Shirish Keskar, Caiming Xiong and Richard Socher.
Download PDF