 Blog Home
Blog HomeState of the art Deep Learning Model for Question Answering
We introduce the Dynamic Coattention Network, a state of the art neural network designed to automatically answer questions about documents. Instead of producing a single, static representation of the document without context, our system is able to interpret the document differently depending on the question. That is, given the same document, the system constructs a different understanding depending on the question (e.g. which team represented the NFC in Superbowl 50, who scored the touchdown in the fourth quarter). Based on this conditional interpretation, our system iteratively hypothesizes multiple answers, allowing it to adjust initially misguided predictions. The Dynamic Coattention Network achieves a test F1 score, a measure of similarity between the predicted answer and the human annotated answer, of 80.4% on the Stanford Question Answering Dataset, and significantly outperforms other systems developed by the Allen Institute for Artificial Intelligence, Microsoft Research Asia, Google, and IBM. Details about the Dynamic Coattention Network can be found in our paper. The leaderboard for the Stanford Question Answering Task can be found here.
Open-domain question answering
Question answering remains one of the most difficult challenges we face in Natural Language Processing. The idea of creating an agent capable of open-domain question answering - answering arbitrary questions with respect to arbitrary documents - has long captured our imagination. An agent that responds in natural language rather than by lists of query results (as in search) takes on almost anthropomorphic qualities, and spurs the imagination to think about the future of artificial intelligence.
The path to open-domain question answering has been long and challenging. One crucial problem that has dogged researchers on this path has been the lack of large-scale datasets. Traditional question answering datasets, such as MCTest, have been high in quality. However, the cost of annotating such datasets with human experts have been prohibitively expensive, thus keeping them small. Recently, researchers have devised techniques to create arbitrarily large cloze-form question answering datasets. These cloze-form datasets, such as the CNN/DailyMail corpus are created by replacing an entity with a placeholder, thereby creating a problem similar to fill-in-the-blank. Namely, the task is to infer the missing entity by choosing amongst all the entities that appear in the document. The cloze-form question answering task is not as natural as open-domain question answering, but the ease with which cloze-form datasets can be created has led to dramatic progress in the development of expressive models such as deep neural networks for question answering.
A cloze-form question answering example:
In 2004, ___ received national attention during his campaign to represent Illinois in the United States Senate with his victory in the March Democratic Party primary, his keynote address at the Democratic National Convention in July, and his election to the Senate in November. He began his presidential campaign in 2007 and, after a close primary campaign against Hillary Clinton in 2008, he won sufficient delegates in the Democratic Party primaries to receive the presidential nomination. He then defeated Republican nominee John McCain in the general election, and was inaugurated as president on January 20, 2009. Nine months after his inauguration, Obama was controversially named the 2009 Nobel Peace Prize laureate.
Just this year, the Stanford Natural Language Processing Group has released yet another large-scale question answering dataset, SQuAD. However, unlike the existing cloze-form datasets, the answers to questions are spans within the document. This dataset is not only large enough to allow the development of expressive models, but natural in its task formulation. The SQuAD dataset is comprised of articles from English Wikepedia and annotated solely by workers on Amazon Mechanical Turk.
A SQuAD like question answering example:
In 2004, Obama received national attention during his campaign to represent Illinois in the United States Senate with his victory in the March Democratic Party primary, his keynote address at the Democratic National Convention in July, and his election to the Senate in November. He began his presidential campaign in 2007 and, after a close primary campaign against Hillary Clinton in 2008, he won sufficient delegates in the Democratic Party primaries to receive the presidential nomination. He then defeated Republican nominee John McCain in the general election, and was inaugurated as president on January 20, 2009. Nine months after his inauguration, Obama was controversially named the 2009 Nobel Peace Prize laureate.
When was Obama's keynote address?
July
Who did Obama campaign against in 2008?
Hillary Clinton
Where was the keynote address?
Democratic National Convention
Teaching machines to read
Some of the earliest question answering systems date back to BASEBALL and STUDENTin the 1960's. These systems tended to be limited in domain, but they are nevertheless telling of our fascination with autonomous agents that can understand and communicate in natural language to answer questions.
In recent years, the exponential increase in data and in computational power has enabled the development of ever more powerful machine learning systems. In particular, the resurgence of neural networks has led to the wide-spread adoption of deep learning models in domains ranging from machine translation to object recognition to speech recognition. Today, we announce the Dynamic Coattention Network (DCN), an end-to-end deep learning system for question answering. The DCN combines an coattentive encoder with a dynamic decoder. The combination of these two techniques allows the DCN to significantly outperform other systems on the Stanford Question Answering Dataset.
Conditional understanding of text
In most neural network approaches for Natural Language Processing, the system builds a static representation of the input document upon which to perform inference.
Although this approach has produced remarkable systems for tasks such as machine translation, we feel that it is insufficient for question answering. The reason behind this intuition is that it is incredibly difficult to build a static representation over a document to answer arbitrary questions. It is much easier to build a representation over the document to answer a single question that is known in advance.
To make this idea more concrete, let's consider an example. Suppose I gave you the following document. You can only read this document once (don't cheat!)
In the meantime, on August 1, 1774, an experiment conducted by the British clergyman Joseph Priestley focused sunlight on mercuric oxide (HgO) inside a glass tube, which liberated a gas he named "dephlogisticated air". He noted that candles burned brighter in the gas and that a mouse was more active and lived longer while breathing it. After breathing the gas himself, he wrote: "The feeling of it to my lungs was not sensibly different from that of common air, but I fancied that my breast felt peculiarly light and easy for some time afterwards." Priestley published his findings in 1775 in a paper titled "An Account of Further Discoveries in Air" which was included in the second volume of his book titled Experiments and Observations on Different Kinds of Air. Because he published his findings first, Priestley is usually given priority in the discovery.
Do you remember who published the paper? What was his occupation? How about the chemical used in his experiments on oxygen? How about when he published his findings? What was the name of the paper he published? Hopefully, you would agree that it is hard to answer these questions based on a single reading.
Now, let's try something else. I am going to give you a document and I would like you to answer the question "what is needed to make combustion happen".
Highly concentrated sources of oxygen promote rapid combustion. Fire and explosion hazards exist when concentrated oxidants and fuels are brought into close proximity; an ignition event, such as heat or a spark, is needed to trigger combustion. Oxygen is the oxidant, not the fuel, but nevertheless the source of most of the chemical energy released in combustion. Combustion hazards also apply to compounds of oxygen with a high oxidative potential, such as peroxides, chlorates, nitrates, perchlorates, and dichromates because they can donate oxygen to a fire.
Now, read the document one more time to answer the question "what role does oxygen play in combustion?".
The first approach, in which you were forced to cram as much information about the document as possible, not knowing what the questions will be, is analogous to the traditional approach of building a static representation. The second approach, in which you were able to read the document again for each question, is analogous to building a conditional representation of the document, based on the question. Hopefully, you'll agree with me that the latter is much easier than the former, since you can selectively read the document and discard information irrelevant to the question. This is exactly the idea behind our Coattention Encoder, the first of two parts of the DCN.
For each document and question pair, the Coattention Encoder builds a conditional representation of the document given the question, as well as a conditional representation of the question given the document. The encoder then builds a final representation of the document, taking into account the two previous conditional representations. A subsequent decoder module then produces an answer from this final representation.
Scanning for an answer
Given a compact representation of the document and the question, how do we come up with an answer?
Suppose we have the following document:
On Carolina's next possession fullback Mike Tolbert lost a fumble while being tackled by safety Darian Stewart, which linebacker Danny Trevathan recovered on the Broncos 40-yard line. However, the Panthers soon took the ball back when defensive end Kony Ealy tipped a Manning pass to himself and then intercepted it, returning the ball 19 yards to the Panthers 39-yard line with 1:55 left on the clock. The Panthers could not gain any yards with their possession and had to punt. After a Denver punt, Carolina drove to the Broncos 45-yard line. But with 11 seconds left, Newton was sacked by DeMarcus Ware as time expired in the half.
and the question:
Who recovered Tolbert's fumble?
Even if we do not follow American football, we have some intuition that the answer will be a person. Now, if we skim the document, we'd focus on the people that are mentioned in the document. For example, upon immediate inspection, we may hypothesize that Mike Tolbert recovered his own fumble. Upon a closer reading, we may think that Darian Stewart, who forced the fumble, also recovered the fumble. The correct answer, ultimately, is Danny Trevathan.
The Dynamic Decoder proceeds in a similar fashion, iteratively hypothesizing answers until the hypothesis no longer changes.
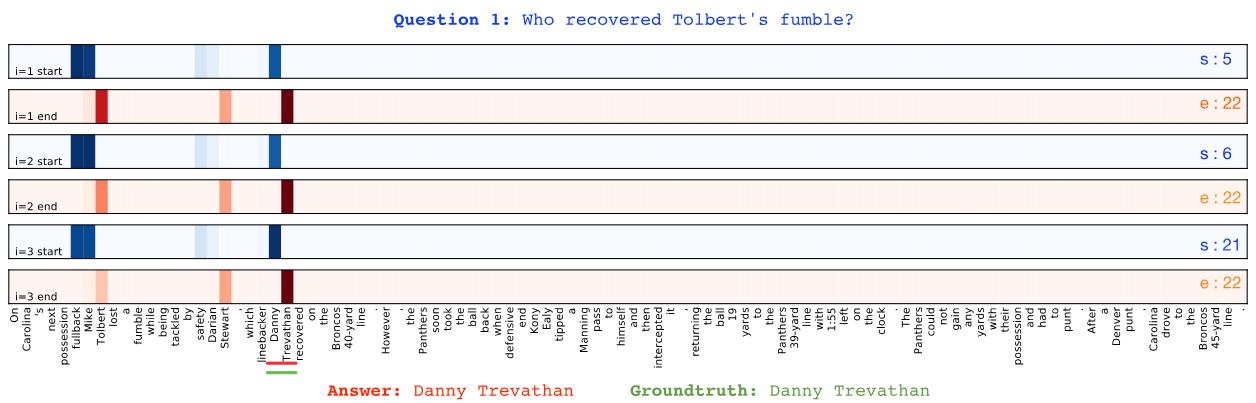
The following figure (click to expand) illustrates the model's hypothesis during 3 iterations, after which it converges on the correct answer "Danny Trevathan". Each row of the figure denotes a hypothesis for a position of the span. The first row (in blue) denotes the position for the start word during the first iteration, the second row (in red) denotes the position for the end word during the first iteration and so forth. Darker color indicates higher confidence. For example, in the first iteration, the model is more confident that the answer starts with "fullback", as opposed to "Danny", and ends with "Trevathan", as opposed to "Tolbert".

In the first iteration, the model hypothesizes the answer "fullback Mike Tolbert lost a fumble while being tackled by safety Darian Stewart, which linebacker Danny Trevathan". This initial hypothesis is clearly incorrect. Upon examination of the confidence of the hypothesis (darker means stronger confidence), we see that there is clearly three candidates under consideration; they are "fullback Mike Tolbert", "safety Darian Stewart", and "Danny Trevathan". In iterations 2 and 3, the model gradually shifts confidence to the answer "Danny Trevathan", ultimately stopping in iteration 3 after which its hypothesis no longer changes.
A new state of the art for question answering
By combining the Coattention Encoder and the Dynamic Decoder, the Dynamic Coattention Network achieves state of the art performance on the Stanford Question Answering Dataset. Compared to systems developed by the Allen Institute for Artificial Intelligence, Microsoft Research Asia, Google, and IBM, our model makes significant improvements and outperforms all other approaches. The Dynamic Coattention Network is the first model to break the 80% F1 mark, taking machines one step closer to the human-level performance of 91.2% F1 on the Stanford Question Answering Dataset. The full leaderboard for the Stanford Question Answering Dataset is available here.
Citation credit
Caiming Xiong, Victor Zhong, Richard Socher. 2016.
Dynamic Coattention Networks For Question Answering
Acknowledgement
We thank Kazuma Hashimoto, Bryan McCann, and Richard Socher for their help and comments.