 Blog Home
Blog HomePrototypical Contrastive Learning: Pushing the Frontiers of Unsupervised Learning
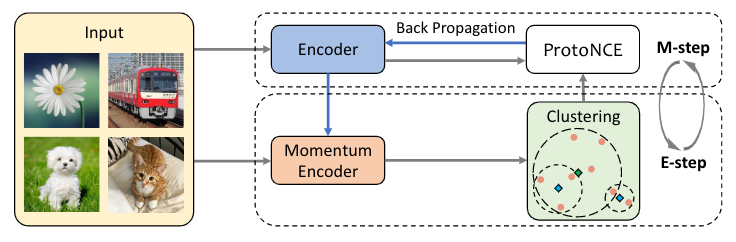
In our study [1], we introduce a new unsupervised learning method that is able to train deep neural networks from millions of unlabeled images. Our method, Prototypical Contrastive Learning (PCL), unifies the two schools of unsupervised learning: clustering and contrastive learning. PCL pushes the frontiers of unsupervised learning, the holy grail of machine learning and artificial intelligence, and makes an important step closer to a future where machines can teach themselves without any human guidance.
TL; DR: Prototypical Contrastive Learning unifies clustering and contrastive self-supervised learning to push the frontiers of unsupervised learning.

Why unsupervised learning?
Deep neural networks have achieved unprecedented progress in many tasks, such as image classification and object detection. Most of the progress is driven by the supervised learning paradigm, where good performance largely relies on a large number of human-annotated labels (e.g. ImageNet). However, collecting manual labels is expensive and very difficult to scale up. On the other hand, there exists an almost infinite amount of unlabeled images freely available on the Internet. Unsupervised learning is uniquely suited to exploit the unlimited goldmine of unlabeled data.
First, let’s talk about two popular schools of unsupervised learning algorithms: clustering and contrastive learning.
Clustering: a classical school of unsupervised learning
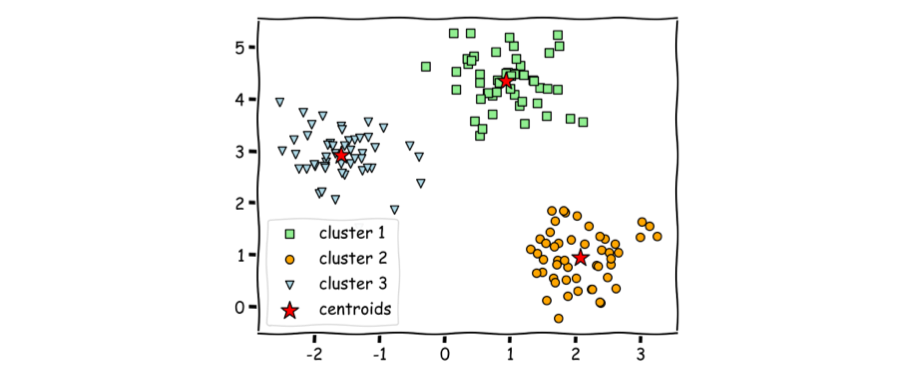
Clustering is one of the most common and long-standing unsupervised learning tasks in machine learning. It is the process of partitioning the dataset into a number of groups, such that similar data points are grouped together, while dissimilar data points are in different groups.
Among all the clustering methods, K-means clustering is one of the simplest and most popular. It is an iterative algorithm that tries to partition the dataset into K groups (clusters) where each data point belongs to only one cluster. A data point is assigned to a cluster in a way that the sum of the squared distance between each of the data points in the cluster and the cluster's centroid (arithmetic mean of all the data points that belong to that cluster) is at the minimum.
Contrastive Learning: an emerging school of unsupervised learning
With the emergence of deep neural networks, contrastive unsupervised learning has emerged as a popular school of methods which trains deep networks without using labels. The trained network should be able to extract meaningful features (representations) from images, which will boost the performance of other downstream tasks. Since contrastive unsupervised learning usually involves the model learning useful representation from the data by itself, it is also commonly referred to as contrastive self-supervised learning.
Many of the state-of-the-art contrastive learning methods (e.g. MoCo [2] and SimCLR [3]) are based on the task of instance discrimination. Instance discrimination trains a network to classify whether two image crops come from the same source image, as shown in Figure 1(a). The network (e.g. a CNN encoder) projects each image crop into an embedding, and pulls the embeddings from the same source closer to each other while pushing embeddings from different sources apart. By solving the task of instance discrimination, the network is expected to learn a useful representation of the image.
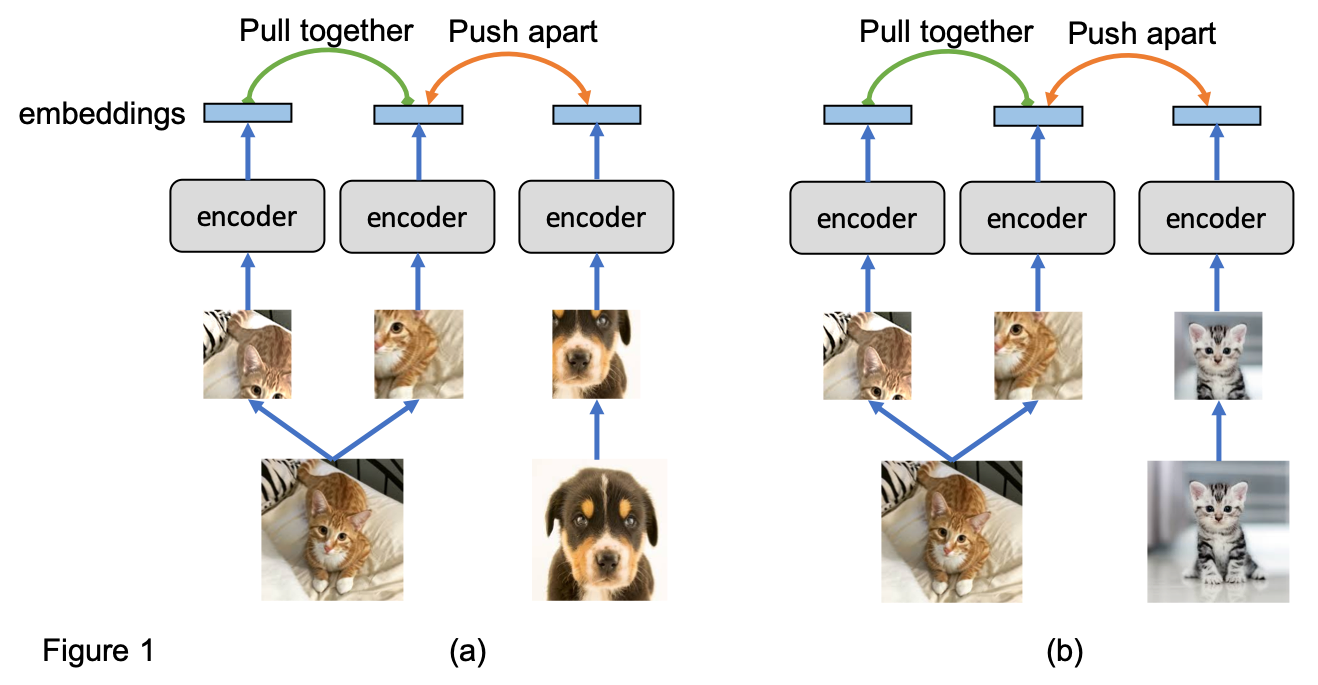
Instance discrimination has shown promising performance gain for unsupervised representation learning. However, it has two limitations. First, different instances could be discriminated by exploiting low-level cues, so the network does not necessarily learn useful semantic knowledge. Second, as shown in Figure 1(b), images from the same class (cat) are treated as different instances, and their embeddings are pushed apart. This is undesirable because images that share similar semantics should have similar embeddings.
To address the above weaknesses, we propose a new method for unsupervised representation learning: Prototypical Contrastive Learning (PCL).
Prototypical Contrastive Learning: unifying contrastive learning and clustering
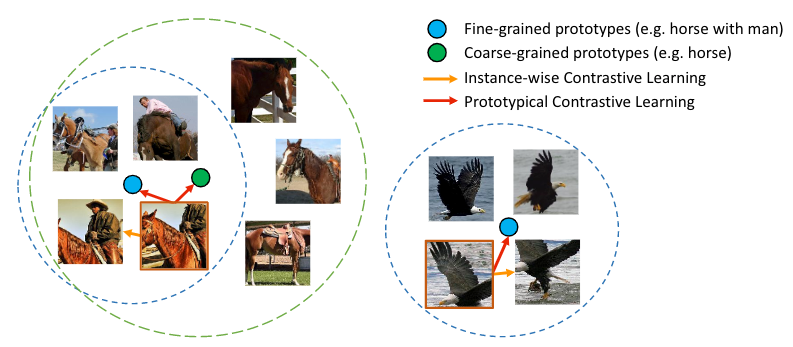
Prototypical Contrastive Learning is a new method for unsupervised representation learning which brings together the advantages of both contrastive learning and clustering. In PCL, we introduce a ‘prototype’ as the centroid for a cluster formed by similar images. We assign each image to multiple prototypes of different granularity. The training objective is to pull each image embedding closer to its associated prototypes, which is achieved by minimizing a ProtoNCE loss function.
At a high-level, PCL aims to find the Maximum Likelihood Estimation (MLE) of model parameters, given the observed images x:
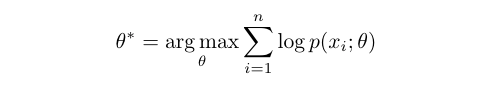
We introduce prototypes C as the latent variable related to the observed data, and propose an Expectation-Maximization algorithm to solve the MLE. In the E-step, we estimate the probability of the prototypes by performing K-means clustering. In the M-step, we maximize the estimated log-likelihood by training the model to minimize a ProtoNCE loss:

Under the Expectation-Maximization framework, we can show that previous contrastive learning methods [2,3] form a special case of PCL.
How well does PCL perform?
Typically, an unsupervised learning method is evaluated by transferring the pretrained model to downstream tasks, similar to the way ImageNet pretrained models have been widely used in many computer vision tasks. The general rule is: a good pretrained model should produce good performance on a new task with limited training data and limited fine-tuning.
We evaluate PCL on three tasks. In all cases, it achieves state-of-the-art performance.
- Low-shot transfer learning
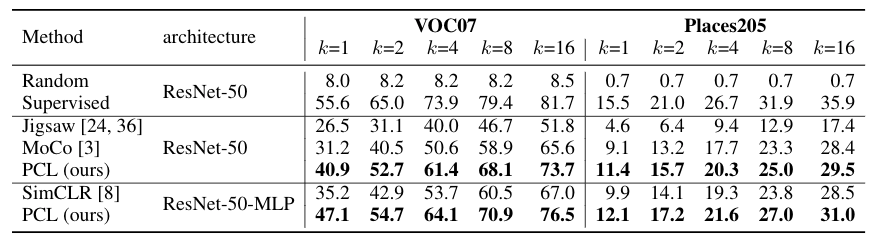
First, we transfer a ResNet model pretrained on the unlabeled ImageNet dataset to two new tasks: object recognition on VOC07 dataset and scene classification on Places205 dataset. For each task, we are only given very few (k) labeled samples. We train a linear support vector machine using the unsupervised learned representation. As shown in the table below, PCL achieves substantial performance improvement compared to previous methods, with ~10% improvement on VOC.
2. Semi-supervised learning
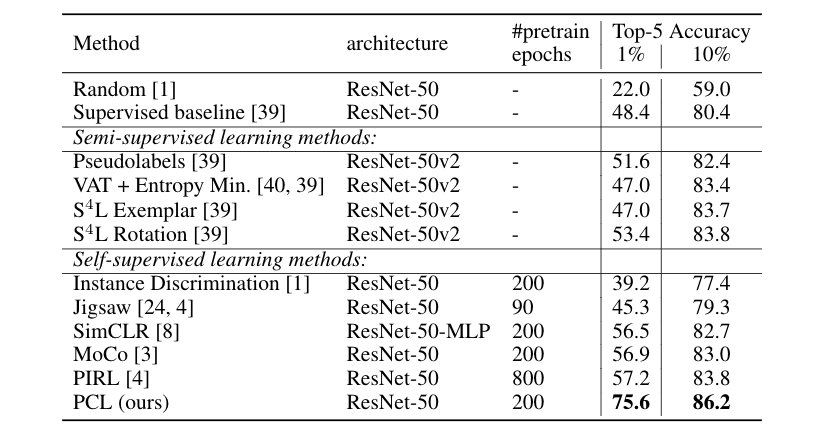
Next, we evaluate PCL on semi-supervised image classification. In this task, we pretrain the ResNet model on unlabeled ImageNet images, and fine-tune a classification model using 1% or 10% of ImageNet images with labels. Again, PCL outperforms other methods by a large margin, with 18% improvement in top-5 accuracy.
3. Object detection
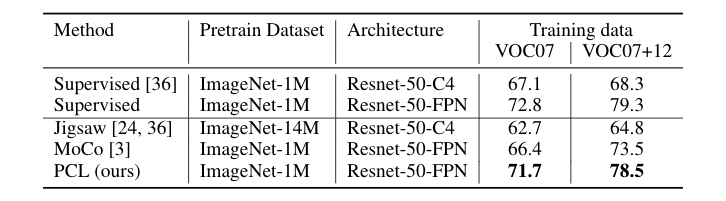
We further assess the generalization capacity of the learned representation on object detection. We train a Faster R-CNN model on VOC07 or VOC07+12, and evaluate on the test set of VOC07. As shown below, PCL substantially closes the gap between self-supervised methods and supervised methods to only 1% difference.
What does the learned representation look like?
To better understand what the representation learned by PCL looks like, we plot the t-SNE visualization for images from the first 40 classes of ImageNet. We can see that the representation learned by PCL can cluster images from the same class together.

What’s next?
We have demonstrated the power of PCL in teaching deep neural networks using purely unlabeled images. There is a vast potential for extending the philosophy of PCL to other domains beyond image, such as video, text, or speech. We hope that PCL can spur more research in the promising area of unsupervised learning, and push towards a future in AI where manual annotation is no longer an essential piece of model training.
If you are interested in learning more, please check out our paper and feel free to contact us at junnan.li@salesforce.com.
References
1. Junnan Li, Pan Zhou, Caiming Xiong, Richard Socher, Steven C.H. Hoi. Prototypical contrastive learning of unsupervised representations. arXiv:2005.04966, 2020.
2. Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, 2020.
3. Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. arXiv:2002.05709, 2020.