 Blog Home
Blog HomeNear-Negative Distinction: Re-Thinking Text Generation Evaluation
TL;DR: We introduce an automated method for evaluating the quality of AI-generated text by repurposing prior human evaluation data. The method is called Near-Negative Distinction and requires the evaluated models to pass a series of tests that measure if the models can avoid prior models’ mistakes (near negatives). We implement NND on three text generation tasks and show that it correlates better with human rankings of models than other common metrics.
(Some images in the blog post were generated using Dall-E 2 + manual editing.)
Recent progress in text generation can be tracked in many domains and tasks, from stellar 100+ language translation models, to book summarization or collaborative creative writing. The ability of NLG models to make creative decisions and write seemingly novel content is exciting. Yet the open-ended nature of text generation is the cause for some headaches in the field: how to evaluate model performance on tasks where many answers are equally good. Let’s look at an example.
Motivational Example
Let’s consider how to evaluate an AI model that is trained to answer any kind of question. Recent models are getting better at answering questions that require common knowledge and reasoning. For example, when asking GPT-3 “If I put some cheese in the fridge, will it melt?”, it answers with “No, it will become cold and hard.”
Researchers have annotated a series of 300 questions (called the Challenge 300 dataset), grading the answers from several QA models, to study when they succeed and when they fail.
Let’s look at an example in particular. Given the question: “How could one divert an asteroid heading directly for the Earth?”

The dataset contains outputs from several models, each annotated with a credit of 0 or 1, depending on if the human annotator judged the answer to be correct. For example, GPT3-Davinci and Macaw-11b answer with:


Annotators gave GPT3-davinci full credit for its answer (100%), while Macaw-11b received no credit (0%).
By annotating model answers for many questions, GPT3-davinci received an average credit of 65%, and Macaw-11b 75%. Conclusion of the study: Macaw-11b is better at answering common-sense questions than GPT3-davinci.
Problems with human annotation arise once the study is completed.
Inevitably, a new QA model comes out – call it Shiny-new-QA – and researchers want to compare it to prior models to know if it is better, and if so by how much. There are two options: study extension, in which the original study is extended by labeling new model outputs on original inputs or running a study from scratch. Both are limiting, as it is typically impossible to recruit the original study’s annotators, lowering the chance of a fair and reproducible comparison when extending a study. Choosing to create a new study discards previous annotation efforts, requiring researchers to incur the high cost of running a new study just to evaluate a single model.
As an alternative to human evaluation, reference-based automatic evaluation is a popular method to evaluate NLG models.
“Why involve manual work if it can be automated.”
Automatic evaluation has a one-time cost to collect gold-standard outputs (or references) for a set of held-out inputs. Present and future models are then evaluated by measuring how similar their outputs are to the references. Accurately assessing text similarity is a thorny subject, but methods largely fall into n-gram overlap measures (BLEU, ROUGE, etc.) based roughly on word overlap between model output and reference, and neural-based measures (BERTScore, etc.) in which a trained neural network assesses similarity. Reference-based evaluation is adequate for NLG tasks that have limited room for deviations, such as translation, in which similarity to a single reference is sufficient to assess quality. Yet, many NLG tasks – such as summarization, dialogue response generation, and many more – are open-ended and are suited for single-reference comparisons.
Looking back at our generative QA example. Imagine that Shiny-new-QA answers with:

If we treat GPT3-davinci’s answer as a reference (because the spacecraft answer received 1/1 credit) and score new answers based on their similarity to it, new models generating novel and potentially better solutions will be unfairly penalized.
Going further, properly evaluating an answer’s quality requires the evaluator to have some background in astronomy and physics to understand and judge the quality of proposed answers. In some sense, for creative text generation tasks, evaluation is at least as hard as the generation task itself.
Near-Negative Distinction: automatic evaluation that gives a second life to human evaluation annotations.
In the Near-Negative Distinction (NND) framework, instead of evaluating a model by comparing its outputs to the one true reference – as is the case in other automatic evaluations – a model is evaluated based on how likely it is to generate two existing candidates of varying quality. If the model is more likely to generate the candidate rated higher by humans (spacecraft diversion) then the model is scored higher according to NND, mirroring pre-existing human evaluation.

Instead of asking new models to generate their own outputs, we see how likely they are to generate outputs we already have annotations for, and see if they are more likely to generate good candidates (spacecraft diversion), and avoid poor candidates (orbiting space shuttle).
NND Evaluation
Let’s go over how NND works in practice.

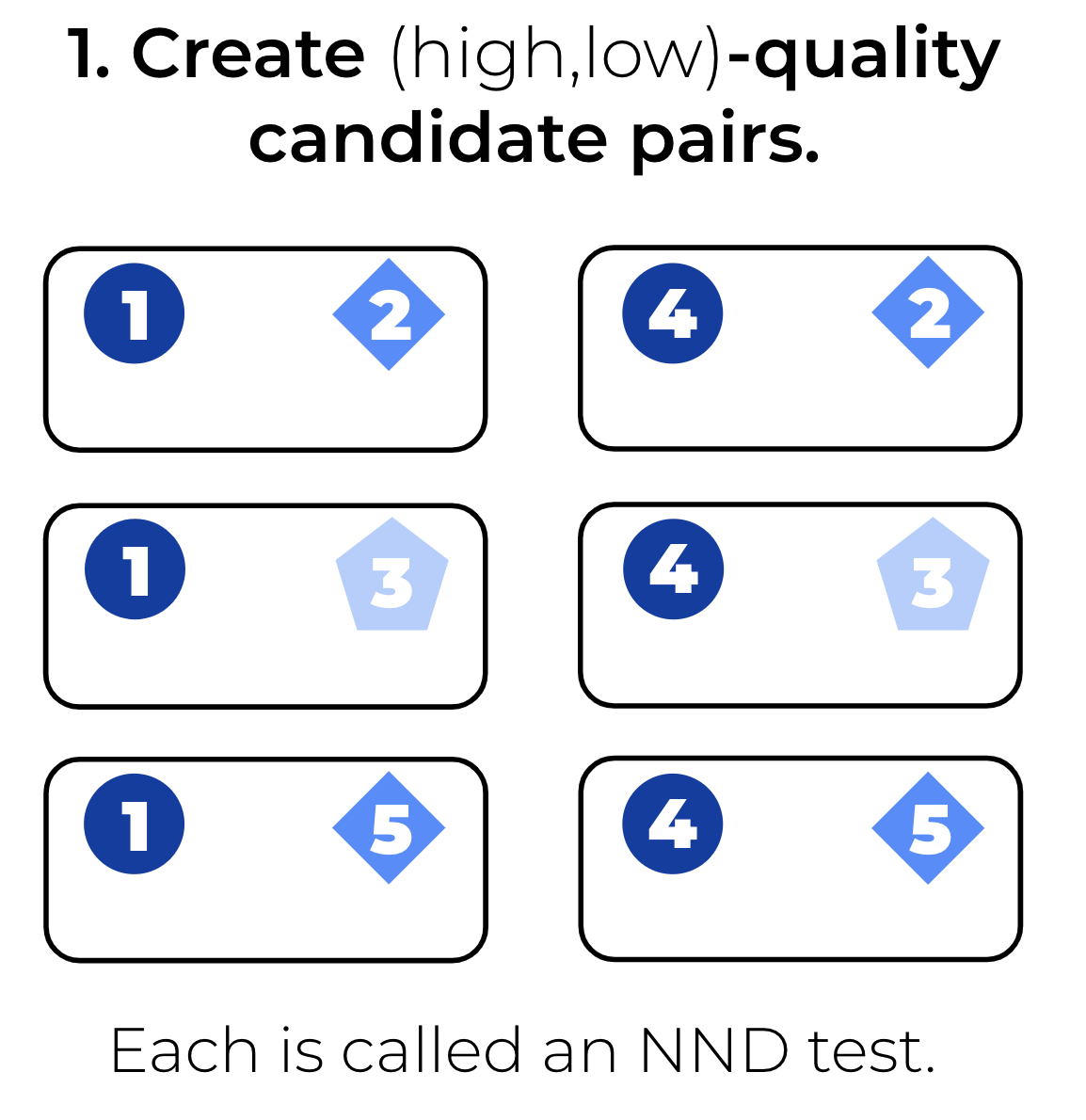
First, we use the annotated candidates to create NND tests, which correspond to pairs of candidates for which a preference is known, in this case, we prefer a candidate labeled as “No Error” over any other candidate (Not Fluent, or Not Factual). Note that we do not create NND tests with pairs for which we do not know a preference order (for example candidates 2 vs. 3).
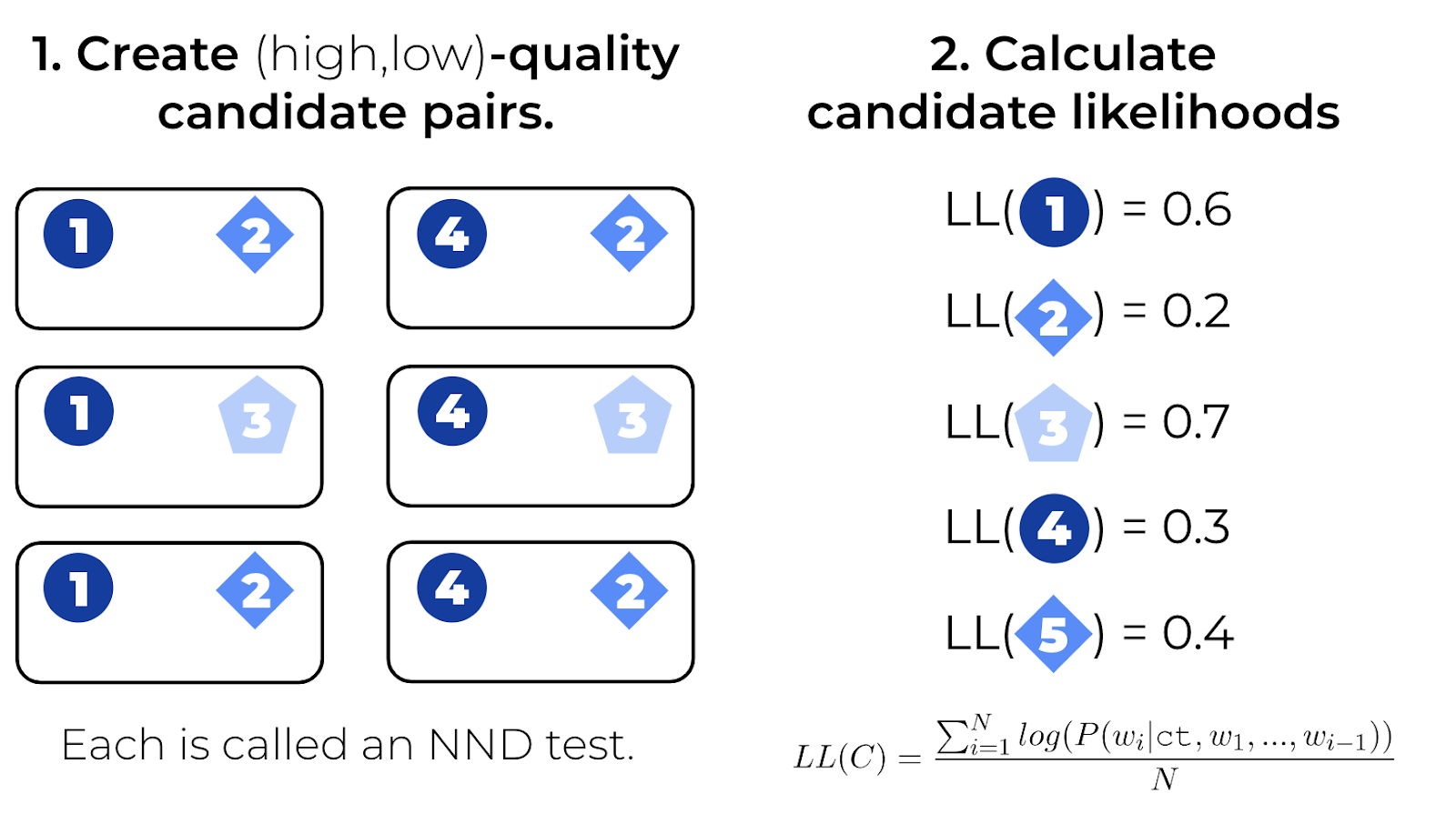
Second, we calculate the likelihood that a new model (like Shiny-new-QA) assigns to each candidate. This is possible as most text generation models are language models that can assign a probability to any sequence of words.

Third, we administer each NND test. If the evaluated model assigned a higher probability to the high-quality candidate, the model passes the test (tests 1-2, 4-2, and 1-5), otherwise, it fails the test (tests 1-3, 4-3, 4-5).
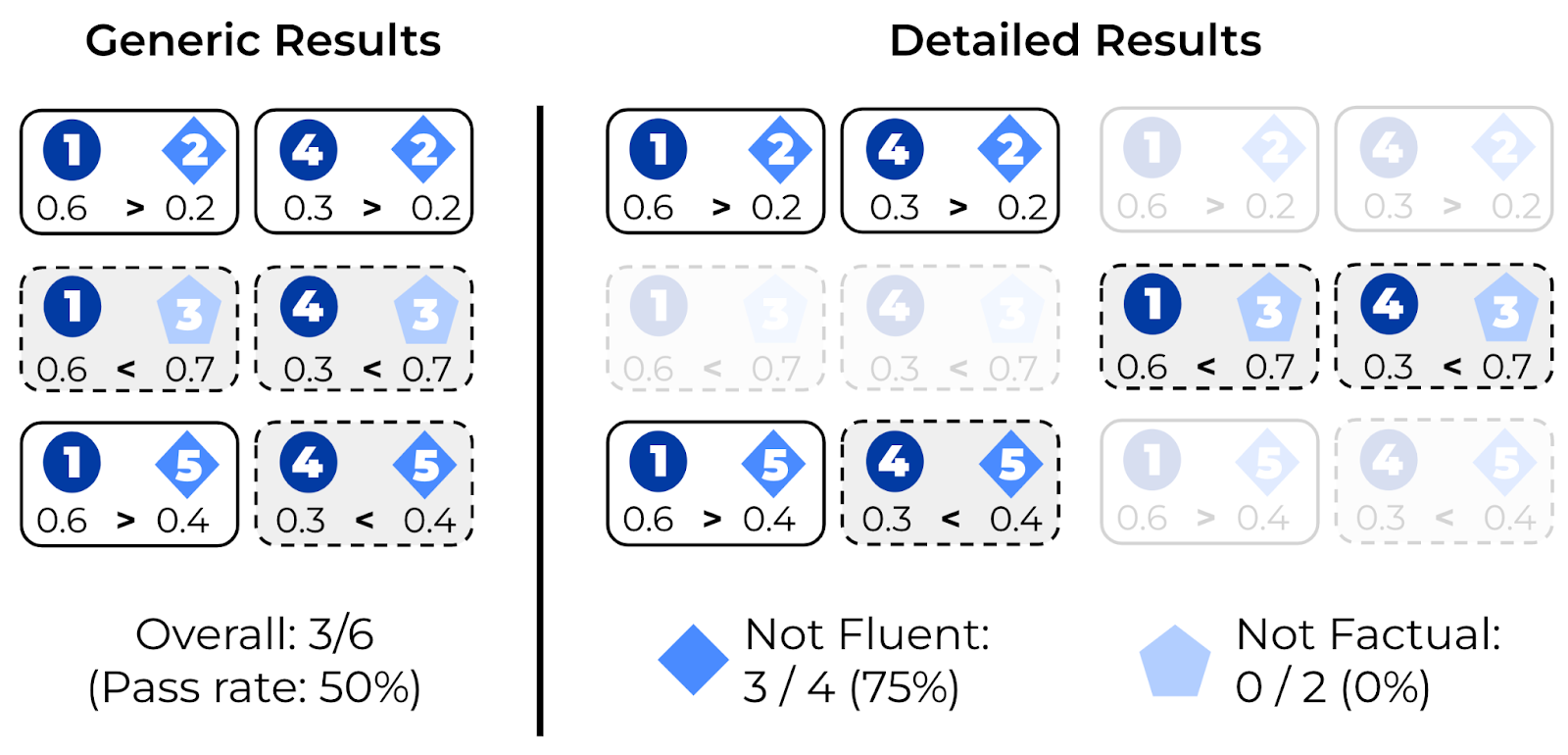
NND results are compiled in two ways. First, a generic result is computed as the overall percentage of tests passed. In the example, the model passes 3 / 6 NND tests, with an overall pass rate of 50%. The generic NND result is useful for model comparisons, as it is a single number.
More detailed results can be computed by looking at pass rates on the tests involving specific error categories. In our example, the model passes 3 / 4 NND tests involving the Not Fluent error (a pass rate of 75%), and 0 / 2 NND tests with a Not Factual error. The detailed NND breakdown can be useful to inspect model strengths and weaknesses.
That’s the theory, let’s now see how to use NND in practice.
Applying NND Evaluation
Question Generation (QG)
We create an NND test set based on the Quiz Design annotations[1], in which teachers evaluated whether questions should be included in a reading comprehension quiz.
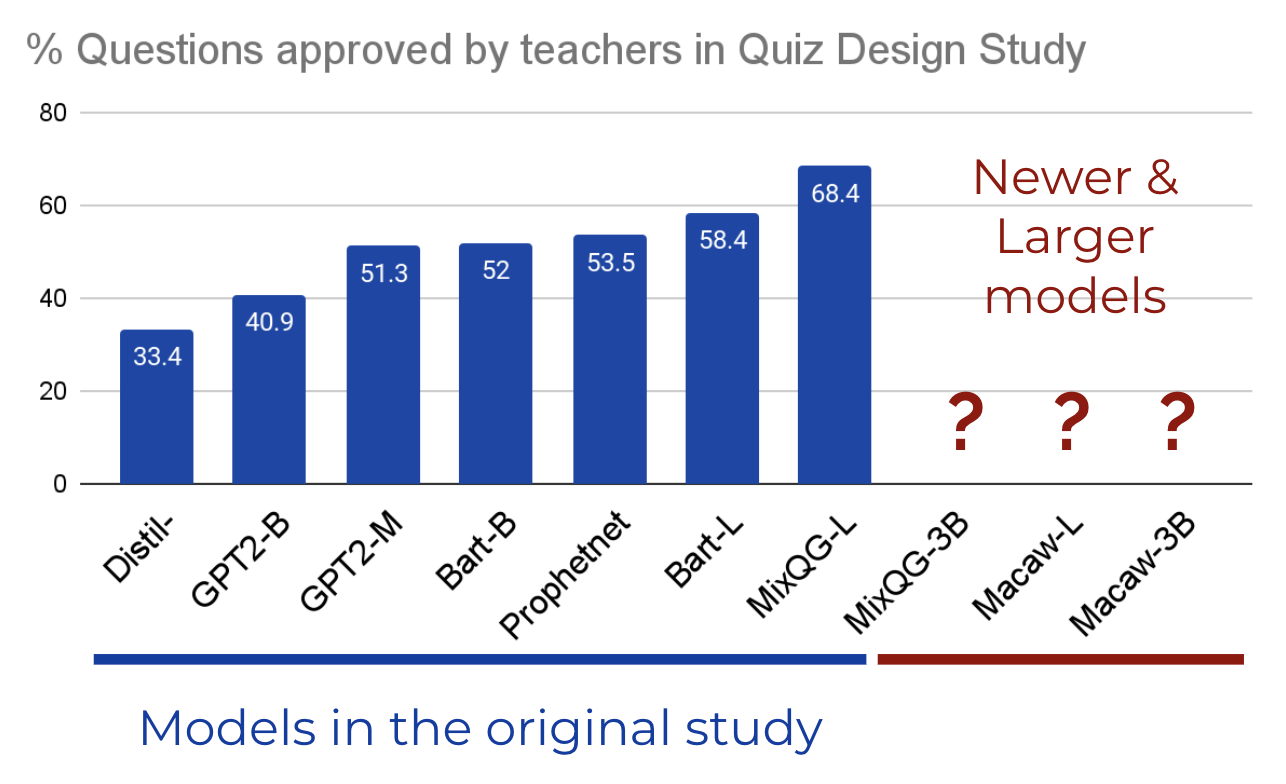
At the time of the study, the authors evaluated 7 models, finding that more recent and larger QG models – such as MixQG-Large – generated significantly better questions than smaller and older models. Because of latency issues during the study, the largest model size (3B) could not be included in the study, as well as newer Macaw models which were not published at the time.
How would the newer and larger models compare in the study?
We extrapolate with NND evaluation.
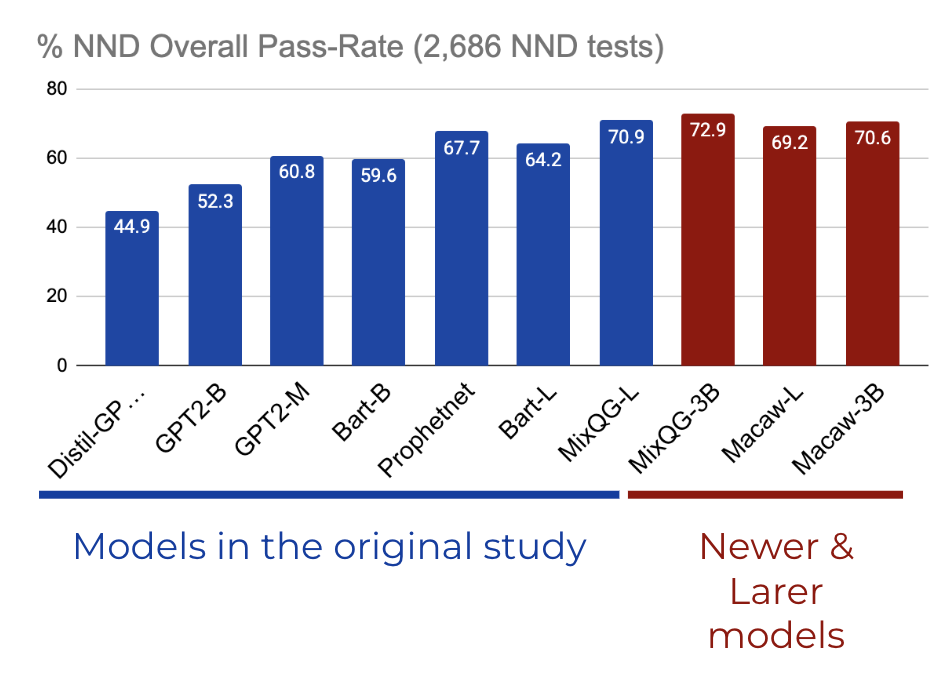
MixQG-3B achieves the highest pass rate, improving by 2% over MixQG-Large, which had the highest performance in the original study. For the curious, the NND paper includes a more detailed analysis leveraging the error category annotations and shows that although Macaw-3B does not outperform MixQG-3B overall, it achieves the best performance at avoiding disfluency errors.
Summarization
Another advantage of NND is that it does not require generating candidates, which is both computationally expensive and introduces a confounding factor: the decoding strategy (is my model better because I used a fancier decoding strategy, or because the underlying model is better).
Further, because NND evaluation is relatively computationally inexpensive, it can be applied not only to final models but also to temporary model checkpoints during training.
To demonstrate feasibility, we create an NND test set leveraging SummEval[2] and use it to evaluate a Bart-Large model during training, performing an NND evaluation every 200 gradient steps.
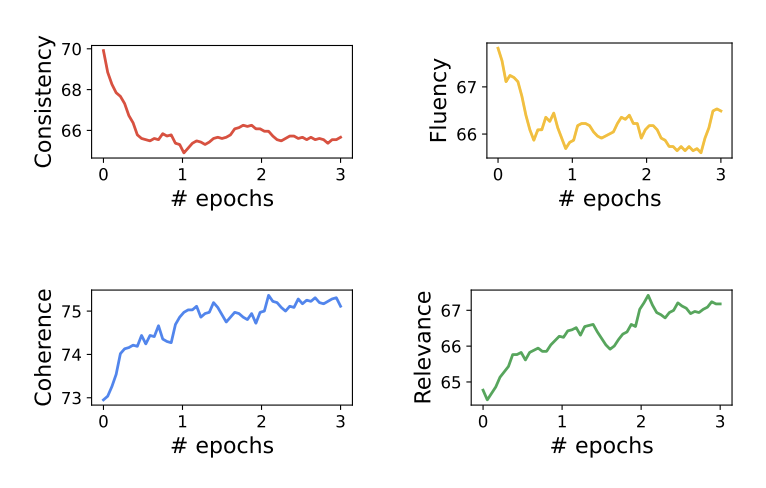
We find that as the model is trained, NND pass rates decrease on consistency and fluency errors, while they increase on coherence and relevance tests. This surprising result shines a light on the training dynamics of supervised teacher forcing used to train the model: the model gradually learns to become more abstractive, at the cost of factual consistency and fluency.
More Information and Resources
- Check out the paper for more experiments and technical detail. The paper importantly shows that NND correlates better with manual model rankings than automatic metrics, and discusses the strengths and limitations of the NND framework. Some important limitations include the reliance of NND on model likelihood and prior model errors, and the limitation that we’ve only tested NND evaluation on three English language tasks.
- We also have the code available on GitHub (salesforce/nnd_evaluation), for few-line examples of how to evaluate your NLG models using existing NND test sets.
- Do you have annotations that could be repurposed for NND evaluation? Please reach out (by email or create a GitHub issue) to contribute NND test sets for new tasks and languages that can benefit the community.
- Link to the EMNLP 2022 paper: https://arxiv.org/abs/2205.06871v2
- Link to code & existing resources: https://github.com/salesforce/nnd_evaluation
- Contact: plaban@salesforce.com
About the Author
Philippe Laban is a Research Scientist at Salesforce Research, New York working at the intersection of NLP and HCI with a particular interest in the evaluation of text generation tasks, including summarization, simplification, and question generation.