 Blog Home
Blog HomeMoPro: Webly Supervised Learning with Momentum Prototypes
TL; DR: We propose a new webly-supervised learning method which achieves state-of-the-art representation learning performance by training on large amounts of freely available noisy web images.
Deep neural networks are known to be hungry for labeled data. Current state-of-the-art CNNs are trained with supervised learning on datasets such as ImageNet or Places, which contain millions of images manually labeled by humans. However, collecting human annotations is extremely expensive and prohibitive for common practitioners. Researchers have explored self-supervised learning which utilizes unlabeled data. However, current self-supervised learning methods require extremely long training time, and have yet consistently shown superior performance compared to supervised learning.
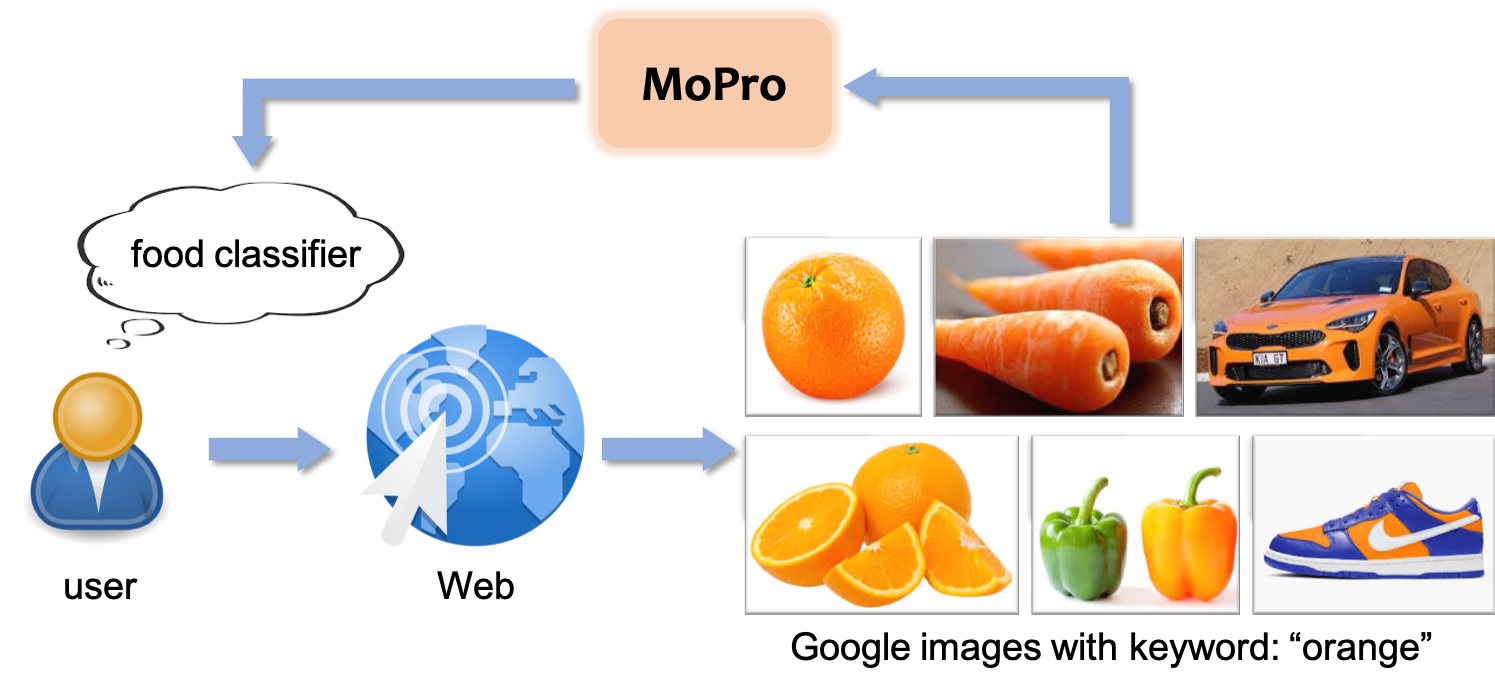
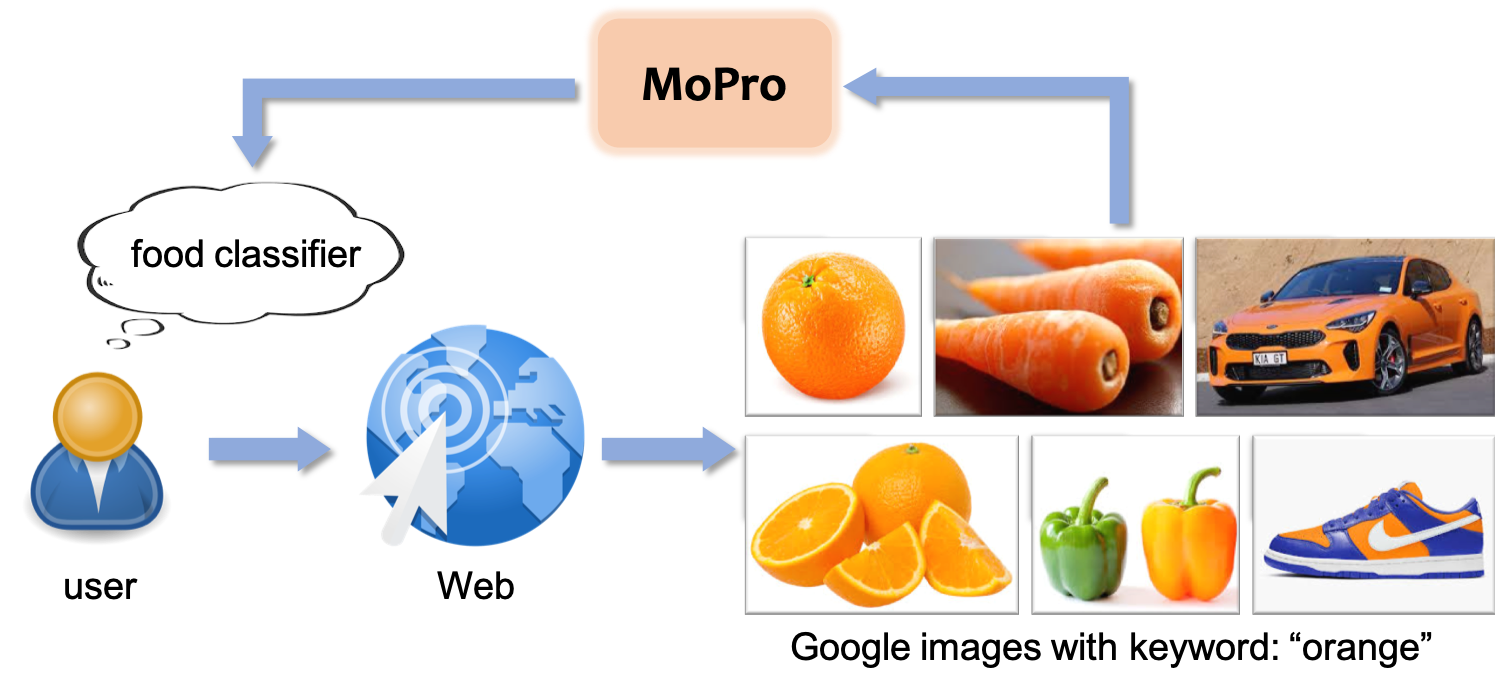
An effective solution to reduce annotation cost is Webly-supervised learning, where deep neural networks are trained on weakly-labeled images automatically collected from the Web. The keywords or tags associated with the images could be used as training labels. However, Web images are inherently noisy. For example, a search on Google Images with the keyword “orange” returns the following images, some of which would be detrimental if the goal was to build a food classifier.
In our paper [1], we introduce MoPro, a new weakly-supervised learning method that efficiently trains deep neural networks on large-scale noisy Web datasets. Our model trained with MoPro exhibits superior performance in adapting to a variety of new visual tasks, such as few-shot image classification and object detection. MoPro frees deep learning practitioners from the tedious task of collecting human annotations, and enables future computer vision models to fully harvest the enormous amount of images online. Next, we will explain how MoPro works.
Noise Correction with Momentum Prototypes
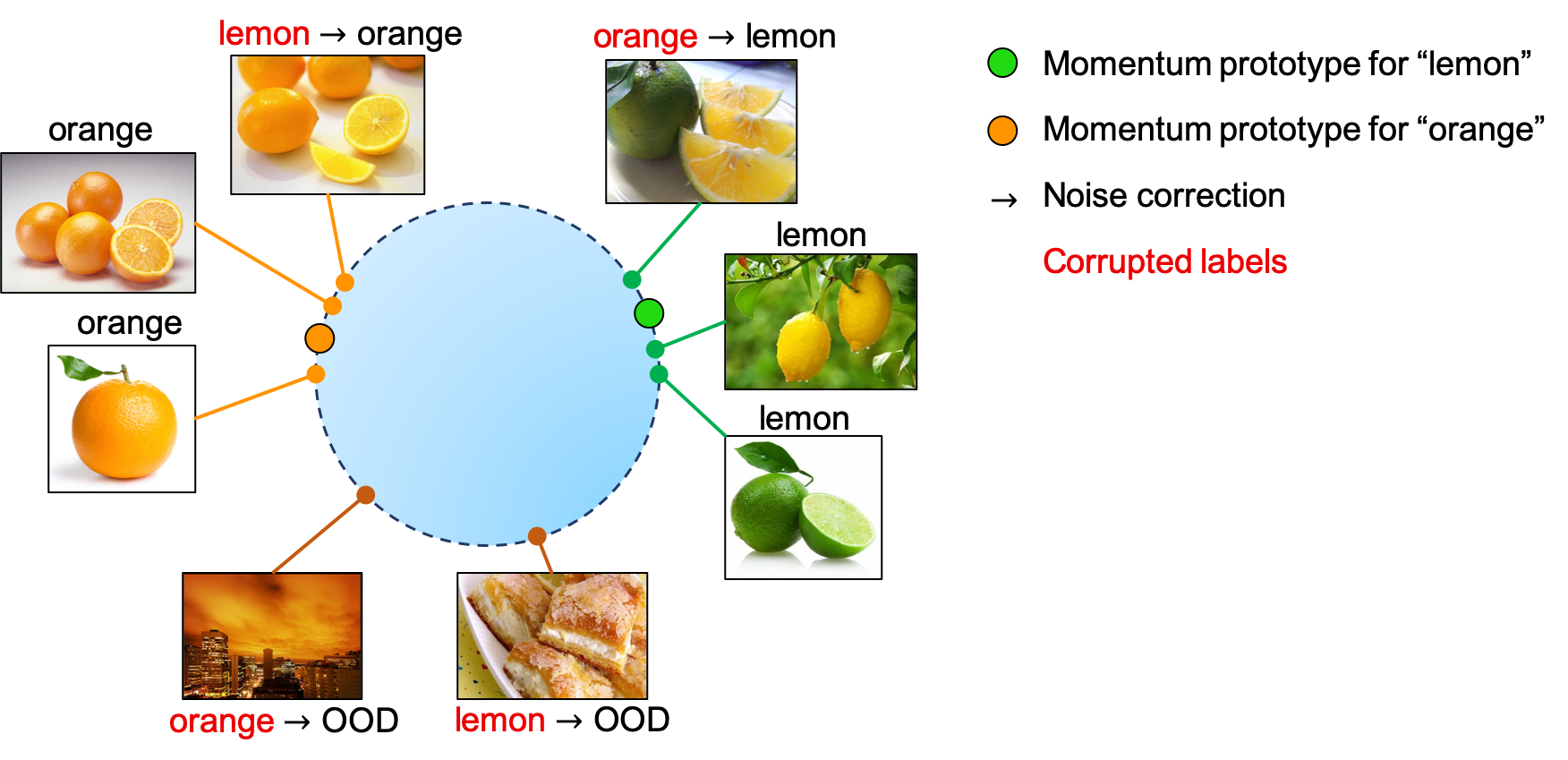
Images collected from the Web are noisy. The two major types of noise are label noise and out-of-distribution (OOD) noise. Label noise occurs when a wrongly-labeled image has a true label that we care about, i.e. its correct label belongs to the set of classes that the model aims to predict. OOD noise, on the other hand, are images with true labels that we do not care about, i.e. their correct labels are out-of-scope for the classifier. Take the images above as an example, if we want to build a food classifier, then the images with carrot and pepper would have label noise, whereas the sneaker and car images would be OOD samples. Therefore, label noise can be cleaned by re-assigning a corrected label to the noisy sample, while OOD noise can be cleaned by removing OOD samples from classifier training.
MoPro performs noise cleaning with Momentum Prototypes. First, all images are projected into low-dimensional embeddings by a CNN encoder. Then, we define the momentum prototype for a class as the moving-average embedding for all samples that are assigned to this class. We can identify noisy samples based on their distance w.r.t to the prototypes. We consider an image to have label noise if it is close to a prototype of a different class, and we re-assign the sample to its closest prototype’s class. On the other hand, if an image is far away from all the prototypes, we consider it as an OOD sample.
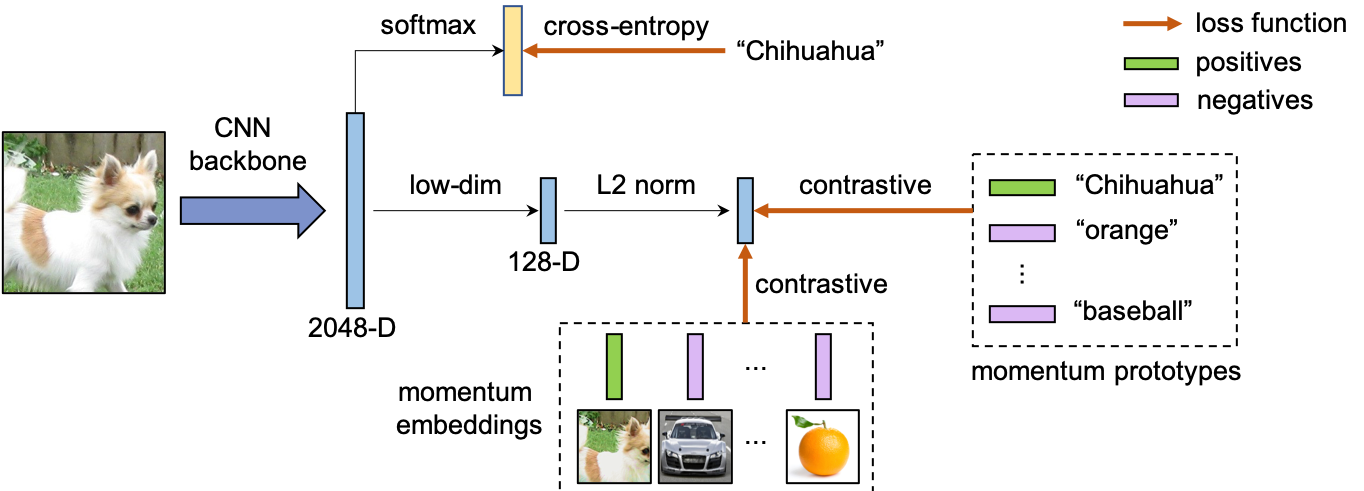
Contrastive Representation Learning with Momentum Prototypes
For each mini-batch during training, we first perform noise cleaning, and then we update the model by jointly optimizing a cross-entropy loss and two contrastive losses. We optimize a prototypical contrastive loss which encourages a sample to be closer to its assigned prototype, and an instance contrastive loss which encourages different augmentations of the same image to have similar embeddings. See this blog for more details on contrastive learning.
Pre-training on Web Datasets
We use MoPro to pre-train a ResNet-50 model on the WebVision dataset, which consists of noisy images crawled from Google and Flickr. We experiment with three versions of WebVision with different sizes: (1) WebVision-V1.0 contains 2.44m images with the same classes as the ImageNet (ILSVRC 2012) dataset; (2) WebVision-V0.5 is a randomly sampled subset of WebVision-V1.0, which contains the same number of images (1.28m) as ImageNet; (3) WebVision-V2.0 contains 16m images with 5k classes. Our code and pretrained models are available.
Transfer Learning
We evaluate the pre-trained model on a variety of down-stream tasks. We compare MoPro with multiple baselines including (1) supervised learning on ImageNet, (2) weakly-supervised learning on WebVision with vanilla cross-entropy loss, (3) state-of-the-art self-supervised learning methods such as PCL [2], MoCo [3], SimCLR [4], BYOL [5], and SwAV [6].
1. Low-resource Image Classification
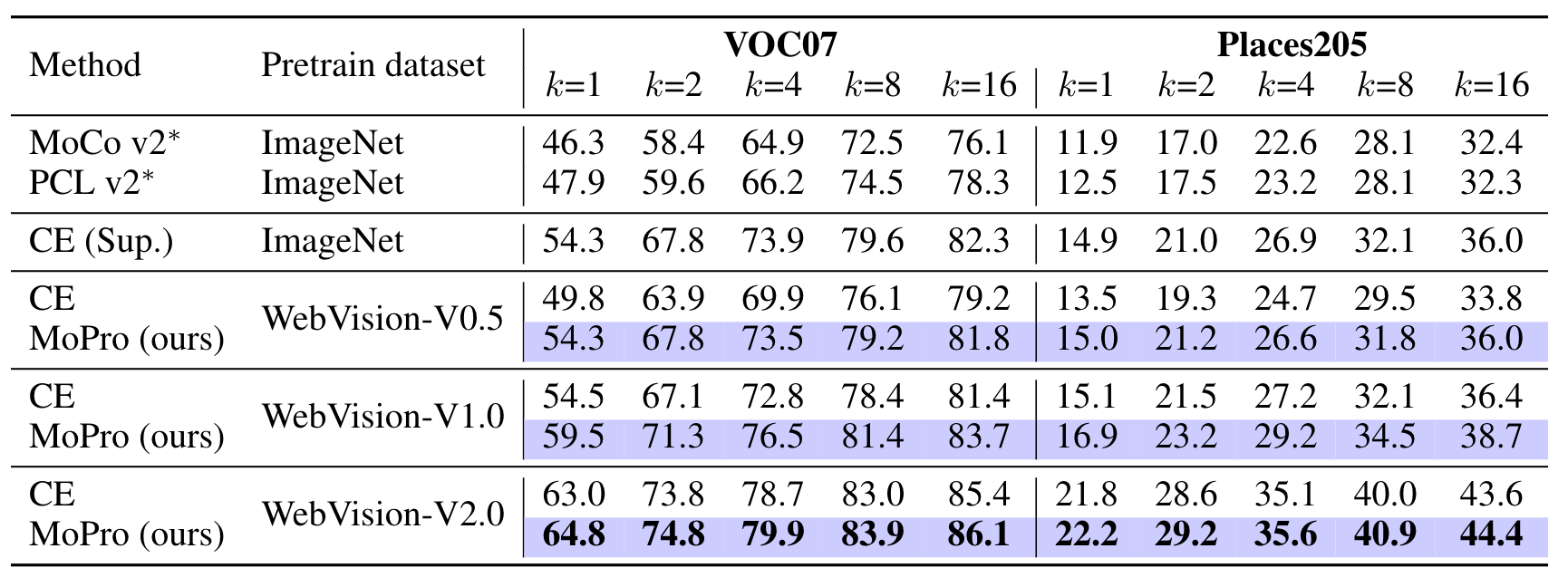
First, we transfer the pre-trained model to two new tasks: object recognition on VOC07 dataset and scene classification on Places205 dataset. For each task, we are only given very few (k) labeled samples. We train a linear support vector machine using the fixed learned representation. As shown in the following table, when pre-trained on WebVision datasets, MoPro consistently outperforms the vanilla CE method. When compared with ImageNet pretrained models, MoPro substantially outperforms self-supervised learning (PCL v2), and achieves comparable performance with supervised learning even when the same amount of web images (i.e. WebVision-V0.5) is used. Our results for the first time show that weakly-supervised learning can be as powerful as supervised learning under the same computation budget.
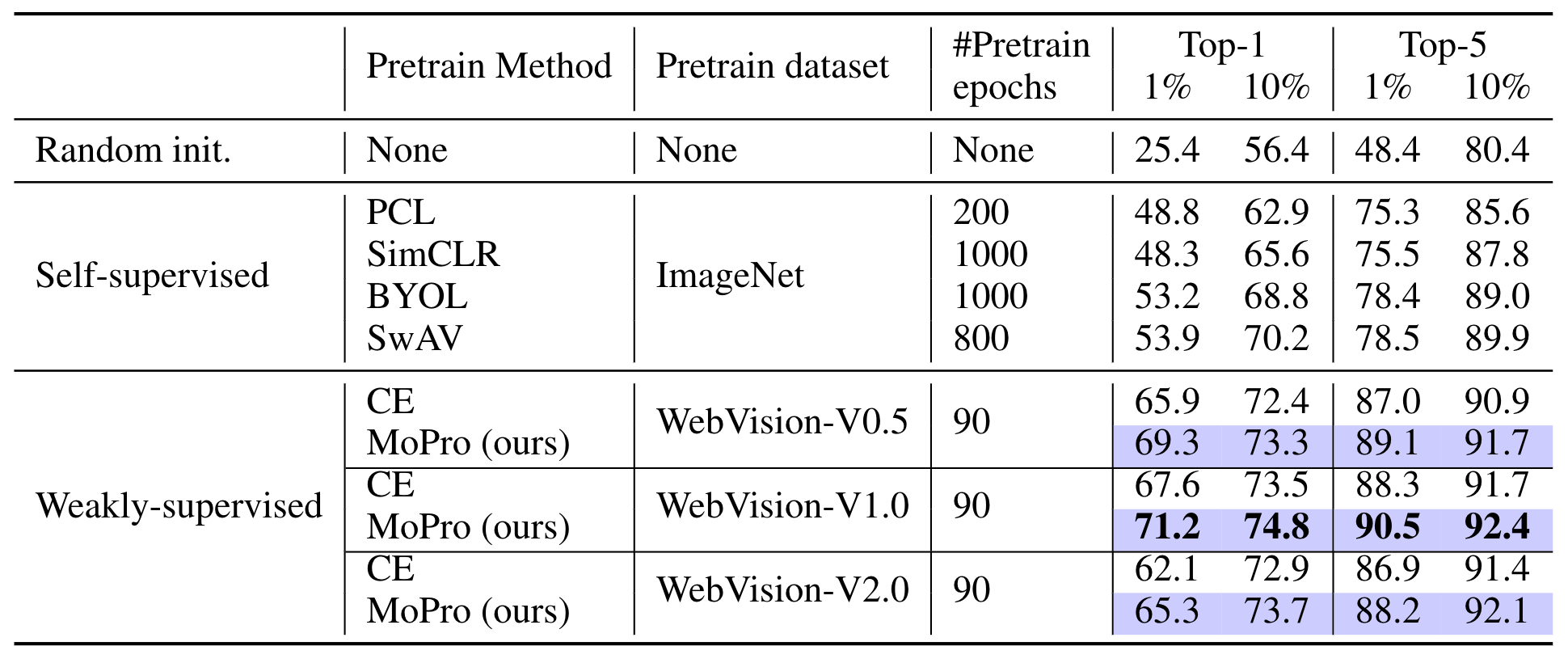
Next, we transfer the model to ImageNet by fine-tuning it using 1% or 10% of ImageNet training samples. As shown in the following table, MoPro consistently outperforms vanilla CE when pre-trained on WebVision.Compared to self-supervised learning methods pre-trained on ImageNet, weakly supervised learning achieves significantly better performance with fewer number of epochs.
2. Object Detection
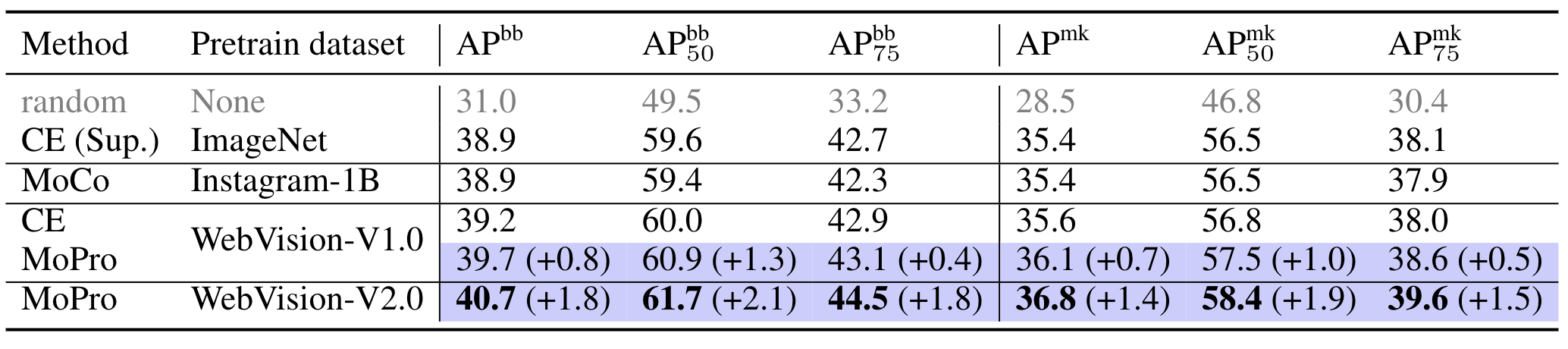
We further transfer the pretrained model to object detection and instance segmentation tasks on COCO. Weakly-supervised learning with MoPro outperforms both supervised learning on ImageNet and self-supervised learning (MoCo) on one billion Instagram images.
3. Model Robustness
Last but not least, we evaluate the model’s robustness to distribution shifts. We test the model on two benchmarks: (1) ImageNet-R which contains various artistic renditions of object classes from the original ImageNet dataset, and (2) ImageNet-A which contains natural images where ImageNet-pretrained models consistently fail due to variations in background elements,color, or texture. We report both accuracy and the calibration error, which measures the alignment between a model’s confidence and its accuracy. As shown below, weakly-supervised learning with MoPro shows significantly higher accuracy with better calibration.

What’s next?
We have demonstrated the power of MoPro in training deep neural networks using noisy Web images. There is a vast potential in extending MoPro to other domains such as video, text, or speech. We hope MoPro can spur more research in webly-supervised learning, and push towards a future in AI where manual annotation is no longer an essential piece of model training.
If you are interested in learning more, please check out our paper and feel free to contact us at junnan.li@salesforce.com.
References
1. Junnan Li, Caiming Xiong, Steven C.H. Hoi. MoPro: Webly Supervised Learning with Momentum Prototypes. arXiv:2009.07995, 2020.
2. Junnan Li, Pan Zhou, Caiming Xiong, Richard Socher, Steven C.H. Hoi. Prototypical Contrastive Learning of Unsupervised Representations. arXiv:2005.04966, 2020.
3. Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, 2020.
4. Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In ICML, 2020.
5. Grill et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv:2006.07733, 2020.
6. Caron et al. Unsupervised learning of visual features by contrasting cluster assignments. arXiv:2006.09882, 2020.