 Blog Home
Blog HomeMoirai: A Time Series Foundation Model for Universal Forecasting
TL;DR: Moirai is a cutting-edge time series foundation model, offering universal forecasting capabilities. It stands out as a versatile time series forecasting model capable of addressing diverse forecasting tasks across multiple domains, frequencies, and variables in a zero-shot manner. To achieve this, Moirai tackles four major challenges: (i) construction of a LOTSA, a large-scale and diverse time series dataset, comprising 27 billion observations spanning nine distinct domains, (ii) development of multiple patch size projection layers, allowing a single model to capture temporal patterns across various frequencies, (iii) implementation of an any-variate attention mechanism, empowering a single model to handle forecasts across any variable, and (iv) integration of a mixture distribution to model flexible predictive distributions. Through comprehensive evaluation in both in-distribution and out-of-distribution settings, Moirai demonstrates its prowess as a zero-shot forecaster, consistently delivering competitive or superior performance compared to full-shot models.
The need for a universal forecaster
Time series data pervades numerous domains, including retail, finance, manufacturing, healthcare, and natural sciences. Across these sectors, time series forecasting is a critical application with significant implications for decision making. Although significant strides have been made in deep learning for time series forecasting, recent advancements still predominantly adhere to the conventional paradigm of training a model for a specific dataset with a fixed, pre-defined context and prediction length. Such a paradigm inevitably imposes a significant burden in terms of computational costs for training these models, especially when scaling to large numbers of users.
For example, a growing demand for cloud computing services has magnified the importance of efficiently managing resources in I.T. infrastructure. Operational forecasting has emerged as a critical component in the pipeline of managing these resources, as the main driving factor for capacity planning, budget planning, scenario risk assessment, cost optimization, and anomaly detection. However, with the ever-increasing demand for compute resources and the growing size of I.T. infrastructure, the ability of service providers to handle the forecasting needs across the multitude of tasks is continually challenged, on top of having to build task/user-specific forecasters.
This motivates us to move towards the universal forecasting paradigm (see Figure 1), where a single large pre-trained model is capable of handling any time series forecasting problem.
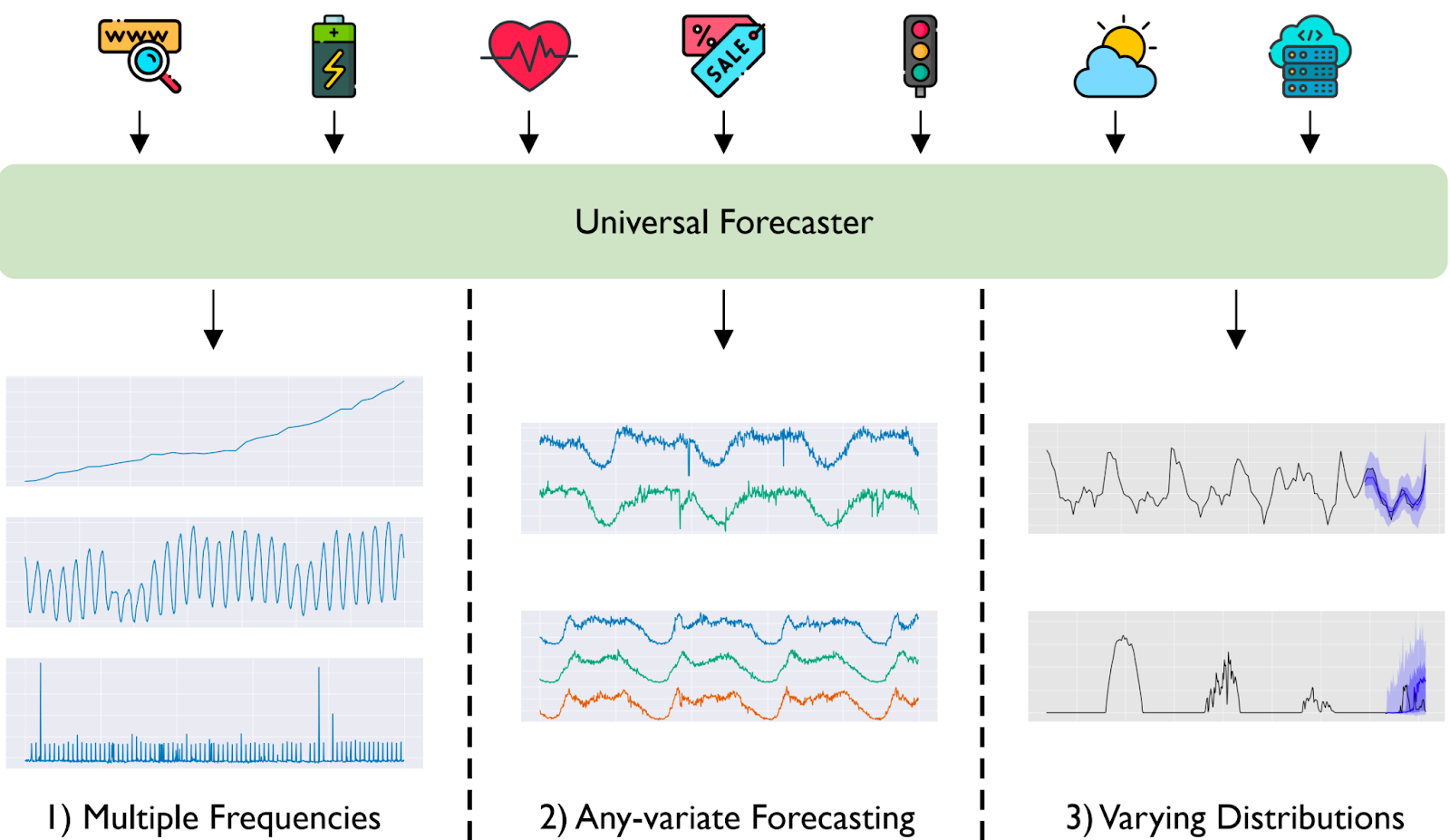
Figure 1. A universal forecaster is a large pre-trained model capable of handling any time series forecasting problem. It is trained on a large-scale time series dataset spanning multiple domains. Compared to the existing paradigm, universal forecasting faces the three key issues of i) multiple frequencies, ii) any-variate forecasting, and iii) varying distributions.
The challenges for building a universal forecaster
The paradigm shift towards foundation models was initially sparked by the field of Natural Language Processing (NLP) which successfully trained Large Language Models (LLMs) on diverse web-scale data, capable of tackling a wide variety of downstream tasks and are even multilingual. One major innovation that allows for LLMs to handle multiple languages is Byte Pair Encoding (BPE) – converting heterogeneous languages into a unified format. Unlike NLP, the field of time series does not have a BPE equivalent, making it non-trivial to build a time series foundation that can handle the heterogeneity of time series data.
- Firstly, the frequency (e.g., minutely, hourly, daily sampling rates) of time series plays a crucial role in determining the patterns present in the data. However, cross-frequency learning poses challenges due to negative interference, with existing approaches typically circumventing this issue for multi-frequency datasets by training one model per frequency.
- Secondly, time series data exhibit heterogeneity in terms of dimensionality, where multivariate time series may have varying numbers of variables. Moreover, each variable often measures a semantically distinct quantity across datasets. While treating each variable of a multivariate time series independently can mitigate this issue, a universal model should ideally be flexible enough to consider interactions between variables and account for exogenous covariates.
- Thirdly, probabilistic forecasting is a critical requirement for many applications. However, different datasets possess varying support and distributional properties. For instance, using a symmetric distribution (e.g., Normal, Student-T) as the predictive distribution may not be suitable for positive time series. Consequently, standard approaches that pre-define a simple parametric distribution may lack the flexibility needed to capture the diverse range of datasets effectively.
- Lastly, the development of a large pre-trained model capable of universal forecasting necessitates a comprehensive dataset spanning diverse domains. Unfortunately, existing time series datasets are often insufficiently large and diverse to support the training of such models.
Our New Approach: Unified Training of Universal Time Series Forecasting Transformers
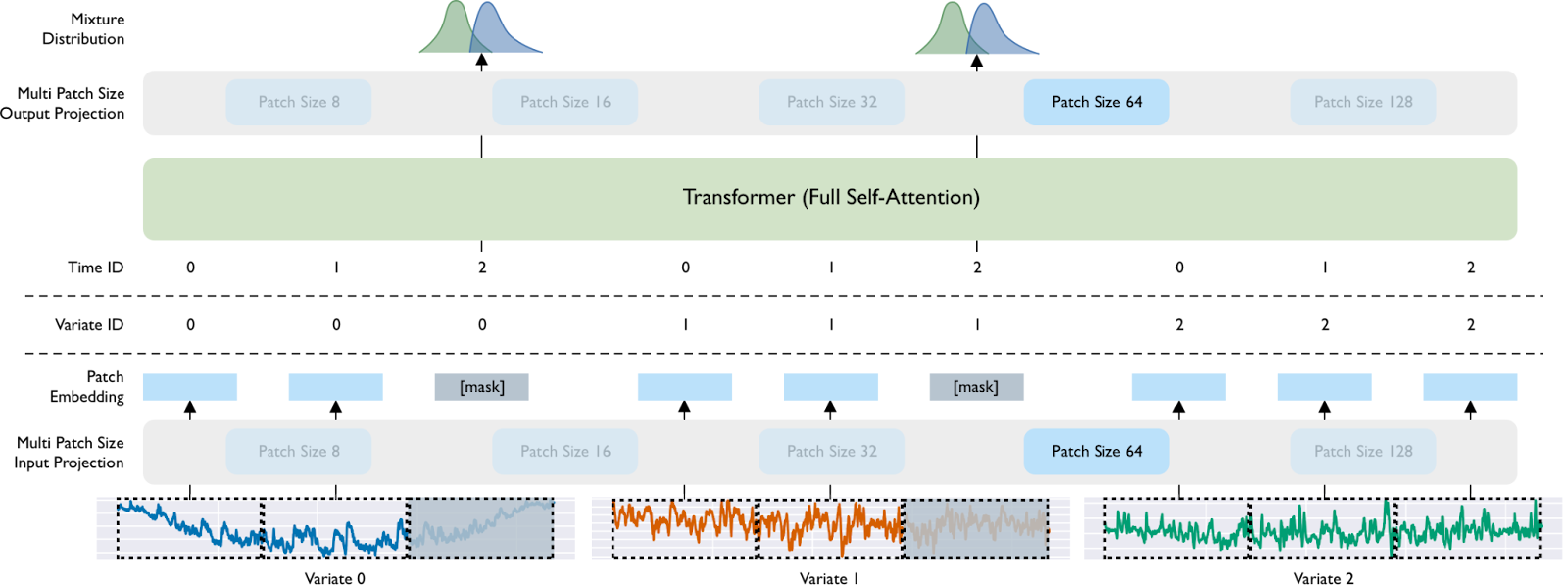
Figure 2. The overall architecture of Moirai. The visualization depicts a 3-variate time series, where variates 0 and 1 represent target variables (i.e., those to be forecasted), and variate 2 serves as a dynamic covariate (with known values in the forecast horizon). Utilizing a patch size of 64, each variate is patchified into three tokens. These patch embeddings, along with sequence and variate identifiers, are fed into the Transformer. The shaded patches in the visualization denote the forecast horizon to be predicted. The corresponding output representations of these patches are then mapped into the parameters of the mixture distribution.
To address these challenges, we present novel enhancements (see Figure 2) to the conventional time series Transformer architecture to handle the heterogeneity of arbitrary time series data. Here are some of the key features and contributions of our work:
- Firstly, we propose to address the challenge of varying frequencies in time series data by learning multiple input and output projection layers. These layers are designed to handle the diverse patterns present in time series of different frequencies. By employing patch-based projections with larger patch sizes for high-frequency data and vice versa, the projection layers are specialized to learn the patterns specific to each frequency.
- Secondly, we tackle the issue of varying dimensionality using our proposed Any-variate Attention mechanism. This approach simultaneously considers both the time and variate axes as a single sequence, leveraging Rotary Position Embeddings (RoPE) and learned binary attention biases to encode the time and variate axes, respectively. Importantly, Any-variate Attention enables the model to accept an arbitrary number of variates as input.
- Thirdly, we overcome the challenge of requiring flexible predictive distributions by introducing a mixture of parametric distributions. By optimizing the negative log-likelihood of a flexible distribution, we ensure that our model is competitive with target metric optimization, a powerful feature for pre-training universal forecasters. This approach allows for subsequent evaluation using any target metric.
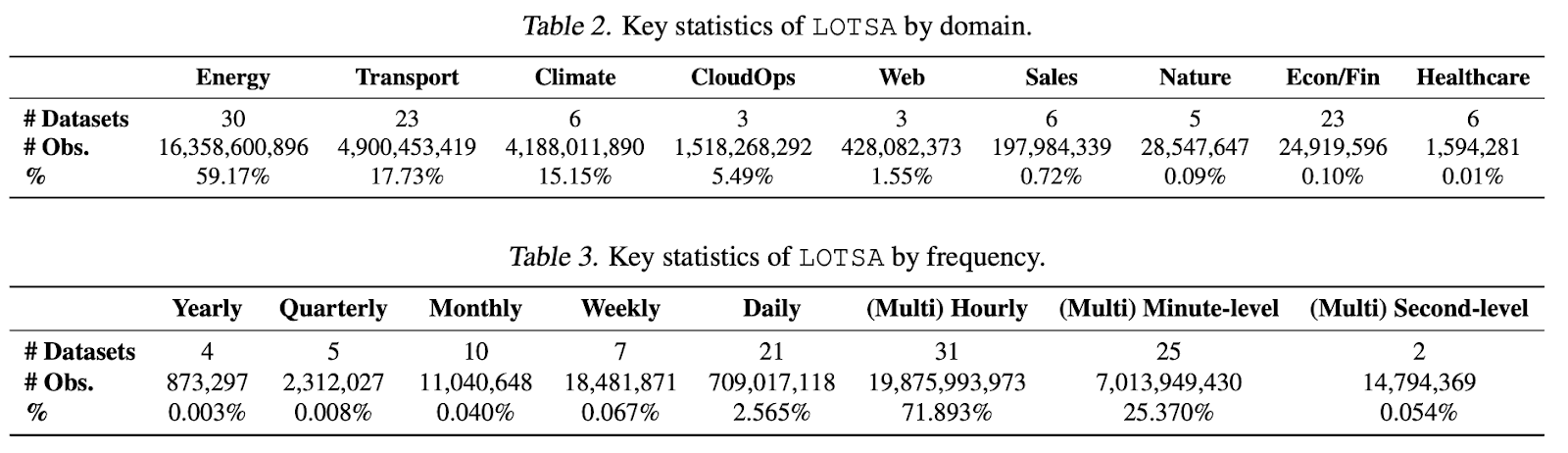
- Lastly, to facilitate the training of our large time series model, we introduce the LOTSA, the largest collection of open time series datasets by collating publicly available sources of time series datasets. This effort aims to cover a broad spectrum of domains, consolidating datasets from diverse sources with varying formats. The resulting collection spans nine domains, with a total of 27B observations, with key statistics in Tables 2 and 3. More details on the key properties of these datasets, like the domain, frequency, number of time series, number of target variates, number
of past covariates, and the total number of observations can be found in our research paper (https://arxiv.org/abs/2402.02592).
Deeper Dive: Moirai
Illustrated in Figure 2, Moirai follows a (non-overlapping) patch-based approach to modeling time series with a masked encoder architecture. One of our proposed modifications to extend the architecture to the any-variate setting is to "flatten" multivariate time series, considering all variates as a single sequence. Patches are subsequently projected into vector representations via a multi-patch size input projection layer. The [mask] signifies a learnable embedding that replaces patches falling within the forecast horizon. The output tokens are then decoded via the multi-patch size output projection into the parameters of the mixture distribution. While not visualized, (non-learnable) instance normalization is applied to inputs/outputs, aligning with the current standard practice for deep forecasting models.
In our pre-training task, we formulate the objective to optimize the mixture distribution log-likelihood. The design of both the data distribution and task distribution are two critical aspects of the pre-training pipeline. This design imparts versatile capabilities to our Large Time Series Model (LTM), enabling it to adapt to a range of downstream tasks. This flexibility stands in contrast to the prevailing deep forecasting paradigm, where models are typically specialized for specific datasets and settings.
Results
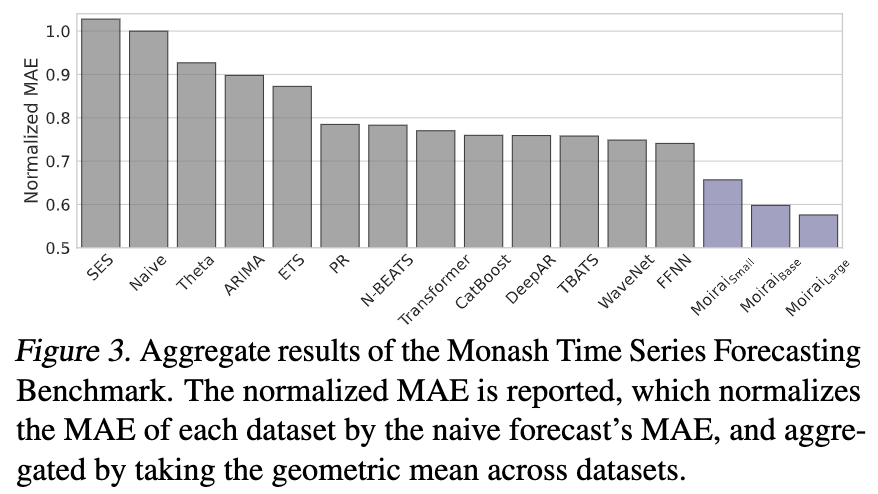
We train Moirai in 3 sizes – small/base/large with 14m/91m/311m parameters! On in-distribution evaluations using the Monash Time Series Forecasting Benchmark, Moirai displays phenomenal performance, beating all baselines.
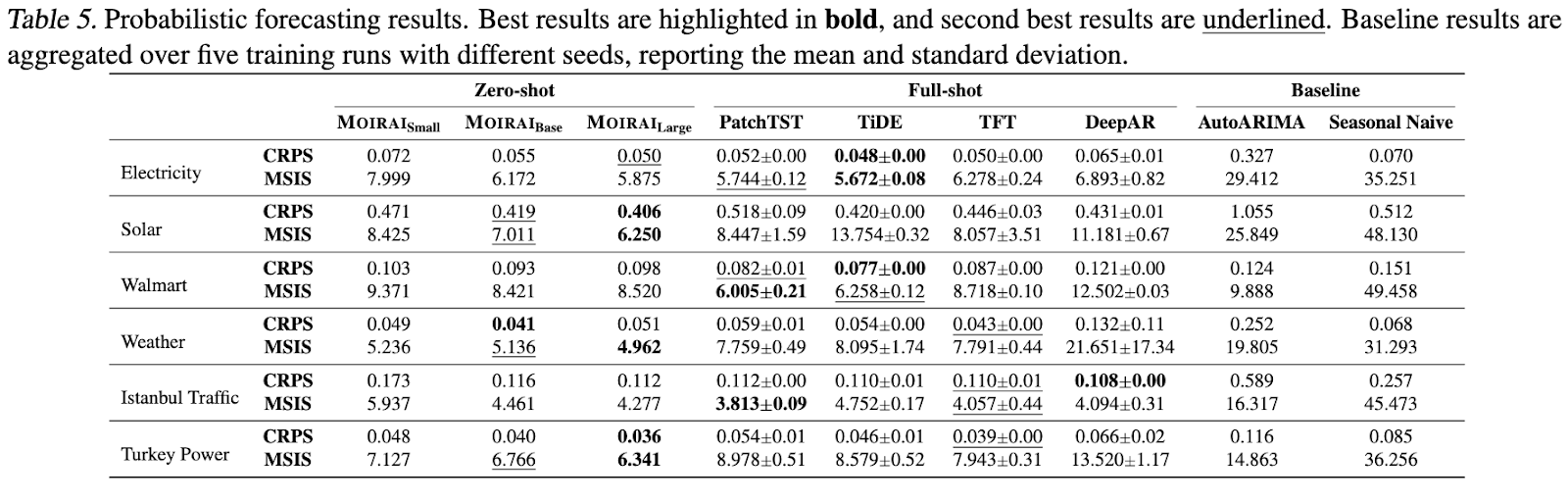
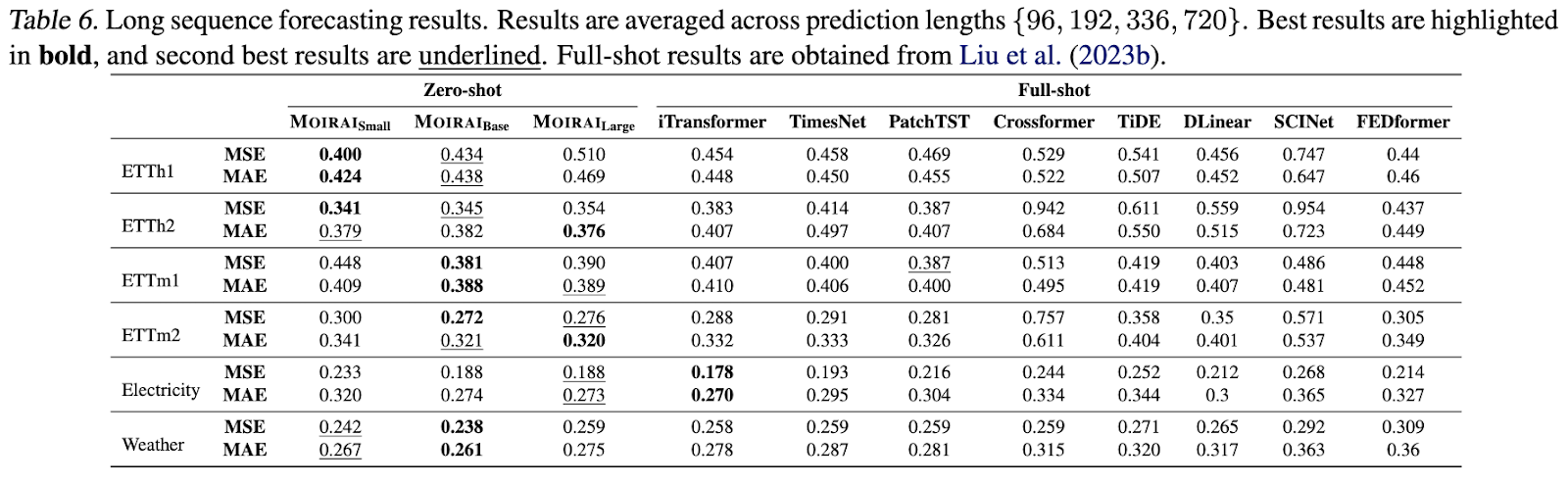
In out-of-distribution/zero-shot forecasting evaluations, Moirai consistently demonstrates competitive performance, and in some instances, surpasses state-of-the-art full-shot models. This superiority is observed across probabilistic forecasting and long-sequence forecasting benchmarks.
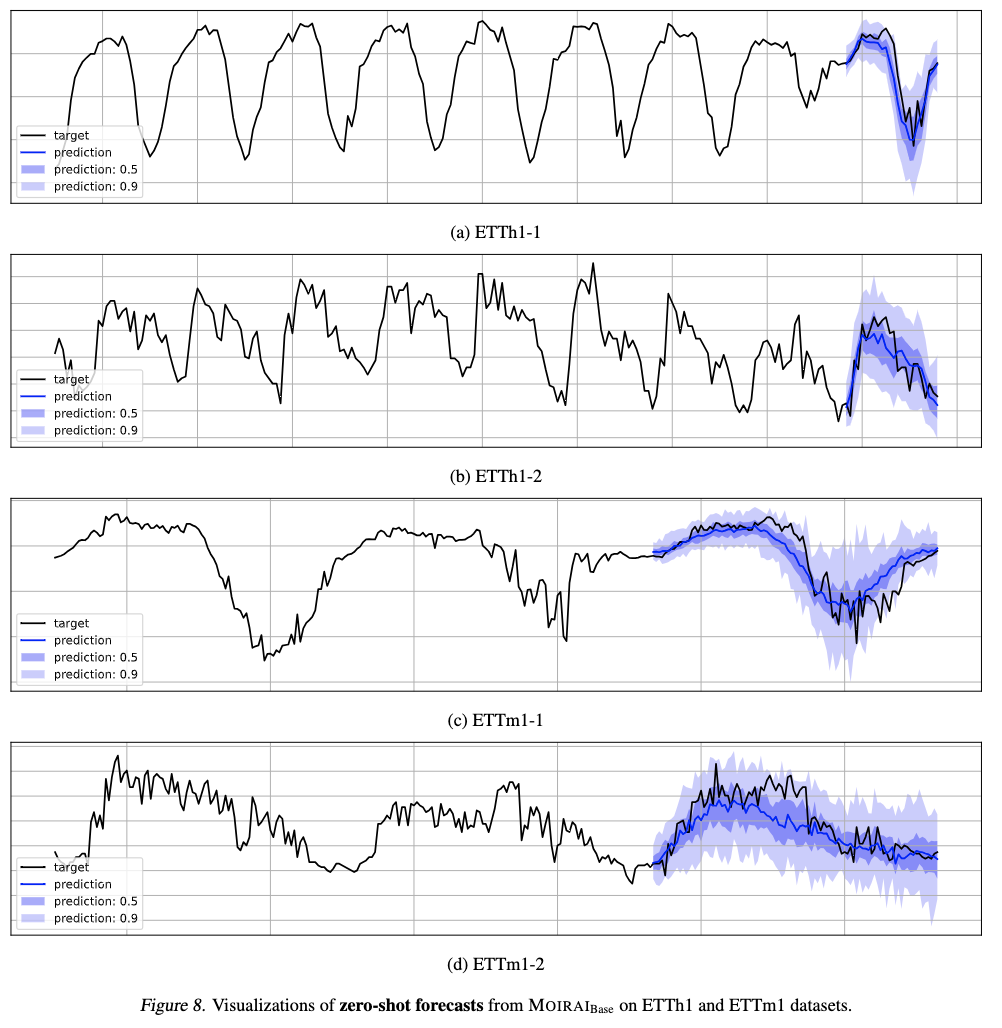
Here are some visualizations of zero-shot forecasts from Moirai on the popular datasets. As depicted, Moirai adeptly crafts forecasts marked by discernible seasonal patterns from ETTh1-1 and ETTh1-2, while also accurately capturing trend patterns from ETTm1-1 and ETTm1-2. These illustrations underscore Moirai's capability to deliver insightful predictions across varied scenarios.
Impact: Why Moirai Matters
Moirai provides robust zero-shot forecasting capabilities across a diverse range of time series spanning different domains and frequencies. By harnessing the power of large-scale data pretraining, this time-series foundation model revolutionizes the landscape, departing from the outdated one-model-per-dataset approach. It offers substantial advantages to users in downstream forecasting tasks, eliminating the need for additional data, extensive computational resources, and expert input typically required for achieving accurate forecasts with deep learning models. Additionally, Moirai's ability to handle multivariate time series of any dimension further democratizes accurate forecasting by reducing reliance on both computational resources and deep learning expertise. In addition to being an important breakthrough for academia, Moirai has multiple applications including IT Operations, Sales Forecasting, Capacity Planning, Energy Forecasting and many others.
The Bottom Line
- Moirai is designed to achieve universal forecasting with masked encoder-based time series transformers.
- LOTSA is the largest collection of open data for pre-training time series forecasting models.
- Moirai addresses key challenges of universal forecasting to support various domains, multiple frequencies, and any-variate in a zero-shot manner.
- Evaluated in both in-distribution and out-of-distribution settings, Moirai shines as a zero-shot forecaster, delivering competitive or even superior performance compared to full-shot models.
Explore More
Salesforce AI invites you to dive deeper into the concepts discussed in this blog post (see links below). Connect with us on social media and our website to get regular updates on this and other research projects.
- Learn more: Check out our research paper (https://arxiv.org/abs/2402.02592), which describes our work in greater detail.
- Code: Check out our code on GitHub: https://github.com/SalesforceAIResearch/uni2ts
- Dataset: Check out LOTSA data on Hugging Face: https://huggingface.co/datasets/Salesforce/lotsa_data
- Contact us: gwoo@salesforce.com chenghao.liu@salesforce.com
- Follow us on Twitter: @SalesforceResearch, @Salesforce
- Blog: To read other blog posts, please see blog.salesforceairesearch.com
- Main site: To learn more about all of the exciting projects at Salesforce AI Research, please visit our main website at salesforceairesearch.com.
About the Authors
Gerald Woo is a Ph.D. candidate in the Industrial PhD Program at Singapore Management University and a researcher at Salesforce AI Research Asia and his research focuses on deep learning for time-series, including representation learning, and forecasting.
Chenghao Liu is a Lead Applied Scientist at Salesforce AI Research Asia, working on AIOps research, including time series forecasting, anomaly detection, and causal machine learning.
Doyen Sahoo is the Director, of Salesforce AI Research Asia. Doyen leads several projects pertaining to AI for IT Operations or AIOps, AI for Software, and Time-Series intelligence - working on both fundamental and applied research.
Caiming Xiong holds the positions of Managing Director and Vice President at Salesforce AI Research. He oversees the development and application of technologies such as Large Language Models (LLM), Multimodal LLMs, Large Action Models, AI for software, Time Series, and other foundational research areas. Additionally, Caiming directs the transition of these AI projects from research phases into production environments.