 Blog Home
Blog HomeMask-free OVIS: An Open-Vocabulary Instance Segmentation Mask Generator
Authors: Vibashan Vishnukumar Sharmini, Ning Yu, Ran Xu
Have you ever wondered how long it takes for a human annotator to annotate a dataset like COCO? MORE THAN A YEAR. Not to mention, even training a detection model on this dataset would only equip it to detect those specific 80 categories, leaving us reliant on human annotators once again for new/novel categories. Motivated by this, we develop a method that automates the generation of bounding-box and instance-mask annotations given an image and corresponding caption, eliminating the need for time-consuming human labeling. Our research, accepted by CVPR 2023, presents experimental results surpassing state-of-the-art open vocabulary instance segmentation models using these generated pseudo annotations. The big picture? Our vision-language guided pseudo annotation generation pipeline opens up new horizons for the development of instance segmentation models free from human annotators.
Background
Instance segmentation, a crucial task in computer vision, has witnessed significant progress in recent years due to advancements in deep learning. Recent AI advancements have led to remarkable breakthroughs in developing instance segmentation methods that achieve exceptional performance by learning from datasets like COCO and OpenImages. These methods enable real-world systems to not only detect objects but also accurately segment each instance, facilitating a more comprehensive understanding of the visual world. Nevertheless, existing methods are limited to the classes they have been trained on, posing a challenge when it comes to detecting novel categories without further human intervention. Therefore, the key question lies in efficiently enhancing these models to detect new categories with minimal human involvement, thus expanding their applicability in real-world scenarios.
Our Idea
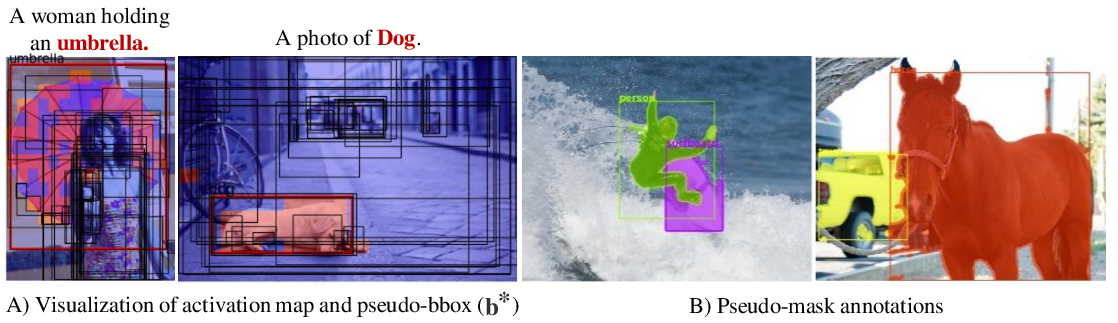
Given an image and caption pair, we generate pseudo mask annotation for the object of interest, such as an "Umbrella", using our proposed pipeline.

- Step I: Utilize a pre-trained Vision-Language model to identify and localize the object of interest using GradCAM.
- Step II: Employ a weakly-supervised proposal generator to generate bounding box proposals and select the proposal with the highest overlap with the GradCAM map.
- Step III: Crop the image based on the selected proposal and leverage the GradCAM map as a weak prompt to extract a mask using a weakly-supervised segmentation network.
- Step IV: Using these generated masks, train an instance segmentation model (Mask-RCNN) eliminating the need for human-provided box-level or pixel-level annotations.
Pseudo-mask Generation Pipeline
The pseudo-mask generation pipeline is designed in a way to automatically generate annotations for instance segmentation without relying on human annotators. Overall, our pipeline leverages the power of pre-trained vision-language models and weakly supervised models to automatically generate pseudo-mask annotations. These annotations serve as the training data for an instance segmentation model, eliminating the need for human annotators to manually annotate boxes or pixels for new objects, making the entire pipeline more efficient and scalable.
Vision-Language Model Robust Localization

In our study, we found that the pre-trained vision-language models are reliable and consistent when generating pseudo-masks for instance segmentation. It doesn't matter if we use real captions or pseudo-captions based on image labels; the model produces similar activation maps for the objects of interest, such as "zebra" and "giraffe." This means that the model is robust and dependable, ensuring that the generated pseudo-masks are accurate and consistent regardless of the type of captions used. In simpler terms, our findings show that the model consistently generates reliable masks for object segmentation, regardless of the caption type used. (You can try this out at https://replicate.com/salesforce/albef)
Results

The top and bottom rows of the visualization display the predictions generated by the Mask-RCNN model, which was trained on pseudo-masks created from two datasets: COCO and Open Images, respectively. By training on a large number of pseudo-masks, the Mask-RCNN model is learned to filter out any noise present in the masks, leading to improved predictions that include complete masks and tight bounding boxes.

Our method, utilizing pseudo-labels, achieves state-of-the-art performance in both detection and instance segmentation tasks on popular datasets like MS-COCO and OpenImages. When compared to recent methods that rely on manual masks, our approach outperforms them relying just on pseudo-masks generated by our method. This highlights the effectiveness of our method in pushing the boundaries of performance and accuracy in object detection and instance segmentation.
Bottom Line
Our automatic pseudo-annotation pipeline, known as Mask-free OVIS, has removed the need for human annotators in instance segmentation by simply leveraging pre-trained vision-language models and weakly supervised models. This efficient approach streamlines the process, making it scalable and more practical for real-world scenarios.
Explore More
arXiv: https://arxiv.org/pdf/2303.16891.pdf
Website: https://vibashan.github.io/mask-free-ovis-web/
Code: https://github.com/Vibashan/Mask-free-OVIS
Contact: vibashanvs@gmail.com; ning.yu@salesforce.com
Follow us on Twitter: @SFResearch @Salesforce