 Blog Home
Blog HomeCreating the World’s First LLM Benchmark for CRM
Highlights
- We have developed the world's first LLM benchmark for CRM to assess the efficacy of generative AI models for business applications.
- We evaluate LLMs for sales and service use cases across accuracy, cost, speed, and trust & safety based on real CRM data.
- What sets our benchmark apart is its extensive human evaluations for a comprehensive list of LLMs (15 in total and growing) by both Salesforce employees and external customers on their respective use cases.
- For scaling and cost-effectiveness of the evaluation process, we also develop automatic evaluation methods based on LLM judges and perform meta-evaluation of the judges.
- The benchmark is available as an interactive Tableau dashboard (link) and as a leaderboard in Hugging Face (link).
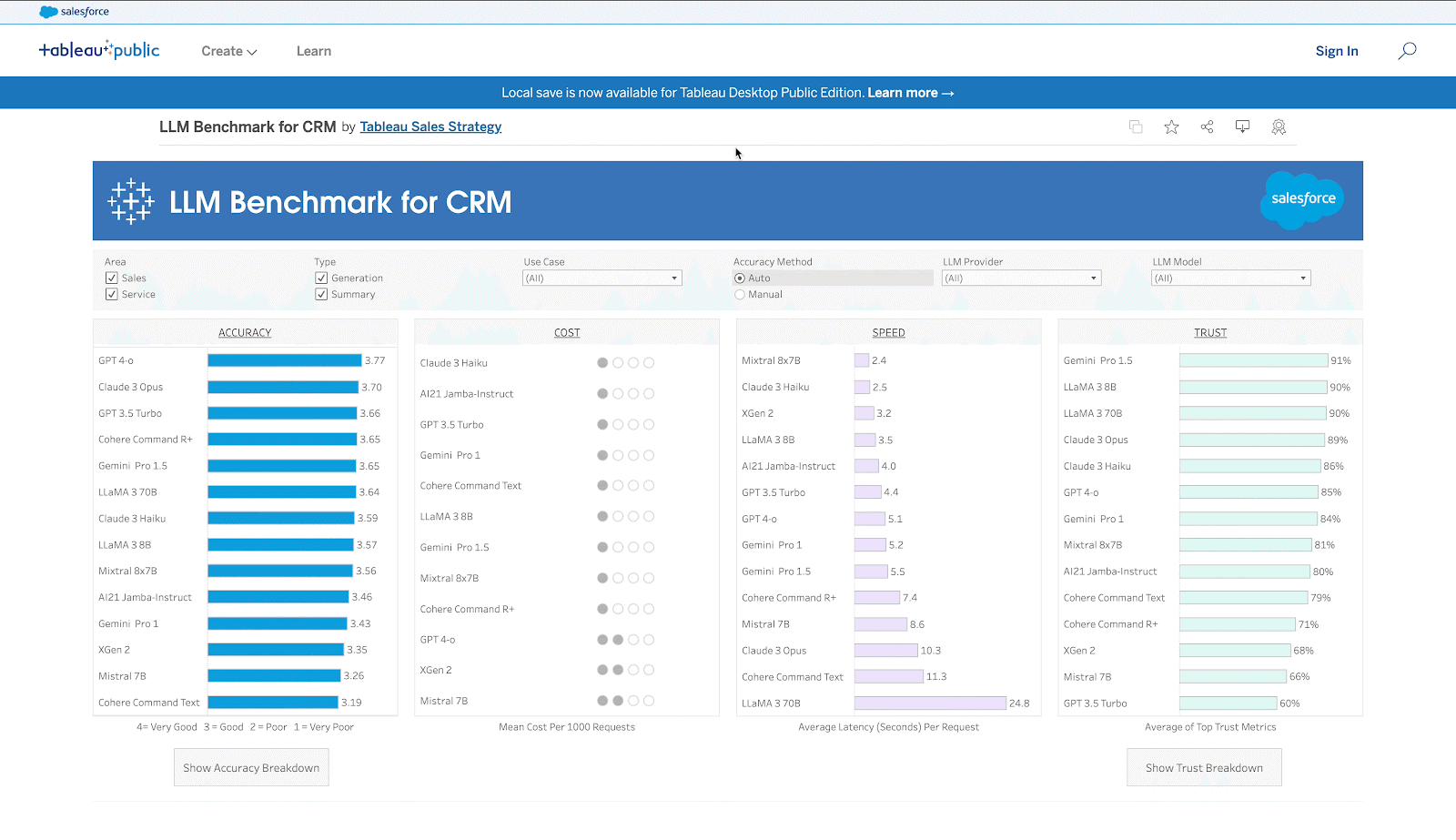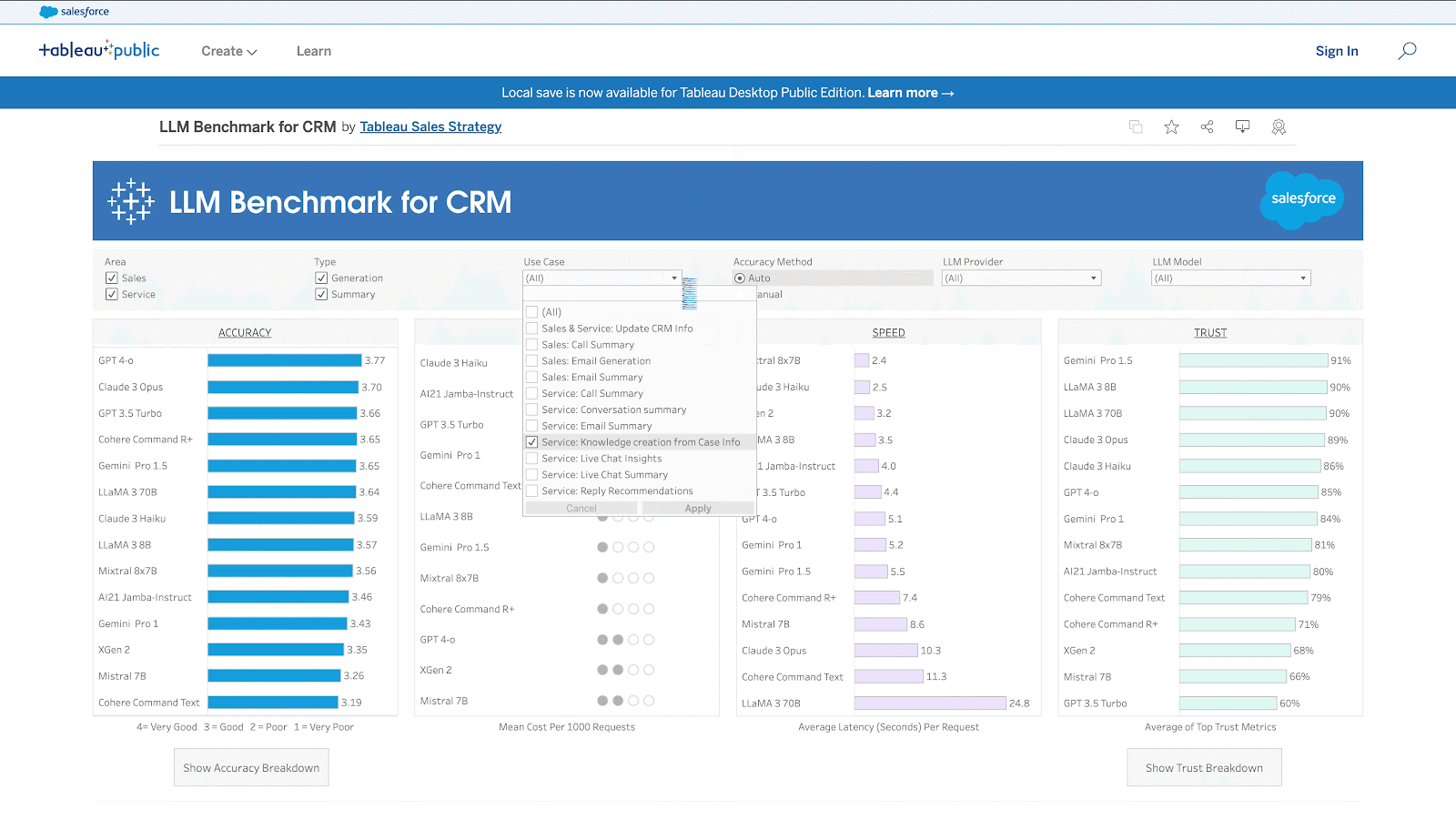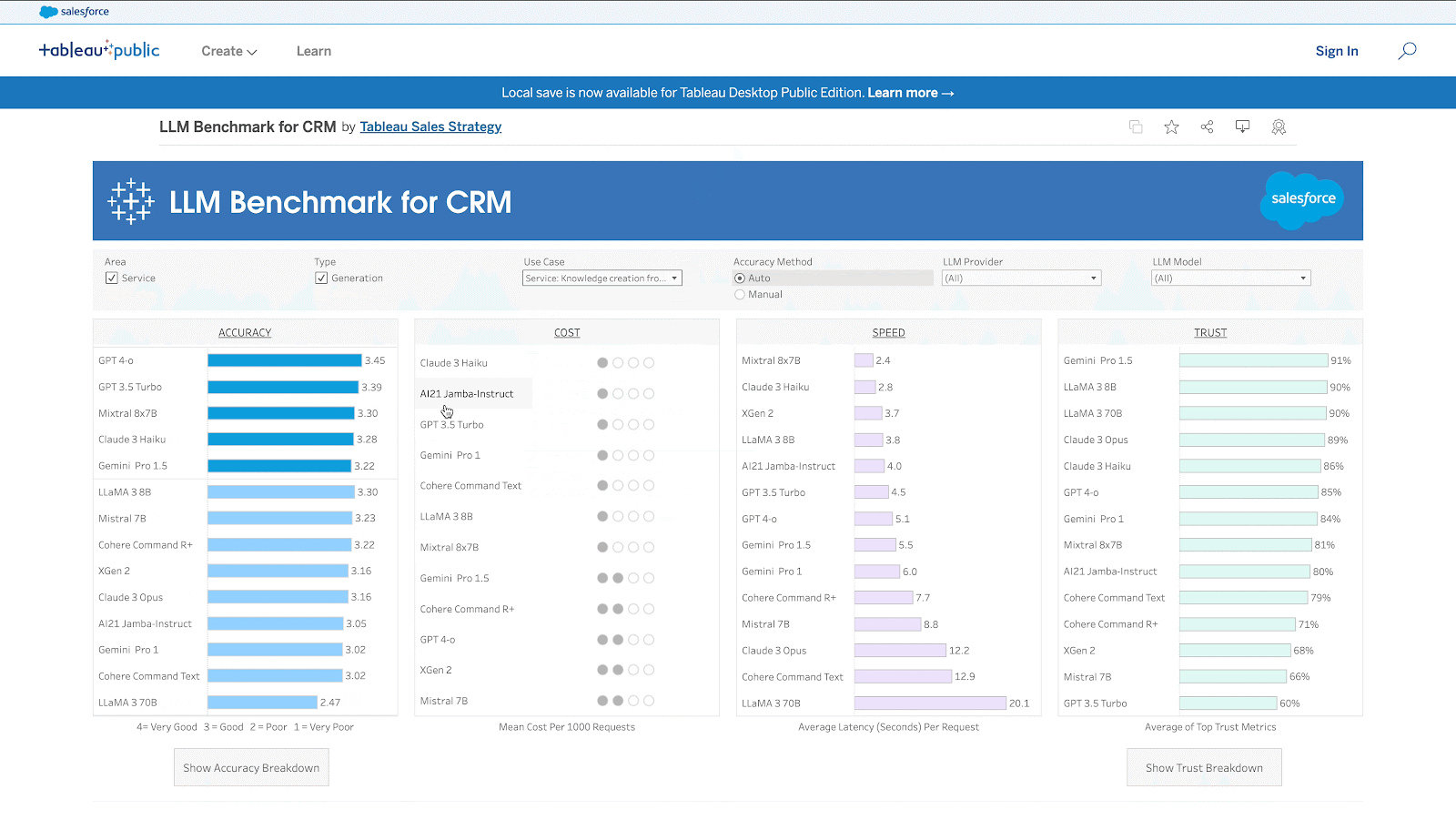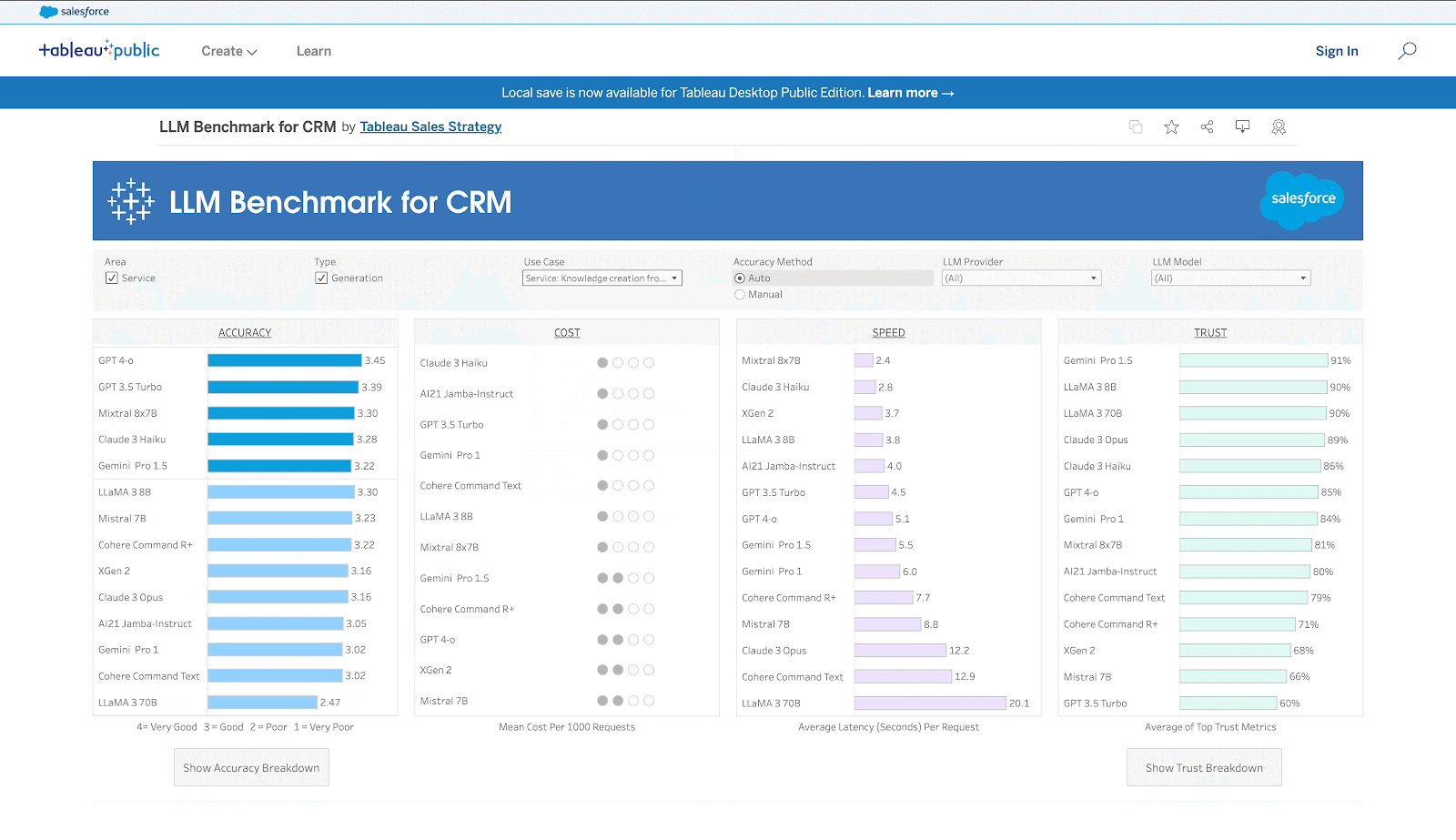
Why We Need a CRM Benchmark
Most existing benchmarks for Gen AI are academic and do not use data from relevant use cases, let alone real-world business data. Hence they are not very useful for businesses trying to understand what Gen AI can do for them. Even when there are seemingly relevant results, those could be unreliable, as the evaluation is often done by LLMs and not by real people. What’s more, these benchmarks do not provide important business metrics like costs, speed, and trust and safety, in one view. How can a business understand ROI without understanding costs, for instance?
This gap drove us to develop the world’s first comprehensive LLM Benchmark for CRM comprising real data and real business use cases. It includes costs, not just accuracy. Crucially, we incorporated speed, since some use cases need to be real-time, and trust & safety, which is an important factor many companies consider when it comes to Gen AI. We also took the time to manually evaluate LLMs with real professionals, who have sales and service roles. The rigorous manual evaluation also helped improve our automated evaluation method.
Our Benchmarking Framework
The figure below depicts our benchmarking framework. We identified 11 common CRM use cases across sales and service and collected relevant examples. For each use case, we constructed a standard prompt template, which was grounded using each of the examples for the use case. Each grounded prompt was given to 15 different LLMs, producing an output that was evaluated by human evaluators, as well as by an automated LLM judge.
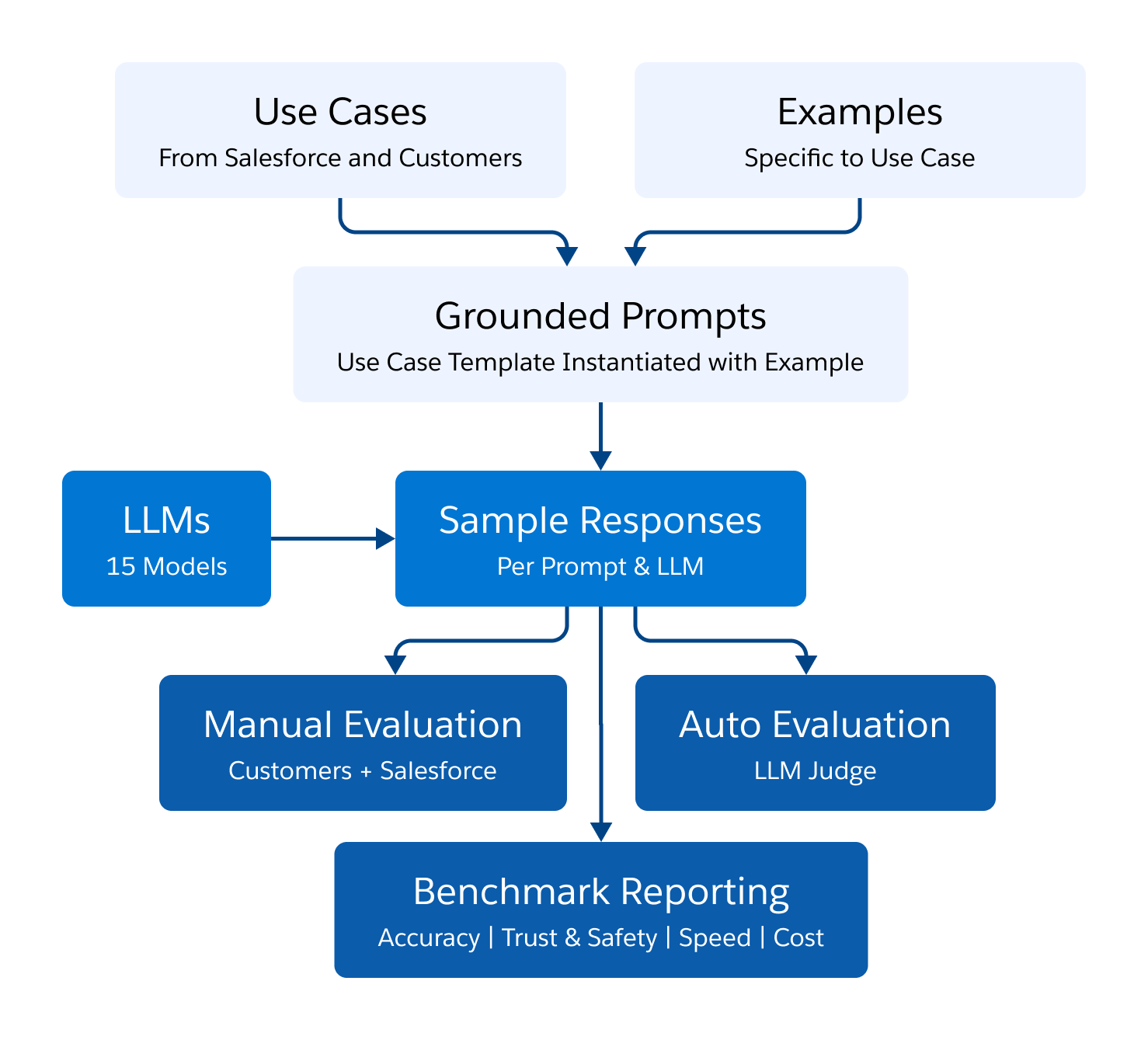
CRM Use Cases
The table below lists the 11 use cases and their corresponding cost and speed flavor.
The LLMs
We evaluate a total of 15 LLMs on the CRM use cases. The table below lists the LLMs and the maximum context length supported by them.
Evaluation Dimensions
Accuracy Measures
We measured the accuracy of the outputs from LLMs along 4 dimensions:
- Factuality - Is the response true and free of false information?
- Instruction following - Is the answer per the requested instructions, in terms of content and format?
- Conciseness - Is the response to the point and without repetition or unnecessary elaboration?
- Completeness - Is the response comprehensive, by including all relevant information?
We adopted a 4-point scoring rubric when measuring:
- 4 - Very Good: As good as it gets given the information. A human with enough time would not do much better.
- 3 - Good: Done well with a little bit of room for improvement.
- 2 - Poor: Not usable and has issues.
- 1 - Very Poor: Not usable with obvious critical issues.
To obtain the accuracy scores, we conducted both human- and auto-evaluation with an LLM judge which is described below.
Trust and Safety Measures
For this first version of the CRM benchmark, we included several Trust & Safety measures. While these measures are not comprehensive, they provide a look into several Trust & Safety aspects that Salesforce customers especially care about. Our approach is two-prong, first, evaluating Safety, Privacy, and Truthfulness using three public datasets, and second, performing Fairness perturbations on CRM data.
The public datasets we used were Do Not Answer (for the Safety metric), Privacy Leakage (for the Privacy metric), and Adversarial Factuality (for the Truthfulness metric). Safety was assessed by calculating 100 minus the percentage of times a model refused to respond to an unsafe prompt. Privacy was measured as the average percentage of times privacy was maintained (e.g., avoid revealing an email address) across 0-shot and 5-shot attempts. Truthfulness was determined by the percentage of times the model correctly addressed incorrect general information or facts presented in a prompt.
In order to measure CRM Fairness, we created perturbed versions of the CRM datasets described above by perturbing: (1) person names and pronouns or (2) company/account names. We then defined gender bias and company/account bias respectively as the change in model performance (using the above-mentioned accuracy measures) after perturbations (1) and (2) respectively. The final CRM Fairness score is the average of gender bias and account bias.
In addition, we created 5 perturbed versions for each bias type and used bootstrapping to measure the distribution of model performance change due to randomness in data perturbation. We computed the 95% confidence interval for the CRM Fairness measure of each model and verified that any ranking greater than 1 is generally statistically significant.
The final aggregated Trust & Safety measure is the average of Safety, Privacy, Truthfulness, and CRM Fairness, as a percentage. For upcoming versions of this CRM benchmark, we will add more measures to make the aggregated Trust & Safety measure even more comprehensive.
Cost and Latency Measures
We separately constructed two prompt datasets to evaluate cost and latency. The lengths of prompts in these datasets were approximately 500 tokens and 3000 tokens, reflecting typical prompt lengths for the use cases of generation and summarization, respectively. The prompts were designed to elicit an output of at least 250 tokens, e.g. by prompting the model to copy the input. Additionally, a max output token length of 250 was set to ensure a final output length of 250 tokens, reflecting a typical length of outputs across summarization and generation tasks.
Latency measures were computed based on the mean time to generate the full completion across the above dataset(s). For externally hosted APIs – hosted directly by the LLM provider or through AWS Bedrock – costs were computed based on standard per-token pricing. Latency and costs for the in-house xGen-22B model were based on estimates using proxy Bedrock models of size 12B and 52B.
Human Evaluation
How did we conduct our evaluation with real people? We knew we needed to do both human (i.e., manual) and automatic evaluations for the accuracy of LLMs for CRM use cases. Without this, we would not be sure that our auto-evaluation results are correct and usable. Hence we worked with Salesforce and customer employees who perform sales and service functions. To design this manual evaluation, we used the same four accuracy metrics on the same 4-point scale as the automated evaluation to allow us to better compare manual versus automated evaluations. Furthermore, this allows us to understand which LLM judge models (for auto evals) are more in line with manual results, which in turn improves our auto eval.
Our four-point scale is intended to ensure that evaluators have to “pick a side” (as an even number), and avoid being overwhelmed with a larger scale to ensure more accurate responses even at scale. We also included the option for evaluators to add a note to explain their scoring and report observations. To further avoid any systematic bias, we kept the model name anonymous and we randomized the order of the LLM’s response to evaluate.
Human agreement: To verify the reliability of human evaluation, we measure the pairwise inter-human agreement. Two annotators are considered to agree with each other when they both vote for “Good” (a score of 3/4) or “Bad” (a score of 1/2) for an LLM output along a specific accuracy dimension (e.g., factuality, conciseness). On the three chosen use cases (Service: Reply Recommendations, Sales: Email Generation, and Service: Call Summary), we find substantial inter-human agreement (78.61% on average). See below for the breakdown of agreement across datasets.
Automatic Evaluation with LLMs
We also conducted auto-evaluation by using an LLM as a judge model. Automatic evaluation with LLMs provides a more scalable, efficient, and cost-effective evaluation process with a shorter turnaround time compared to manual human evaluation. Specifically, we used LLaMA3-70B as the LLM-Judge. For each accuracy dimension, we provided the LLM-Judge with the evaluation guidance and the input and output from the target LLM to be evaluated in the prompt. The evaluation guidance consists of the description of a particular dimension (factuality, conciseness, etc.) and the 4-point scoring rubric. The evaluation guidance explicitly asks the LLM-Judge to first provide some reasoning as a chain of thought and then give the score in an additive manner (i.e., incrementally granting additional points if the output is better at meeting the criteria along a particular dimension). We then take the average of the scores predicted by the LLM-Judge across the data points to be the final dimension-specific score.
Meta Evaluation of LLM-Judge: Although effective, recent studies have also identified several limitations of LLM-based automatic evaluation including positional biases (not applicable in our case), low self-consistency rates in their predictions, and a preference for their own outputs. To verify the reliability of our LLM-Judge, we conducted a meta-evaluation by measuring the agreement rate between human annotation and auto-evaluation. We view it as an agreement when both a human annotator and the LLM-Judge vote for “Good” (a score of 3/4) or “Bad” (a score of 1/2) for an LLM output along a specific dimension. On the three chosen use cases (Service: Reply Recommendations, Sales: Email Generation, and Service: Call Summary), our LLM-Judge with LLaMA3-70B achieves the highest agreement rate among other strong LLMs (see the comparison below).
Conclusion and Future Directions
Our CRM benchmarking framework is aimed to be a comprehensive dynamically evolving framework that empowers organizations to identify the best solution for their specific needs, and make informed decisions, balancing accuracy, cost, speed, and trust & safety. With Salesforce’s Einstein 1 Platform, customers can choose from existing LLMs or bring their own models to meet their unique business needs. By selecting models for their CRM use cases using the benchmark, businesses can deploy more effective and efficient generative AI solutions.
We aim to extend our framework in a number of ways:
- Include use cases for on-device small LLMs.
- Include use cases for LLM-based agents, i.e., evaluate LLMs on function calling, formatting, and task completion capabilities.
- Include use cases that involve both structured (e.g., tabular data, knowledge graphs) and unstructured data.
- Include meta-evaluation (LLM Judge) tasks.
Author list: Peifeng Wang,Hailin Chen,Lifu Tu, Jesse Vig, Sarah Tan, Bert Legrand and Shafiq Rayhan Joty.
Core team members: Peifeng Wang, Hailin Chen, Lifu Tu, Shiva Kumar Pentyala, Xiang-Bo Mao, Jesse Vig, Sarah Tan, Bert Legrand and Shafiq Rayhan Joty.
Acknowledgments: Special thanks to our collaborators from the AI platform team, Sitaram Asur and Deepak Mukunthu, for providing us with their datasets, and Jimmy Bowen from the Tableau team for work on the Tableau dashboard; to our stakeholders for providing us with their datasets and conducting the manual evaluation; to Yilun Zhou and Jason Wu for initiating work on Trust & Safety measures on public datasets, and finally, to our leadership, Silvio Savarese, Clara Shih, and Caiming Xiong, for their continuous support throughout the project.