 Blog Home
Blog HomeIntroducing LlamaRank: A state-of-the-art reranker for trusted AI
As part of our commitment to innovation in enterprise RAG and trusted AI, we're excited to release SFR LlamaRank, a state-of-the-art reranker from Salesforce AI Research. LlamaRank is a language model specialized for document relevancy ranking. LlamaRank achieves performance at least comparable to leading APIs across general document ranking while demonstrating a marked improvement in code search. LlamaRank’s performance was largely due to multiple rounds of iterative on-policy feedback provided by the Salesforce RLHF data annotation team.
Try it right now at Together.ai!

What is a Reranker?
In the context of Retrieval-Augmented Generation (RAG) systems, a reranker plays a crucial role in improving the quality and relevance of information retrieved from large document repositories. Here's how it fits into the RAG pipeline:
- Initial Retrieval: When a user poses a query, the system first uses fast, but sometimes less precise, methods like semantic search with embeddings to retrieve a set of potentially relevant documents or passages.
- Reranking: This is where the reranker comes in. It takes the initially retrieved set of documents and performs a more sophisticated analysis to determine which are truly most relevant to the query. The reranker considers various factors and nuances that the initial retrieval might have missed.
- Final Selection: The top-ranked documents from the reranking step are then used as context for the language model to generate a response.
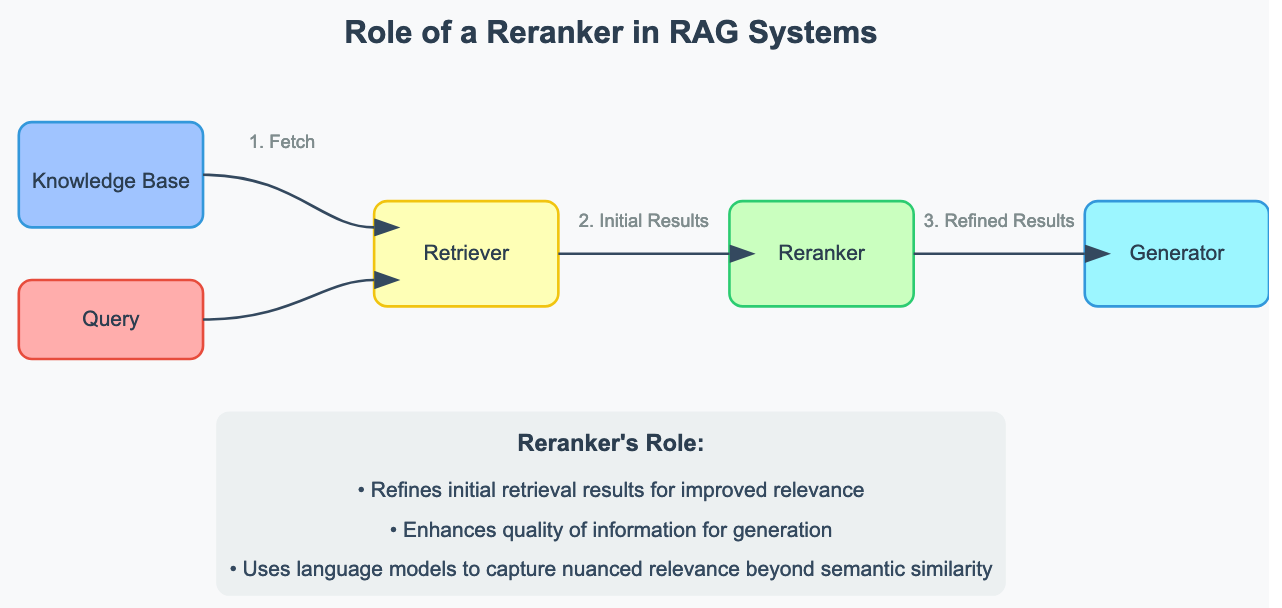
The reranker is essential because it significantly improves the quality of information fed into the language model while optimzing the relevancy of documents passed into the context of generative response models. This leads to more accurate, relevant, and coherent responses in enterprise applications such as customer support systems, internal knowledge bases, or code search tools. By ensuring that only the most pertinent information is used, rerankers help reduce hallucinations and improve the overall reliability of RAG systems.
Essentially, rerankers bridge the gap between search (fast, inexpensive, noisy) and large language models (slower, costly, intelligent) for RAG systems.
Technical Details
LlamaRank is a fine-tune of Llama3-8B-Instruct. The training data includes data synthesized from Llama3-70B and Llama3-405B and human-labeled data from our in-house data annotation team. The data includes topic-based search, document and news QA, code QA, and other types of enterprise-relevant retrieval data. The model underwent multiple iterations of on-policy feedback from our data annotation team. These annotators, highly skilled in relevancy scoring for document-query pairs, identified and corrected errors made by earlier versions of the model. This iterative process significantly enhanced the LlamaRank’s performance. At inference time, LlamaRank uses a fixed prompting template for (document, query) pairs. A numeric relevance score is computed based on the predicted token probabilities from the model. Inference is fast because only a single token needs to be predicted for each document.
Performance Evaluation
We evaluated LlamaRank on four public datasets:
- SQuAD: A well-established question-answering dataset based on Wikipedia
- TriviaQA: A question-answering dataset focusing on trivia-style questions from general web data
- Neural Code Search (NCS): A code search dataset curated by Facebook
- TrailheadQA: A collection of publicly available Trailhead documents and questions from corresponding quizzes
For rerankers, the choices of N (number of documents input into the reranker) and K (number of documents returned by the reranker) are pivotal in the precision-recall trade-off of the retrieval system and overall performance of the RAG system.
For simplicity, for all datasets, we hold K (the number of documents returned by the reranker into the response LM's context) fixed at 8. We found this to be a good trade-off point. At K=8, we observed reasonably high document recall. Increasing K further would lead to increased costs and, in some cases, can actually increase the error rate of the response model due to the inclusion of spurious context acting as a distraction.
The number of documents input into the reranker (N) was set to 64 for all the general document datasets and 256 for the code dataset. In production, we've observed that an optimal choice for N could be anywhere from 32 to 1024 depending on the dataset characteristics. If N is too low, the best-case recall for the retrieval system will be poor. Increasing N generally does not hurt recall, but, of course, does incur additional inference cost or latency in the system.
We used OpenAI's text-embedding-3-large embeddings for semantic search in all benchmarks. As a baseline, we included the query likelihood method (QLM) proposed in [Zhuang et al.].
Results: Hit Rate @ K = 8
| Model | Avg | SQuAD | TriviaQA | NCS | TrailheadQA |
| SFR LlamaRank | 92.9% | 99.3% | 92.0% | 81.8% | 98.6% |
| Cohere Rerank V3 | 91.2% | 98.6% | 92.6% | 74.9% | 98.6% |
| Mistral-7B QLM | 83.3% | 87.3% | 88.0% | 60.1% | 97.7% |
| Embeddings Only | 73.2% | 93.2% | 88.3% | 18.2% | 93.2% |
Key Advantages of LlamaRank
- Horizontal Scalability / Low Latency: LlamaRank can rank 4 docs on a single H100 in <200ms with vLLM. With two serving nodes, we can rank all N=64 docs in <200ms, compared to ~3.13 seconds with Cohere's serverless API.
- Superior Performance in Code Domain: LlamaRank shows marked improvement for code search compared to other rerankers.
- Larger Document Size: LlamaRank supports an 8k max document/chunk size, compared to 4k for Cohere.
- Linear Scoring Calibration: Unlike Cohere, LlamaRank produces linear & calibrated scores across all (doc, query) pairs, making it easier to interpret relevancy scores:
- > 0.9 — Highly Relevant
- 0.8 ~ 0.7 — Relevant
- 0.6 ~ 0.5 — Somewhat Relevant
- 0.4 ~ 0.3 — Marginally Relevant
- 0.2 ~ 0.1 — Slightly Relevant
- ~ 0.0 — Irrelevant
Considerations
While LlamaRank offers numerous advantages, there are some considerations to keep in mind, especially around model size. As an 8B parameter reranker, it’s on the upper limit in terms of size. For a reranking model, perhaps something in the 1~4B parameter range would be ideal. Future work can focus on how to shrink this model without sacrificing quality.
Conclusion
LlamaRank is a significant step forward in reranking technology. It is a versatile and powerful tool for a wide range of document ranking tasks and RAG use cases. We're excited to see how the community will leverage and build upon LlamaRank's capabilities in the future.
Stay tuned for more updates and improvements!
Technical Contributors: Antonio A. Ginart, Naveen Kodali, Jesse Vig, Shafiq Joty, Caiming Xiong, Silvio Savarese, John R. Emmons
And a special thank you to Donna Tran and our entire RLHF Data Annotation Team!