 Blog Home
Blog HomeLeveraging Language Models for Commonsense Reasoning in Neural Networks

Commonsense reasoning that draws upon world knowledge derived from spatial and temporal relations, laws of physics, causes and effects, and social conventions is a feature of human intelligence. However, it is difficult to instill such commonsense reasoning abilities into artificial intelligence implemented by deep neural networks. While neural networks effectively learn from a large number of examples, commonsense reasoning for humans precisely hits upon the kind of reasoning that is in less need of exemplification. Rather, humans pick up the kind of knowledge required to do commonsense reasoning simply by living in the world and doing everyday things.
AI models have limited access to the kind of world knowledge that is necessary for commonsense reasoning. Neural networks designed for tasks that use natural language often only see text -- no visual data, sounds, tactile sensations, or scents are known to these networks. Since these natural language processing networks are limited to text alone, as a poor substitute for living in the world, we have them read a human-mind-boggling amount of text, including all of Wikipedia and thousands of books.
We then probe the commonsense reasoning capacity of the neural network by using a multiple-choice test called Commonsense Question Answering (CQA) [Talmor et al., 2019]. The neural network trains on a few examples from CQA that require commonsense reasoning to answer. Then, we administer the real test with questions the network has never seen. Compared to humans, these well-read neural networks have known to perform quite poorly on this task [Talmor et al., 2019].
We instill commonsense reasoning in neural networks by way of explanations and show that it improves performance on the CQA as shown below.
Commonsense Explanations (CoS-E) Dataset
The first part of our work proposes to show the network examples not only of questions with answer choices but also of the thought process that humans use to answer such commonsense questions. In order to get this information for the network, we ask humans to annotate these multiple-choice-question answer pairs with explanations that mimic their internal commonsense reasoning. Specifically, the human annotators are prompted with the following question: “Why is the predicted output the most appropriate answer?” Annotators were instructed to highlight relevant words in the question that justifies the ground-truth answer choice and to provide a brief open-ended explanation based on the highlighted justification could serve as the commonsense reasoning behind the question. The figure below shows examples from the CQA dataset along with the collected human commonsense explanations (CoS-E) dataset.
The CoS-E dataset can then be shown to the network while it is being trained to do the multiple-choice tests alongside the original input question and answer choices. Surprisingly, even though it does not have the CoS-E dataset during the real test, the network performs much better on the real test after seeing examples of human reasoning only during training. Though we do not yet fully understand how using the CoS-E dataset during training would benefit the networks even when CoS-E is not present at test time, we speculate that the explanations capture valuable information about the way the world works and the network learns to reason based on that information at test time. This well-read model is a pre-trained transformer neural network called BERT [Devlin et al., 2019].

Commonsense Auto-Generated Explanation (CAGE) Model
The second part of our work proposes to provide a form of reasoning for the network even during the real test. CoS-E cannot be used during the testing phase because it would assume that we had already told a human the correct answer and they wrote down an explanation for that answer. But, if the network could learn to generate its own kind of reasoning, it could do so during the real test as well.
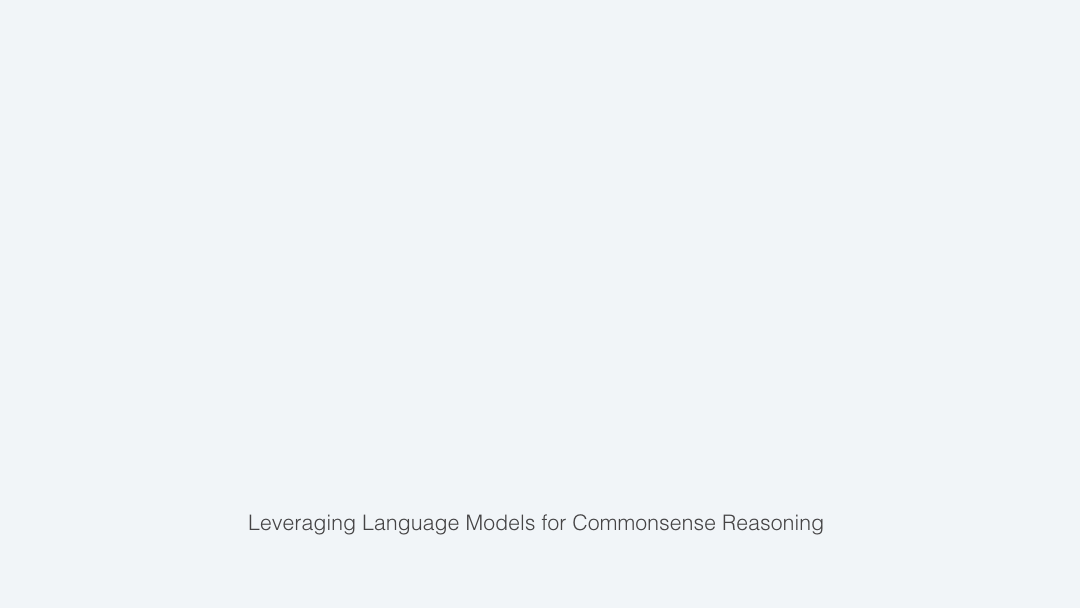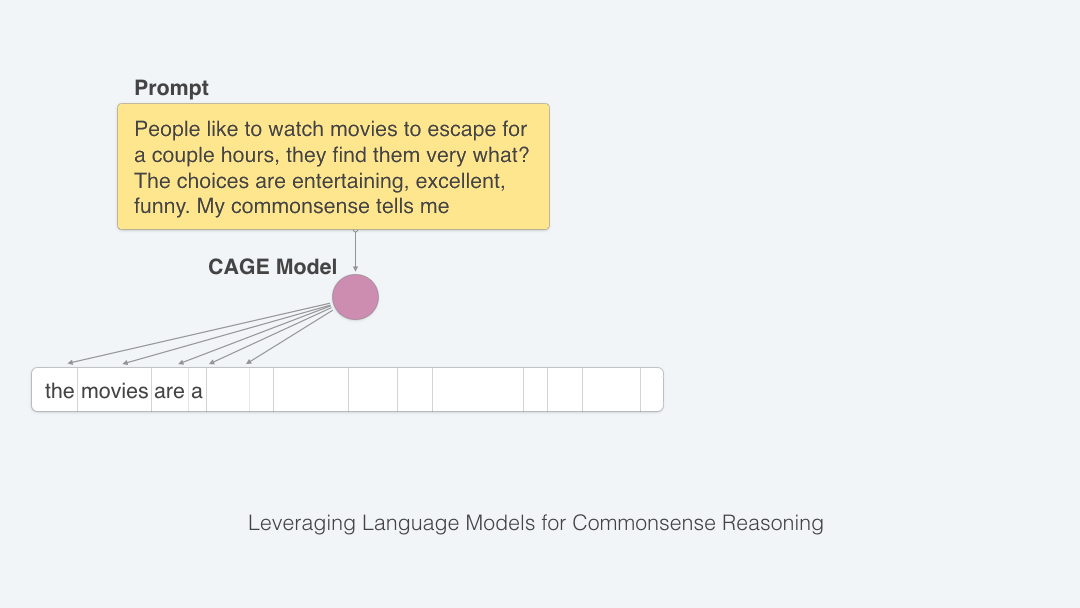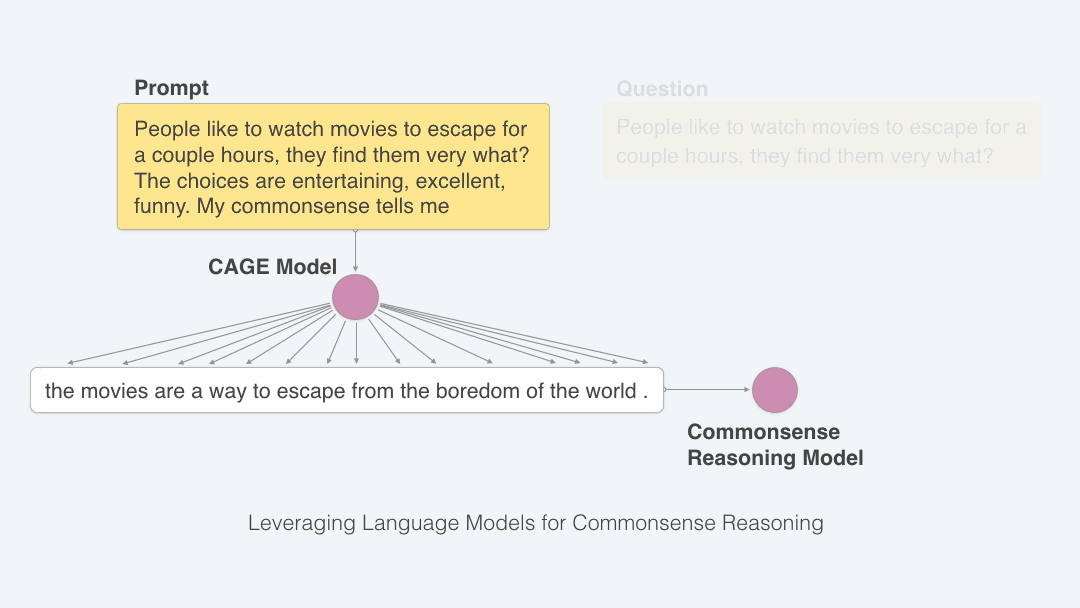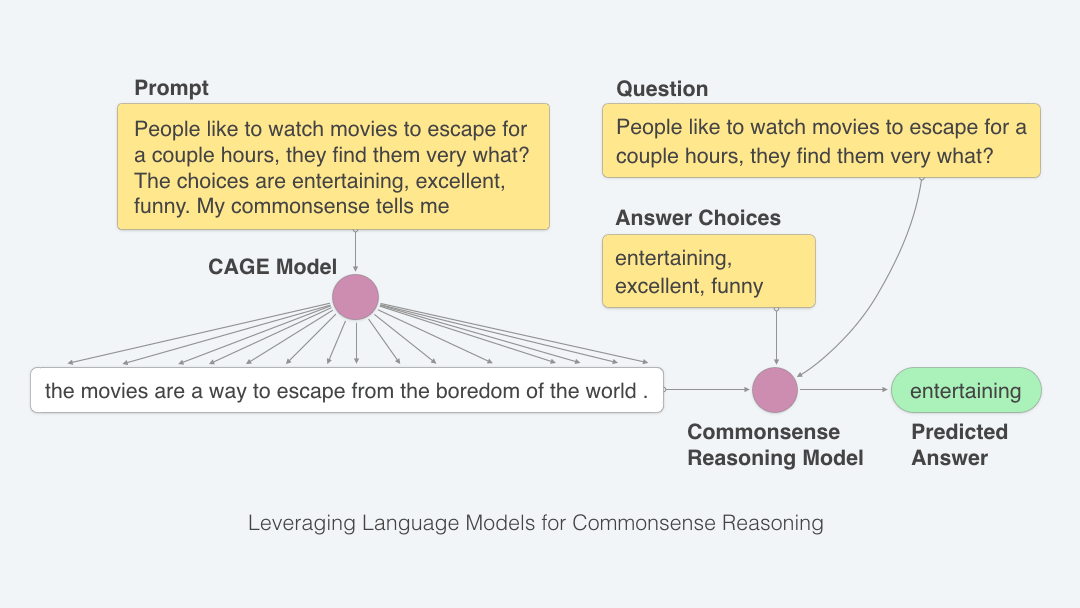
In order to do this, we train a second neural network that only learns how to generate commonsense reasoning and is not burdened by the task of multiple-choice question answering. We assume that this network starts out having read a lot of text, just as the test-taking network had. We then show it the commonsense questions and the answer choices. We do not tell the network the correct answer, but we train it to generate and mimic the human explanations from the CoS-E dataset. In this way, the network is trained to look at a question with answer choices and write down what it is thinking. Because this process does not depend on knowing the correct answer, we can use the commonsense auto-generate explanation (CAGE) model on the real test too.
This neural network that automatically generates explanations is a transformer language model (LM) called OpenAI GPT [Radford et al., 2018]. Figure below shows the process of how the LM generates explanation tokens given the input question and answer choices.
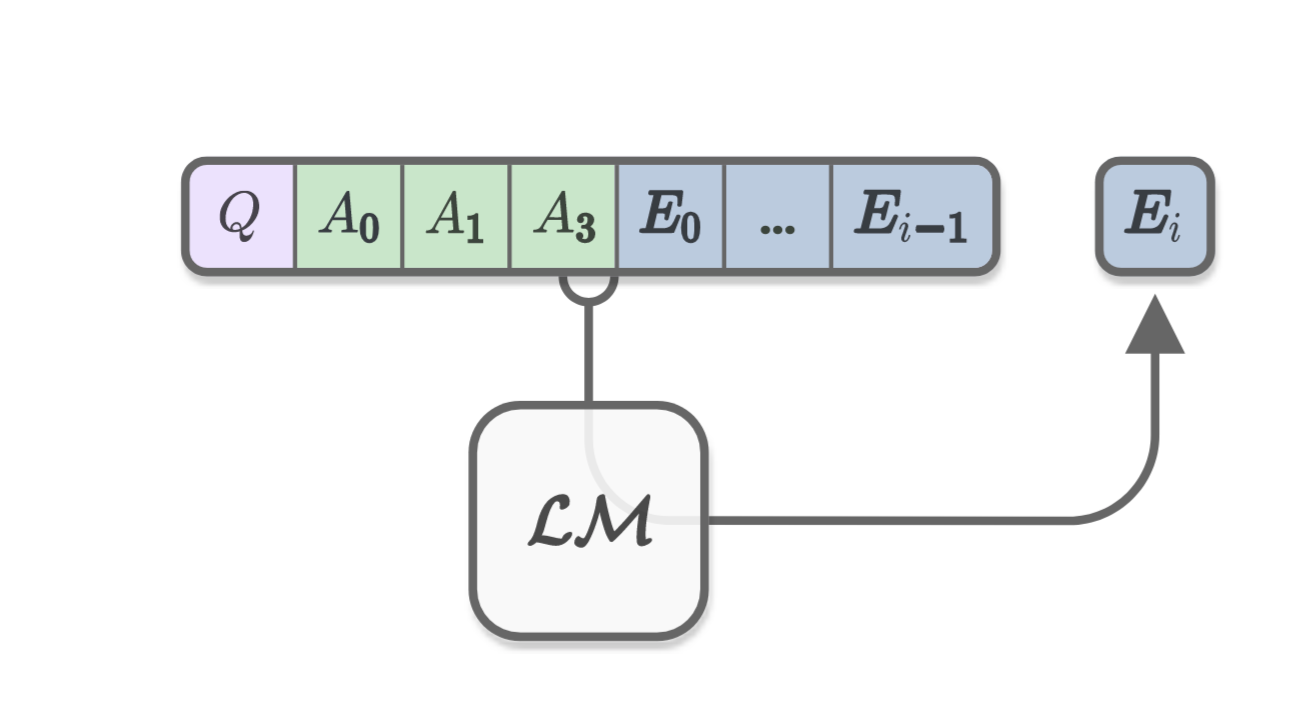
Now if we allow the CAGE model to generate commonsense reasoning for the test-taking network, i.e. the BERT, on the real test, we see marked improvements in the test score as shown in the figure below.
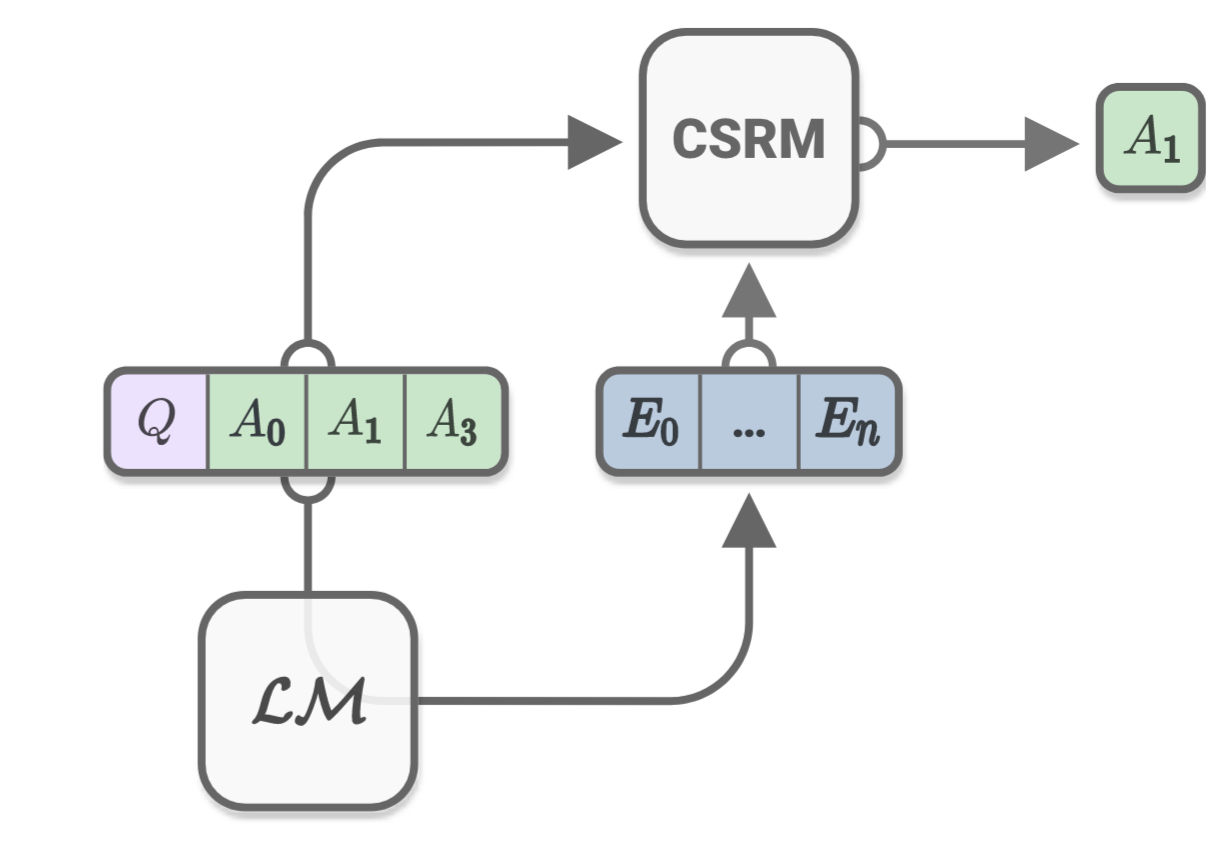
The CAGE model beats our own prior performance of using the CoS-E dataset only during training. The table below shows the results obtained by both our models compared with other state-of-the-art deep learning models. As shown, the state-of-the-art deep neural networks are still lagging far behind human performance on this task.

Here are some examples from the actual CQA data with human CoS-E data and our autogenerated reasoning from the CAGE model. We observed that our model’s reasoning typically employs a much simpler construction. Nonetheless, this simple declarative mode can sometimes be more informative than explanations from the CoS-E dataset. The CAGE model achieves this by either providing more explicit guidance (as in the final example) or by adding meaningful context (as in the second example by introducing the word ‘friends’).

We also extend our explanation generation work to other out-of-domain tasks such as story completion on the Story Cloze data [Mostafazadeh et al., 2016] and next scene prediction in the SWAG data [Zellers et al., 2018]. The LM neural network is asked to generate explanations on these tasks without actually training on these tasks, just by transferring its learned commonsense reasoning abilities from the CQA task. Here are some examples of the generated explanations on both these datasets.

In the SWAG dataset, each question is a video caption from activity recognition videos with choices about what might happen next and the correct answer is the video caption of the next scene. Generated explanations for SWAG appear to be grounded in the given images even though the language model was not at all trained on SWAG. Similarly, we found that for the Story Cloze dataset, the explanations had information pointing to the correct ending.
Conclusion
In summary, we introduced the Common Sense Explanations (CoS-E) dataset built on top of the existing CQA dataset. We also proposed the novel Commonsense Auto-Generated Explanations (CAGE) model that trains a language model to generate useful explanations when fine-tuned on the problem input and human explanations. These explanations can then be used by a classifier model to make predictions. We empirically show that such an approach not only results in state-of-the-art performance on a difficult commonsense reasoning task but also opens further avenues for studying explanation as it relates to interpretable commonsense reasoning. We also extended explanation transfer to out-of-domain datasets.Citation Credit
Nazneen Fatema Rajani, Bryan McCann, Caiming Xiong and Richard Socher. Explain Yourself! Leveraging Language Models for Commonsense Reasoning. In Proceedings of the 2019 Conference of the Association for Computational Linguistics (ACL2019).
References:
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova.BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL2019).
- Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. A corpus and cloze evaluation for deeper understanding of commonsense stories. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL2016).
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training.
- Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL2019).
- Rowan Zellers, Yonatan Bisk, Roy Schwartz, and Yejin Choi. Swag: A large-scale adversarial dataset for grounded commonsense inference. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP2018).