 Blog Home
Blog HomeLearning to retrieve reasoning paths from the Wikipedia graph
We develop a graph-based trainable retriever-reader framework which sequentially retrieves evidence paragraphs (reasoning paths) from the entire English Wikipedia to answer open-domain questions. Our framework shows state-of-the-art performance on HotpotQA, SQuAD Open, and Natural Questions Open without any architectural changes, showcasing its effectiveness and robustness for open-domain question answering.
Background
“Who is the author of the book Arabian Nights?” - In our daily life, we keep asking questions to acquire knowledge. How can we build a computer system that helps us find answers to such questions? Open-domain Question Answering (QA) is a natural language processing task to automatically answer a given query in any domains by searching large-scale document collections for evidence.
These days, retrieve-read approaches have been widely used, in which open-domain QA systems first select a few paragraphs for each query, using a computationally efficient term-based retriever (e.g., TF-IDF), and then read the top-ranked paragraphs to extract an answer.
The retrieve-read approaches have been shown to be effective for a simple and single-hop question, like the question above, which can be answered by a single paragraph. However, the research community gradually finds that these retrieve-read approaches limit themselves to simple and single-hop questions.

Let’s think about an example -- When was the football club founded in which Walter Otto Davis played at center-forward? -- Answering questions like this is challenging for the current scheme, and this is called multi-hop QA. How challenging is it?
For the example question, it is necessary to effectively "hop" to the paragraph 2 (Millwall F.C.), which contains the answer (1985). However, widely-used term-based retrieval may fail to find it, as the key entity, "Millwall Football Club," is not explicitly stated in the question. Like this, term-based retrieval is likely to fail to find multiple paragraphs multi-hop away from questions, because not all the evidence paragraphs have significant lexical overlap with the questions. On the other hand, the Millwall F.C. is clearly mentioned in the paragraph 1, Walter Davis, and the two paragraphs are internally linked in the Wikipedia. This graphical structured of the Wikipedia gives rich information about the underlying relationships between entities, but it has been rarely focused in open-domain QA research.
Learning to retrieve reasoning paths
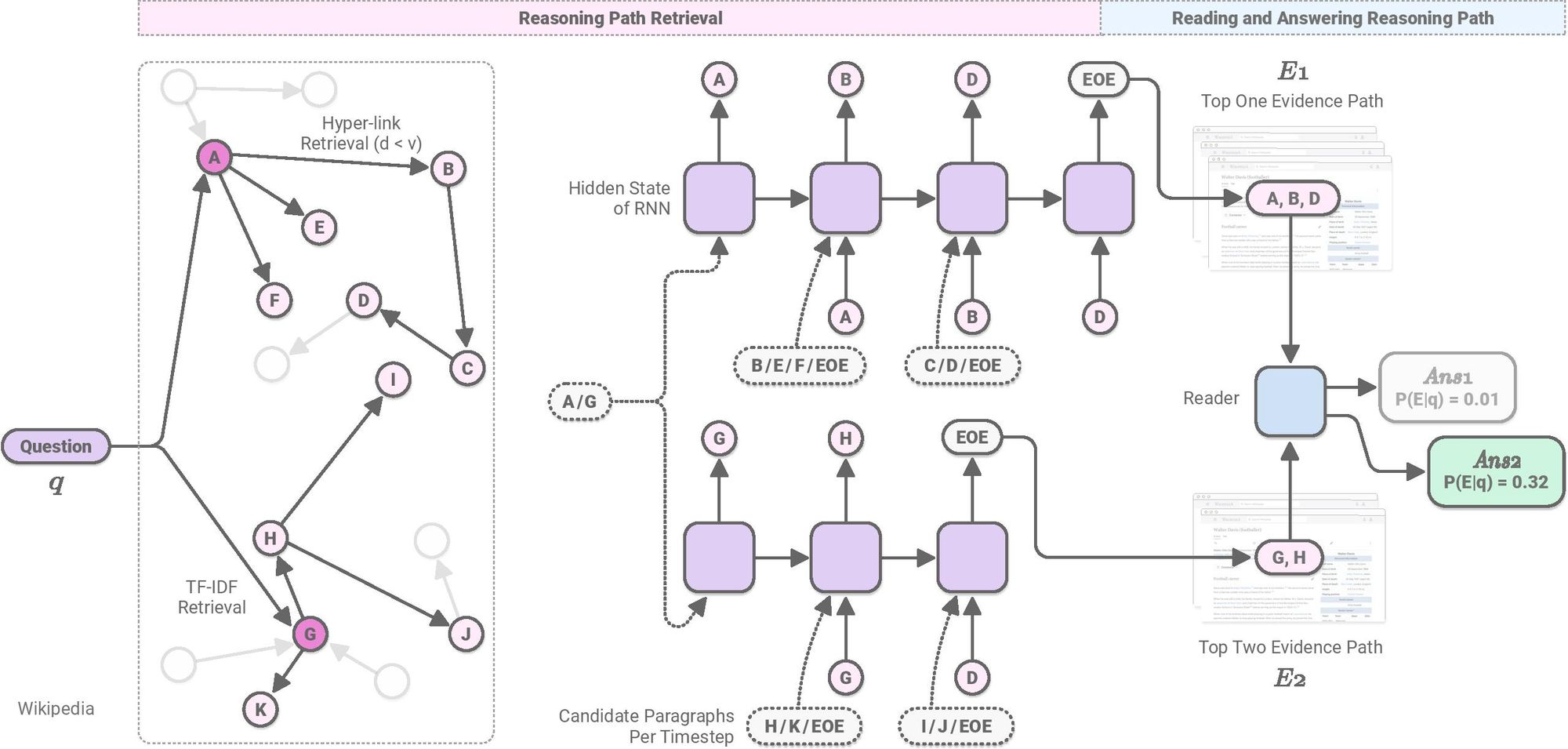
To this end, we introduce a trainable graph-based recurrent retriever-reader framework, which learns to retrieve reasoning paths over the Wikipedia graph to answer complex open-domain questions.
When we search answer for a complex question on Wikipedia, we may first look at a Wikipedia article we can easily find based on partial information in the question. If we cannot find enough information there, we might click a hyperlink to another highly related article, and terminate searching when we collect enough evidence to answer the question. Our intuition is that we can formulate the retrieval problem for open-domain QA as a neural path search over the large-scale Wikipedia graph, where each paragraph is considered as a node and each internal hyperlink is considered as an edge.

Our graph-based recurrent retriever sequentially retrieves paragraphs for a given question, using the graphical structure by conditioning on the previously retrieved paragraphs. In particular, our RNN-based module first retrieves seed nodes from the million-scale graph. Then the module estimates plausible reasoning paths (i.e., sequences of paragraphs) starting from the seed paragraphs.
By introducing efficient search strategies such as beam search, we reduce the computational complexity that has been considered as the bottleneck of multi-hop retrieval. The search process flexibly terminates with the end-of-evidence (EOE) symbol, which enables our framework to be applied to both single- and multi-hop open-domain QA.
After our retriever selects top K (e.g., K=8) reasoning paths for the question, our reasoning path reader more carefully reads the reasoning paths, to verify which path is the most plausible to extract the answer to the question. This multi-step verification strategy makes our overall framework more robust, instead of solely relying on each module's output.
Experimental Results
We experiment on three open-domain QA datasets, HotpotQA full wiki, SQuAD Open, and Natural Questions Open, and showcase the state-of-the-art accuracy on the three datasets. Notably, our method achieves significant improvement in HotpotQA, where the questions are complex and multi-hop retrieval is crucial, outperforming the previous best model by more than 14 points. Our experimental results also support our hypothesis that our training and inference strategies contribute to the effectiveness and robustness of our framework. Our framework is fully trainable on a single GPU with an 11GB GRAM.

Also, the retrieved reasoning path gives us interpretable insights into the underlying entity relationships used for multi-hop reasoning. Like the example above, our model first reads the Walter Otto Davis, the entity stated in the question, and identifies Millwall F.C., the football club he was playing at. Our reader correctly finds the answer, 1885, by reading the retrieved reasoning paths.
Conclusion
We have introduced a trainable graph-based retriever-reader framework that retrieves “reasoning paths” from Wikipedia for open-domain QA. Our proposed approach is not only competitive across three open-domain QA datasets, but also is fully trainable even with a single GPU. The discrete reasoning paths are helpful in interpreting our framework’s reasoning process. We hope this work facilitates future research focusing on the retrieval component in open-domain QA.
Acknowledgements
The figures on this blog post and in our paper were created by Melvin Gruesbeck, and we thank him for creating the comprehensive figures. We also thank members in University of Washington and Salesforce Research, and the anonymous reviewers for our ICLR2020 submission.
Github: https://github.com/AkariAsai/learning_to_retrieve_reasoning_paths
Paper: https://arxiv.org/abs/1911.10470
Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering. Akari Asai, Kazuma Hashimoto, Hannaneh Hajishirzi, Richard Socher, and Caiming Xiong. ICLR 2020.