 Blog Home
Blog HomeKnowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning


Automatically generating captions for images has emerged as a prominent interdisciplinary research problem in both academia and industry. It can aid visually impaired users, and make it easy for users to organize and navigate through large amounts of typically unstructured visual data. In order to generate high quality captions, the model needs to incorporate fine-grained visual clues from the image. Recently, visual attention-based neural encoder-decoder models have been explored, where the attention mechanism typically produces a spatial map highlighting image regions relevant to each generated word.
Most attention models for image captioning attend to the image at every time step, irrespective of which word is going to be emitted next. However, not all words in the caption have corresponding visual signals. Consider the example in above figure that shows an image and its generated caption "A white bird perched on top of a red stop sign". The words "a" and "of" do not have corresponding canonical visual signals. Moreover, language correlations make the visual signal unnecessary when generating words like "on" and "top" following "perched", and "sign" following "a red stop". In fact, gradients from non-visual words could mislead and diminish the overall effectiveness of the visual signal in guiding the caption generation process.
In this paper, we propose a novel adaptive attention model with a visual sentinel. At each time step, our model decides whether to attend to the image (and if so, to which regions) or to the visual sentinel, so that extract meaningful information for sequential word generation. We test our method on the COCO image captioning 2015 challenge dataset and Flickr30K. Our approach sets the new state-of-the-art by a significant margin.
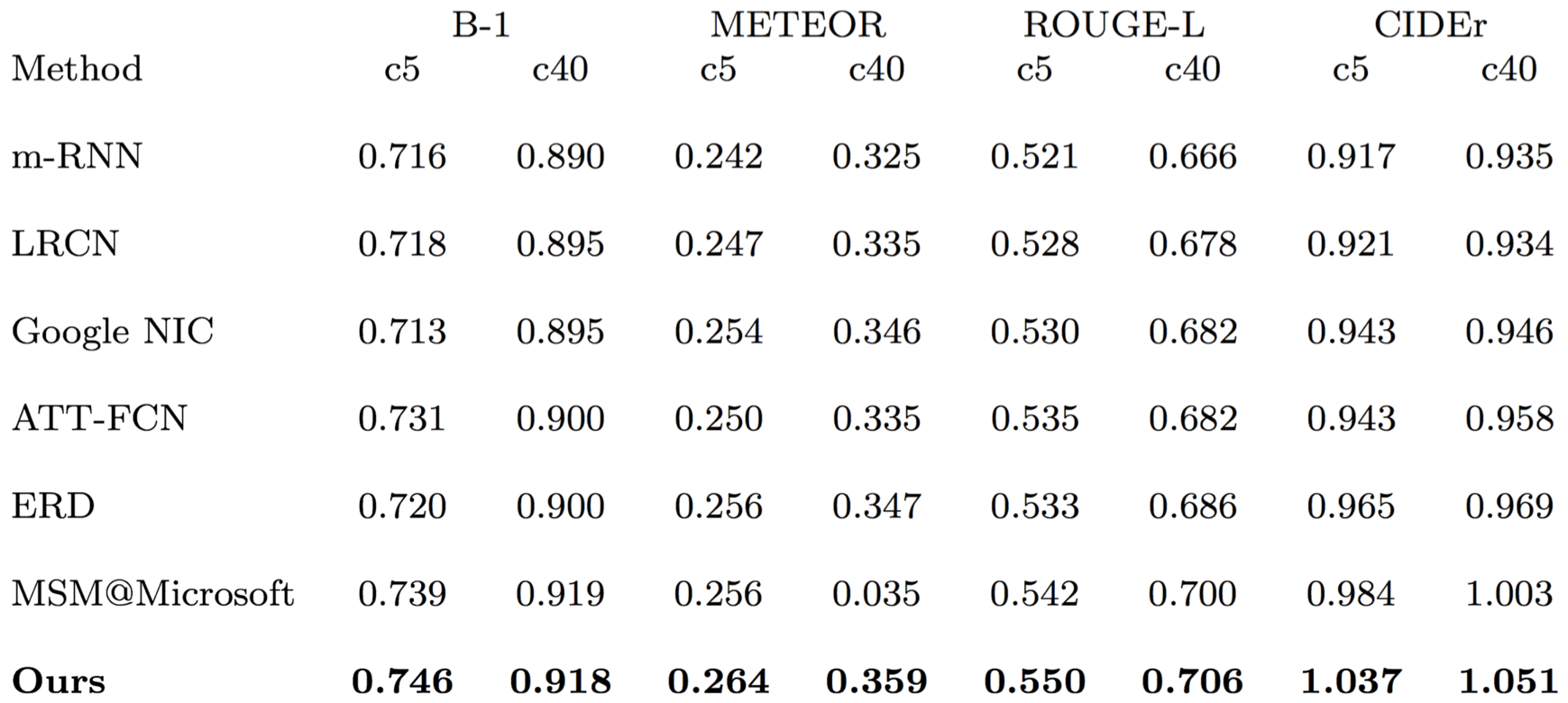
Accuracy comparison
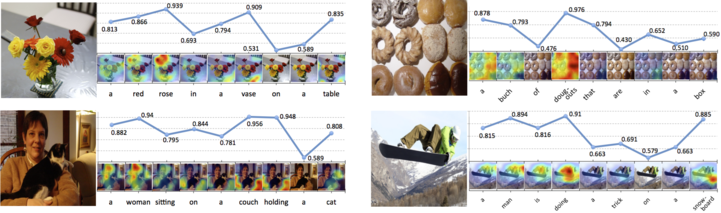
Qualitative output

Citation credit
Jiasen Lu^, Caiming Xiong^, Devi Parikh, and Richard Socher. 2016.
Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning.
(^ equal contribution)