 Blog Home
Blog HomeBeyond Names: How AI Research Is Revolutionizing Identity Resolution in Data Cloud



Do you know what the most common name is in America (as of 2023)? It's James Smith. Now, picture this: you’re in your CRM, speaking to "James Smith" from XYZ Company (located in Delaware). Is this the same James Smith as the "James S" that your colleague spoke to, whose notes you see? Is he the "Jame S Mith" who interacted with your marketing campaign? What about "James Smith" from XYZ Inc. who lives in California? These are all customers with different profiles, records, and contact points spread across various systems. But would you believe me if I said we're actually talking to the same person? This is a common problem that many organizations counter in their data.
In today's digital age, where data reigns supreme, organizations face a formidable challenge: making sense of the vast sea of information swirling around them. Across multiple datasets, people are represented differently: there may be different features, noise, typos, partial or incomplete information, obsolete data, and so on. Across industries or domains, customers face different identity resolution requirements. In the medical field, for instance, the risk of confusing Johnathan Smith’s records with those of John Smith could be detrimental. On the other hand, an industry such as retail might be more flexible and want to ensure users fall into as many relevant segments as possible.
Our work on identity resolution aims to solve this problem. The goal is to identify the same entities across datasets and unify source profiles into the best representation of each customer, but with data scattered across the virtual landscape, this can be a daunting task. Imagine sorting through the myriad pieces—names, addresses, browsing history—to reconstruct a clear image of each person or entity. From matching online purchases to in-store visits, or linking medical records for seamless healthcare, identity resolution is the glue that binds fragmented data, paving the way for tailored services, enhanced security, and deeper insights in our interconnected world.
Our AI research is already providing intelligent experiences, such as identity resolution with fuzzy first name matching and soft-matching. This solution addresses the challenge of duplication of records while providing the ability to tailor matching for different industries. And now, we’ve added control in fuzzy matching to include not only first name, but all features! By introducing fuzzy matching to all features we are empowering our customer by allowing for more flexible and inclusive matching criteria, accommodating variations in personal data entry and enabling accurate recognition even with minor discrepancies, thus ensuring a smoother and more personalized user experience.
Lets dive into the AI that is powering this new capability!
Two-Step Framework for Identity Resolution
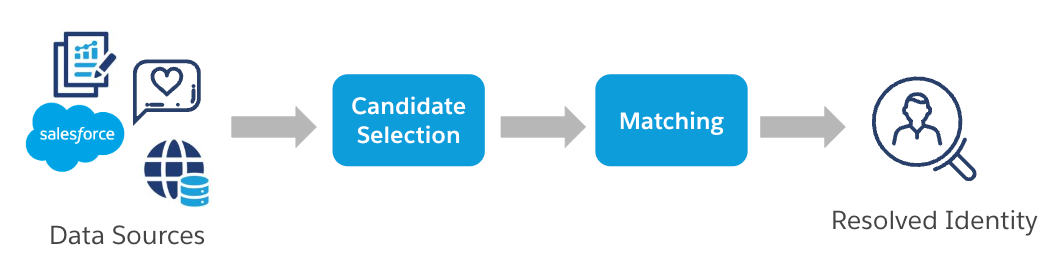
Lets begin by reviewing our general, two-step framework for identity resolution. To perform identity resolution, the first step after ingesting data is to cluster similar profiles together. This is referred to as the candidate selection step. This step is crucial for efficiency - with clusters of similar profiles, the search for matching identities is reduced to profiles within the same cluster, instead of the millions of profiles across all data sources. After clusters of similar profiles are formed, the matching step is next. In the matching step, a target profile and its candidates (profiles within the same cluster) are more carefully compared to determine the final matching and resolution of identities.
To enable fuzzy matching with any feature, we expanded the capabilities in both the candidate selection and matching steps.
Embedding-Based Candidate Selection
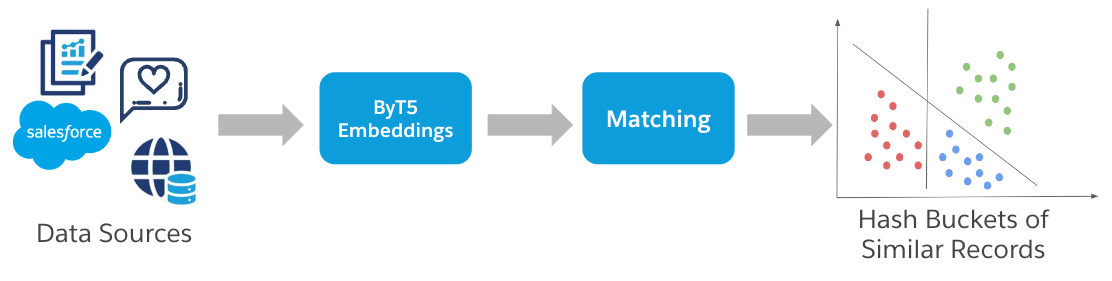
The ultimate goal is to enable fuzzy matching with any subset of features, chosen by the user. But before getting to the matching step, we first need to create clusters of close candidates based on those features. And to do that, we need a flexible approach that can find similar candidates based on any subset of features.
To achieve this, we developed an embedding-based candidate selection approach. Our method first passes all records into an embedding model, in this case the open-source model ByT5, to create embeddings, or vector representations, of each record. These vector representations capture meaningful information about the record, and vectors that are close geometrically indicate that the corresponding records are similar. For example, the vector representation for “James Smith, California, USA” will be geometrically close to the vector representation of “James R. Smith, CA, United States of America”.
For increased computational efficiency, we first quantized the embedding model, reducing the precision of the model weights from 32 bits down to 8 bits. This significantly improves embedding generation speed. After all embeddings are generated, we then apply local sensitivity hashing, which generates hash buckets, or clusters, of close embeddings. These clusters of similar embeddings correspond to similar records. So for a target record, we identify its cluster, determined by hash values, and all records in that cluster are considered the most closely related candidates.
Matching Formula for Any Features
Now that we have a flexible, embedding-based method for finding similar candidates, we must now find the true matches of our target profile amongst the top candidates. To do so, we developed a general matching formula, a combination of edit distances and metaphone (word pronunciation) distances, to produce a matching confidence score for any pair of strings, from any features.
Conclusion
Fuzzy matching is all about identifying and linking similar, but not identical strings of text. In our example above we saw that “James Smith“ and “James S“ are the same person; in exact matching there would have been no way to know that, but via fuzzy matching these two were similar enough that there was a chance that this was a match.
We're thrilled to announce the integration of fuzzy matching across all features in the Contact object, providing customers with the tailored solutions they require. Stay tuned for further updates as we continue to enhance this feature in future releases!
Explore More
Salesforce AI invites you to dive deeper into the concepts discussed in this blog post (links below). Connect with us on social media and our website to get regular updates on this and other research projects.
- Project site: www.salesforceairesearch.com/projects/data-cloud-identity-resolution
- Salesforce AI Website: salesforceairesearch.com
- Follow us on X (Previously Twitter): @SFResearch, @Salesforce
Acknowledgements
This new capability in Data Cloud is made possible through the collaboration of AI Research and Data Cloud teams.
AI Research: Zhiwei Liu, Jianguo Zhang, Shelby Heinecke, Huan Wang, Caiming Xiong, Vera Serdiukova, Silvio Savarese
Data Cloud: Stanislav Georgiev, Torrey Teats, Suresh Thalamati, Srishti Hunjan, Anthony Yeung