 Blog Home
Blog HomeHIVE: Harnessing Human Feedback for Instructional Visual Editing
HIVE is accepted to CVPR 2024.
Other authors include: Chia-Chih Chen, Ning Yu, Zeyuan Chen, Huan Wang, Silvio Savarese, Stefano Ermon, Caiming Xiong
We have seen the success of ChatGPT, which incorporates human feedback to align text generated by large language models to human preferences. Is it possible to align human feedback with state-of-the-art instructional image editing models? Now, Salesforce researchers have developed HIVE, one of the earliest works to fine-tune diffusion-based generative models with human feedback.

Background
Thanks to the impressive generation abilities of text-to-image generative models (e.g., Stable Diffusion), instructional image editing (e.g., InstructPix2Pix) has emerged as one of the most promising application scenarios. Different from traditional image editing where both the input and the edited caption are needed, instructional image editing only requires human-readable instructions. For instance, classic image editing approaches require an input caption “a dog is playing a ball”, and an edited caption “a cat is playing a ball”. In contrast, instructional image editing only needs editing instruction such as “change the dog to a cat”. This experience mimics how humans naturally perform image editing.
InstructPix2Pix fine-tunes a pre-trained stable diffusion by curating a triplet of the original image, instruction, and edited image, with the help of GPT-3 and Prompt-to-Prompt image editing.
Though achieving promising results, the training data generation process of InstructPix2Pix lacks explicit alignment between editing instructions and edited images.
Motivation
There is a pressing need to develop a model that aligns human feedback with diffusion-based models for the instructional image editing problem. For large language models such as InstructGPT and ChatGPT, we often first learn a reward function to reflect what humans care about or prefer on the generated text output, and then leverage reinforcement learning (RL) algorithms such as proximal policy optimization (PPO) to fine-tune the models. This process is often referred to as reinforcement learning with human feedback (RLHF).
The core challenge is how to leverage RLHF to fine-tune diffusion-based generative models. It is because applying PPO to maximize rewards during the fine-tuning process can be prohibitively expensive due to the hundreds or thousands of denoising steps required for each sampled image. Moreover, even with fast sampling methods, it is still challenging to back-propagate the gradient signal to the parameters of the U-Net.
Method

The proposed HIVE consists of three steps.
- Instructional supervised training. We follow the method of InstructPix2Pix to collect the training data and fine-tune the diffusion model. Specifically, we perform instructional supervised fine-tuning on the dataset that combines our newly collected 1.1M training data and the data from InstructPix2Pix. A proposed cycle consistency method is adopted to improve the scale of the dataset.
- For each input image and editing instruction pair, we ask human annotators to rank variant outputs of the fine-tuned model from step 1, which gives us a reward learning dataset. Using the collected dataset, we then train a BLIP based reward model (RM) that reflects human preferences.
- We estimate the reward for each training data used in step 1, and integrate the reward to perform human feedback diffusion model finetuning using our proposed objectives. The proposed fine-tuning approach is computationally efficient and offers similar costs compared with supervised fine-tuning.
Experiments
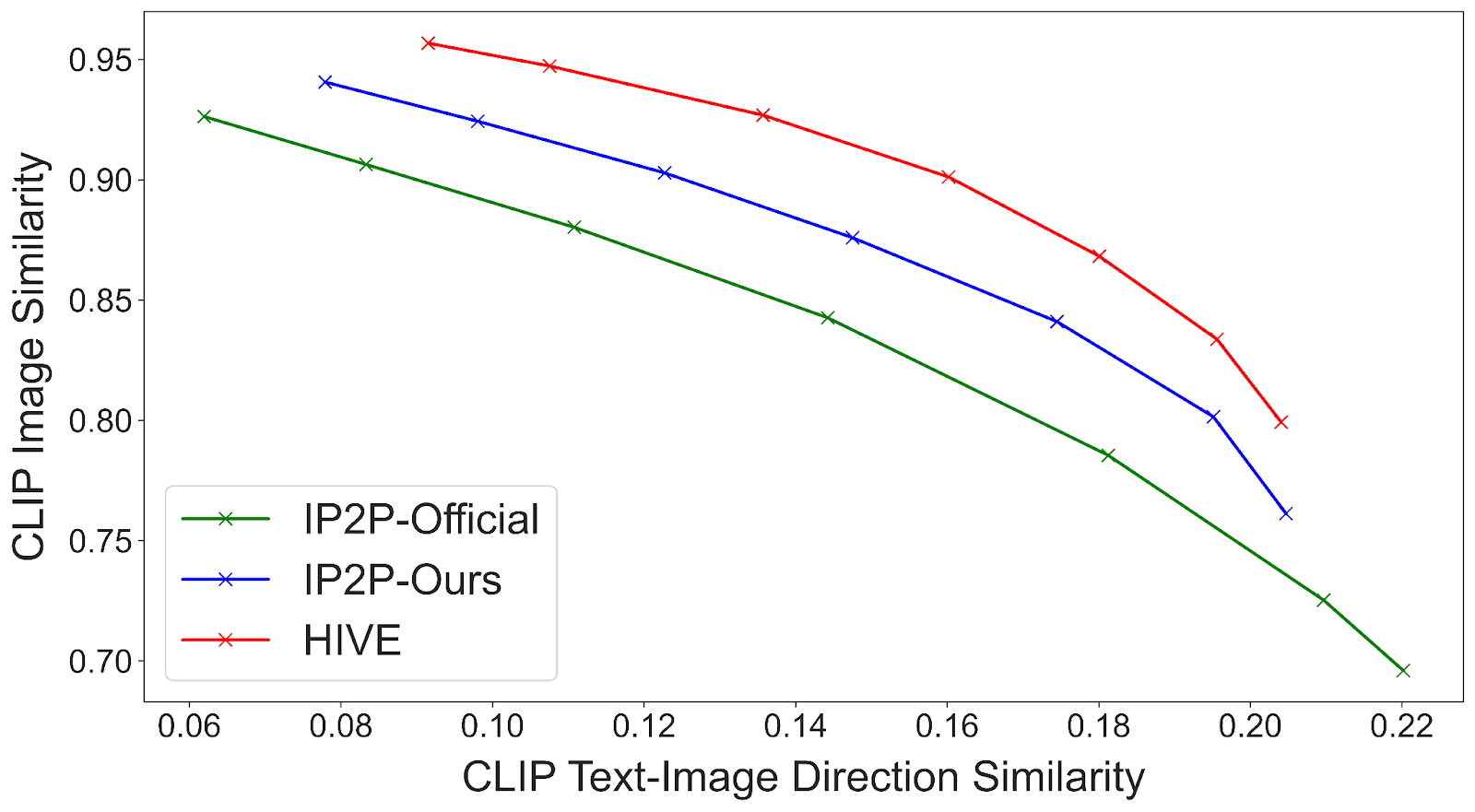
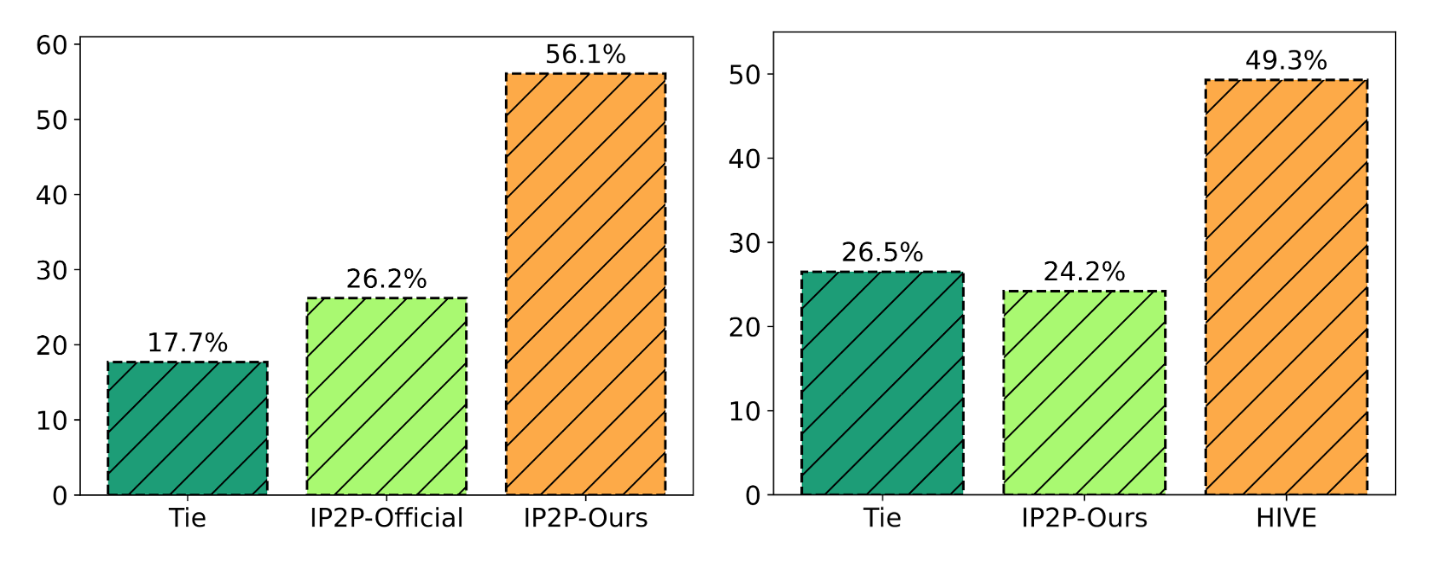
By open-sourcing all the training and evaluation data, we evaluate our method using two datasets: a synthetic dataset with 15K image pairs from InstrcutPix2Pix and a self-collected 1K dataset with real image-instruction pairs. For the synthetic dataset, we follow InstructPix2Pix and plot the tradeoffs between CLIP image similarity and directional CLIP similarity. For the 1K dataset, we conduct a user study determined by major votes.
Key results:
We show that HIVE consistently outperforms InstructPix2Pix with both the official model and our replicated model using our enlarged training dataset.
plicated model using our enlarged training dataset.

Explore More
arxiv: https://arxiv.org/abs/2303.09618
Code and data: https://github.com/salesforce/HIVE
Web: https://shugerdou.github.io/hive
Contact: shu.zhang@salesforce.com, x.yang@salesforce.com, yihaofeng@salesforce.com.