 Blog Home
Blog HomeFully-parallel text generation for neural machine translation
Over the past few years, neural networks have driven rapid improvements in accuracy and quality for natural language tasks like text classification and question answering. One area where deep learning has led to especially impressive results is tasks that require a machine to generate natural language text; two of these tasks where where neural network-based models have state-of-the-art performance are text summarization and machine translation.
However, so far all text generation models based on neural networks and deep learning have had the same, surprisingly human, limitation: like us, they can only produce language word by word or even letter by letter. Today Salesforce is announcing a neural machine translation system that can overcome this limitation, producing translations an entire sentence at a time in a fully parallel way. This means up to 10x lower user wait time, with similar translation quality to the best available word-by-word models.
Efficient neural machine translation
The field of machine translation has seen immense progress since 2014 with the application of neural networks and deep learning, or so-called Neural Machine Translation. One leap forward appeared in 2015 with the usage of attention, now a key technique across natural language processing tasks from entailment to question answering.
Although neural machine translation models provide substantially higher translation quality than traditional approaches, neural MT models are also much slower in a crucial way: they have far higher latency, the time to finish translating a new piece of text a user provides. This is because existing neural MT systems output translations one word at a time and run an entire neural network, with billions of computations, for each word they produce.
As a result, computational efficiency has been a major goal of recent research in neural machine translation. Beginning about a year ago, four research groups have published papers on more efficient neural MT models, primarily aiming to eliminate use of recurrent neural network layers (RNNs), which are common in deep learning sequence models but are slow because they're inherently difficult to parallelize. DeepMind introduced ByteNet, which replaces RNNs with a parallel tree structure based on convolutional neural networks. Salesforce Research proposed the QRNN, a computationally efficient drop-in replacement for RNN layers that improves performance in machine translation and other tasks. Earlier this year, Facebook AI Research announced fully-convolutional neural MT while Google Brain described the Transformer, a state-of-the-art MT model based entirely on attention.
All these approaches make model training faster, and can also provide incremental efficiency improvements at translation time, however, they all continue to be limited by the same problem described earlier: they all output word-by-word.
Overcoming the word-by-word limitation
This is a result of a basic technical property of existing neural network sequence models: they are autoregressive, meaning that their decoders—the components that produce the output text—need to use previously output text to produce the next word of their output. That is, autoregressive decoders make later words conditional on earlier ones. This property has several benefits; in particular, it makes autoregressive models simpler to train.
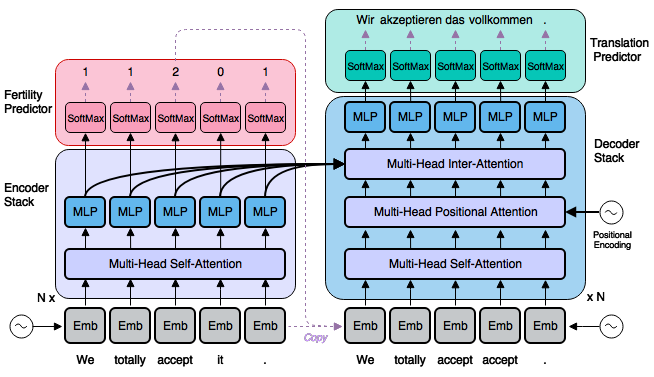
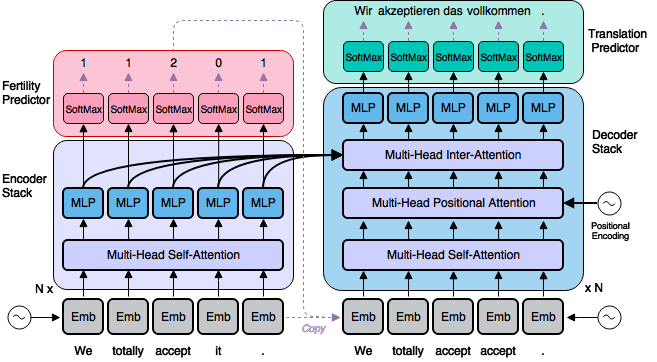
Our model (non-autoregressive because it doesn't have this property) starts with the same basic neural network layers as the recently published Transformer, but introduces a completely different text generation process based on a novel application of "fertility," a concept from traditional machine translation research introduced by IBM in the early 1990s. This latent fertility model is the main contribution of our paper.
Non-autoregressive neural machine translation
The difference between previous neural machine translation models and our new non-autoregressive model is represented in the following two animations. The purple dots represent neural network layers in the "encoder1," which is a network whose job is to understand and interpret the input sentence (here, English); the blue dots represent layers in the "decoder2," whose job it is to convert this understanding into a sentence in another language (here, German); and the colored lines represent attention connections between layers that allow the network to combine information from different parts of the sentence. Note that the purple encoder layers in both models can run all at once (the first part of the animations, with the dense red attention connections), while the blue decoder layers must work one word at a time in the first animation because each output word has to be ready (see the brown arrows) before the decoder can start producing the next one.

The basic way our model works is represented in the next animation. Here both the encoder and decoder can work in a parallel way, rather than word by word. Now the encoder has two jobs: first it must understand and interpret the input sentence, but it also has to predict a sequence of numbers (2, 0, 0, 2, 1) that are then used to start the parallel decoder by copying directly from the input text without requiring the autoregressive brown arrow from earlier. These numbers are called fertilities; they represent how much space each word is claiming in the output sentence. So if a word's fertility is 2, that means the model has decided to allocate two words in the output to translate it.

The sequence of fertilities provides the decoder with a plan or scaffold that allows it to produce the whole translation in parallel. Without a plan like this (known as a latent variable), the task of a parallel decoder would be like a panel of translators that each have to provide one word of an output translation but can't tell each other ahead of time what they're planning to say. Our use of fertilities as a latent variable makes sure that all the translators on this metaphorical panel, working in parallel, are making translation decisions that are consistent with each other.
Experiments
Despite an order of magnitude lower latency, our model ties the best translation quality (as measured by BLEU score) ever reported on one of the language pairs we tested (English to Romanian) and achieves competitive results on others.
| Model | WMT14 | WMT16 | IWSLT16 | ||||
|---|---|---|---|---|---|---|---|
| En-De | De-En | En-Ro | Ro-En | En-De | Latency | Speedup | |
| NAT | 17.35 | 20.62 | 26.22 | 27.83 | 25.20 | 39ms | 15.6x |
| NAT (+FT) | 17.69 | 21.47 | 27.29 | 29.06 | 26.52 | 39ms | 15.6x |
| NAT (+FT +NPD s=10) | 18.66 | 22.41 | 29.02 | 30.76 | 27.44 | 79ms | 7.68x |
| NAT (+FT +NPD s=100) | 19.17 | 23.20 | 29.79 | 31.44 | 28.16 | 257ms | 2.36x |
| Autoregressive b=1 | 22.71 | 26.39 | 31.35 | 31.03 | 28.89 | 408ms | 1.49x |
| Autoregressive b=4 | 23.45 | 27.02 | 31.91 | 31.76 | 29.70 | 607ms | 1.00x |
Example
One of the benefits of our model is that there's a simple way to obtain even better translations: try several different fertility plans in parallel, then choose the one with the best output as judged by another equally fast translation model. This "noisy parallel decoding" process is shown with a Romanian-to-English example below:

Citation credit
Jiatao Gu, James Bradbury, Caiming Xiong, Victor O.K. Li, and Richard Socher. 2017.
Non-Autoregressive Neural Machine Translation
Footnotes
1: For more on encoders in neural sequence models, see here.
2: For more on decoders in neural sequence models, including the details of attention mechanisms, see here.