 Blog Home
Blog HomeDouble Hard-Debias: Tailoring Word Embeddings for Gender Bias Mitigation
TL;DR: Word embeddings derived from human-generated corpora inherit strong gender bias which can be further amplified by downstream models. We discover that corpus regularities such as word frequency negatively impact the performance of existing post-hoc debiasing algorithms and propose to purify the word embeddings against such corpus regularities prior to inferring and removing the gender subspace.
Gender Bias in Word Embeddings. Word embeddings are learned vectors of real numbers representing words in a vocabulary. They are able to capture semantic and syntactic meanings of words and relations with other words. Despite widespread use in natural language processing (NLP) tasks, word embeddings have been criticized for inheriting unintended gender bias from training corpus. As discussed in [1], we think a word exposes gender bias when it is gender-neutral by definition but its learned embedding is closer to a certain gender. For example, in the following figure, $x$ is a projection onto the difference between the embeddings of the words he and she, and $y$ is a direction learned in the embedding that captures gender neutrality, with gender-neutral words above the line and gender-specific words below the line. While brilliant and genius are gender-neutral by definition, their embeddings are closer to he. Similarly, homemaker and sewing are more associated with she.

Why Gender Bias Matters? Gender bias in word embeddings is a serious problem. Imagine that people develop a resume filtering model based on biased word embeddings. This model can potentially filter out female candidates for positions like programmer and also exclude male candidates for positions like hairdresser. Similarly, a question answering model which treats doctors are all male and nurses are all female can provide wrong answers when it is applied to understand medical reports.
The Earlier Hard Debias Method. Previous work [1] reduces gender bias by subtracting the component associated with gender from word embeddings through post-processing. Specifically, it requires a set of gender specific word pairs and computes the first principal component of difference vectors of these pairs as the gender direction in the embedding space. Second, it projects biased word embeddings into a subspace orthogonal to the inferred gender direction to get rid of gender bias. While [1] demonstrates that such a method alleviates gender bias in word analogy tasks, [2] argues that the effectiveness of these efforts is limited, as the gender bias can still be recovered from the geometry of the embeddings post-debiasing.

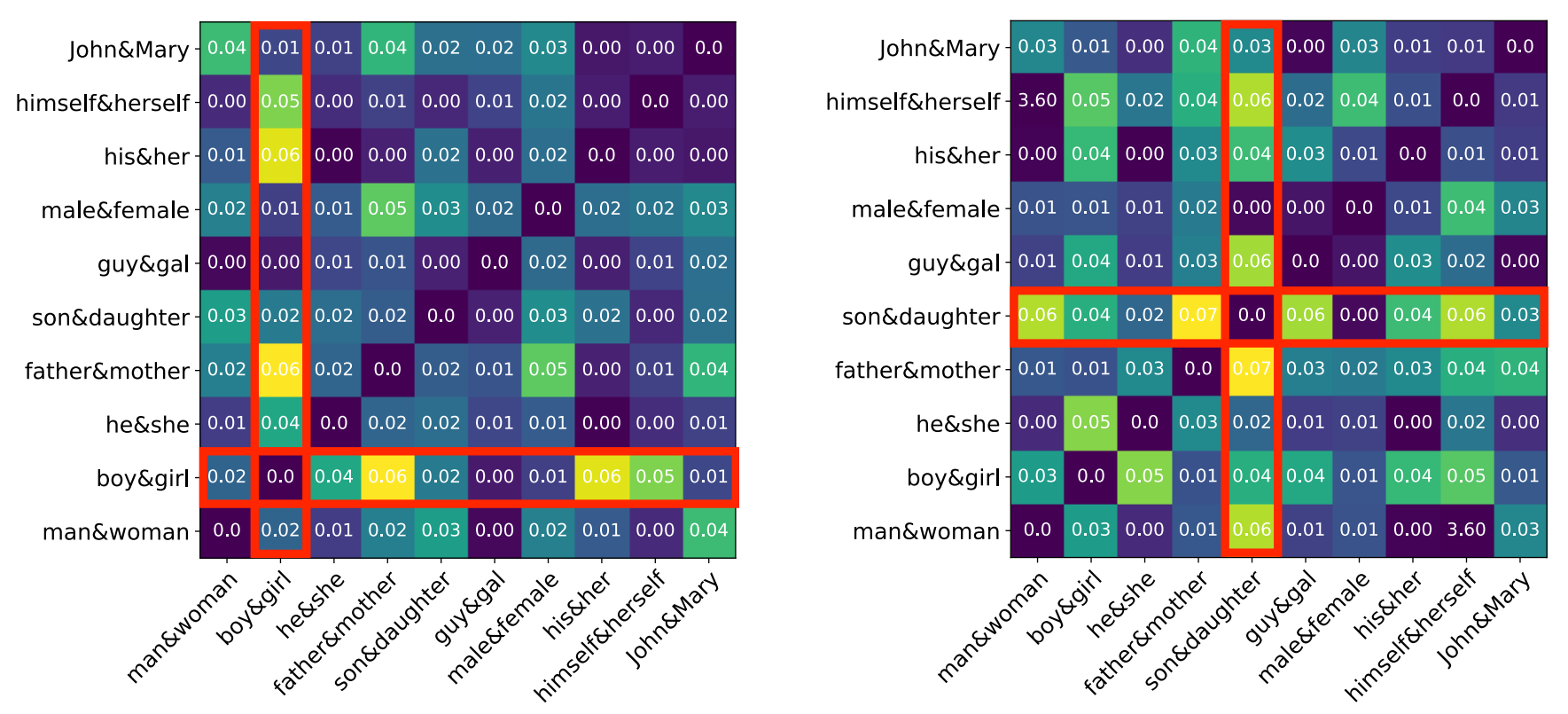
Word frequency distorts gender direction. In this work, we hypothesize that it is difficult to identify the true gender direction of word embeddings in the manner employed by the existing Hard Debias method. [3] & [4] show that word frequency significantly impact the geometry of word embeddings. For example, popular words and rare words cluster in different subregions of the embedding space, despite the fact that words in these clusters are not semantically similar. This can negatively affect the procedure of identifying the gender direction and consequently, degrade the ability of Hard Debias for debiasing gender. We empirically demonstrate that the frequency change of certain words leads to significant changes in the similarities between the corresponding difference vector and other difference vectors, as shown in the following figure.

Double-Hard Debias: Improve Hard Debias by Eliminating Influence from Frequency. Since word frequency can distort the gender direction, we propose Double-Hard Debias to eliminate the negative effect from word frequency. The key idea is to project word embeddings into an intermediate subspace before applying Hard Debias. Recall that Hard Debias reduces gender bias by transforming the embedding space into a genderless one. Similarly, in Double-Hard Debias, we first transform all word embeddings into a frequency free subspace where in this subspace, we are able to compute a more accurate gender direction. More specifically, we try to find the dimension which encodes frequency information that distracts the gender direction computation. We then project away the component along this specific dimension from word embeddings to obtain revised embeddings and apply Hard Debias on revised embeddings.

To identify this dimension, we adopt clustering of top biased words as a proxy and iteratively test the principal components of the word embeddings. Details steps are as follows:
- Compute principal components of all word embeddings as frequency dimension candidates.
- Select a set of top biased male and female words (e.g. programmer, homemaker, game, dance and so on).
- Repeat step 4-6 for each candidate dimension $u_i$ independently.
- Project embeddings into an intermediate space which is orthogonal to $u_i$ and thus get revised embeddings.
- Apply Hard Debias on the revised embeddings.
- Cluster debiased embeddings from step 5 of the selected top biased words and compute the clustering accuracy.
If the clustering algorithm in step 6 still clusters biased words into two groups aligned with gender, it means removing $u_i$ failed to improve debiasing. We hence select the $u_i$ that leads to the most significant drop in biased word clustering accuracy and remove it.
How well does Double-Hard Debias Perform? We evaluate Double-Hard Debias on several bias mitigation benchmarks including an important downstream task, coreference resolution. We use WinoBias dataset to quantify gender bias in coreference systems. WinoBias consists of two types of sentences. Each type of sentence can be divided into a pro-stereotype subset and an anti stereotype subset. Gender is the only difference between these two subsets. An example from type 1 sentences contains a pro-stereotype sentence: The physician hired the secretary because he was overwhelmed with clients. And an anti-stereotype sentence: The physician hired the secretary because she was overwhelmed with clients. The performance gap between pro-stereotype and anti-stereotype reflects how differently the coreference system performs on the male group and female group. So we treat this gap as the gender bias score. The original GloVe embeddings carry significant gender bias as we can see the performance gap reaches 29 points and 15 points on two types of sentences. Compared with Hard Debias and other state-of-the-art debiasing approaches, our method achieves the minimal difference in both two types of coreference sentences. Meanwhile, Double-Hard Debias also preserves the useful semantic information in word embeddings. We only observe a 0.1% loss in the F1 score on the original test set.

We also conduct tSNE projection for all top 500 biased female and male embeddings. As shown in the following figure, the original GloVe embeddings are clearly projected to different regions suggesting a strong gender bias. Double-Hard GloVe mixes up male and female embeddings to the maximum extent compared to other methods, showing less gender information can be captured after debiasing.

Conclusion: We found that simple changes in word frequency statistics can have an undesirable impact on the debiasing methods used to remove gender bias from word embeddings. Though word frequency statistics have until now been neglected in previous gender bias reduction work, we propose Double-Hard Debias, which mitigates the negative effects that word frequency features can have on debiasing algorithms. We believe it is important to deliver fair and useful word embeddings and we hope that this work inspires further research along this direction.
Github: https://github.com/uvavision/Double-Hard-Debias
Paper: https://arxiv.org/abs/2005.00965
Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation.
Tianlu Wang, Xi Victoria Lin, Nazeen Fatema Rajani, Bryan McCann, Vicente Ordonez and Caiming Xiong. ACL 2020.
References:
- Tolga Bolukbasi, Kai-Wei Chang, James Zou, Venkatesh Saligrama, and Adam Kalai. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. In NeurIPS, 2016.
- Hila Gonen and Yoav Goldberg. Lipstick on a pig: Debiasing methods cover up systematic gender biases in word embeddings but do not remove them. In NAACL-HLT, 2019
- Chengyue Gong, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tie-Yan Liu. Frage: Frequency-agnostic word representation. In NeurIPS, 2018
- Jiaqi Mu and Pramod Viswanath. All-but-the-top: Simple and effective postprocessing for word representations. In ICLR 2018.