 Blog Home
Blog HomeCoMatch: Advancing Semi-supervised Learning with Contrastive Graph Regularization
TL; DR: We propose a new semi-supervised learning method which achieves state-of-the-art performance by learning jointly-evolved class probabilities and image representations.
What are the existing semi-supervised learning methods?
Semi-supervised learning aims to leverage few labeled data and a large amount of unlabeled data. As a long-standing and widely-studied topic in machine learning, it has great value in practical domains where labeled data are expensive to acquire. Recent developments in semi-supervised learning mostly fall into two categories. The first category is pseudo-labeling, also called self-training. In pseudo-labeling, the model produces its class prediction on each unlabeled sample, which is used as the artificial label to train against. One of the state-of-the-art methods from this category is FixMatch [2]. The second category utilizes self-supervised learning on unlabeled data, followed by supervised fine-tuning on labeled data. State-of-the-art methods from this category include SimCLR [3] and MoCo [4], which adopts self-supervised contrastive learning.
However, both pseudo-labeling and self-supervised learning methods have their limitations. Pseudo-labeling methods heavily rely on the quality of the model's class prediction on unlabeled samples, thus suffering from confirmation bias where the prediction mistakes would accumulate. Self-supervised learning methods are task-agnostic, and the widely used contrastive learning objective may learn representations that are suboptimal for the specific classification task.
Introducing our new method: CoMatch.
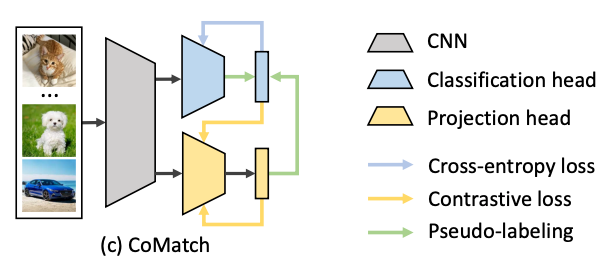
We propose CoMatch: semi-supervised with contrastive graph regularization, a new semi-supervised learning method that addresses the existing limitations. A conceptual illustration of CoMatch is shown below. In CoMatch, each image has two compact representations: a class probability produced by the classification head and a low-dimensional embedding produced by the projection head. The two representations interact with each other and jointly evolve in a co-training framework. CoMatch unifies popular ideas including consistency regularization, entropy minimization, contrastive learning, and graph-based semi-supervised learning.

(a) Task-specific self-training: the model predicts class probabilities for the unlabeled samples as the pseudo-label to train against. (b) Task-agnostic self-supervised learning: the model projects samples into low-dimensional embeddings, and performs contrastive learning to discriminate embeddings of different images. (c) CoMatch: class probabilities and embeddings interact with each other and jointly evolve in a co-training framework.
How does CoMatch work?
As shown in the following figure, CoMatch contains four major steps:
- Given a batch of unlabeled images, CoMatch first produces memory-smoothed pseudo-labels using weakly-augmented images. The model’s class predictions are smoothed by neighboring samples in the embedding space.
- The pseudo-labels are used as targets to train the classifier, using strongly-augmented images as inputs.
- CoMatch construct a pseudo-label graph, which measures the pairwise similarity of the unlabeled images. The pseudo-label graph contains self-loops as self-supervision.
- The pseudo-label graph is used as the target to train an embedding graph with contrastive learning, such that images with similar pseudo-labels are encouraged to have similar embeddings.

CoMatch achieves SoTA performance
CoMatch achieves state-of-the-art performance on multiple semi-supervised learning benchmarks. In the following table, we show the performance of CoMatch and existing methods on the ImageNet dataset. The training dataset contains 1% or 10% of images with labels, and the rest are unlabeled images.CoMatch achieves 66.0% top-1 accuracy with 1% labels and 73.6% accuracy with 10% of labels, substantially outperforming existing methods. We further show that self-supervised pre-training can improve performance, especially for the label-scarce scenario, but at the cost of longer training time.

Next, we show that CoMatch also achieves SOTA on CIFAR-10 and STL-10 datasets.

Furthermore, CoMatch achieves better representation learning performance. We transfer the ImageNet pre-trained model to objection detection and instance segmentation tasks on COCO. As shown in the following table, the models pre-trained with CoMatch outperform supervised pre-training using 100% labels.

What’s next?
We have demonstrated the power of CoMatch in training deep neural networks with few labeled images. We hope that CoMatch can spur more research in the important area of semi-supervised learning, and enable machine learning models to be deployed in practical domains where labels are expensive to acquire.
If you are interested in learning more, please check out our paper and feel free to contact us at junnan.li@salesforce.com.
References
- Junnan Li, Caiming Xiong, Steven Hoi. CoMatch: semi-supervised learning with contrastive graph regularization. arXiv:2011.11183, 2020.
- Kihyuk Sohn, David Berthelot, et al. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. In NeurIPS, 2020.
- Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In ICML, 2020.
- Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, 2020.