 Blog Home
Blog HomeCodeT5: The Code-aware Encoder-Decoder based Pre-trained Programming Language Models
TL; DR: Introducing CodeT5 --- the first code-aware, encoder-decoder-based pre-trained programming language model, which enables a wide range of code intelligence applications including code understanding and generation tasks. CodeT5 achieves state-of-the-art performance on 14 sub-tasks in the CodeXGLUE code intelligence benchmark.
Given the goal of improving software development productivity with machine learning methods, software intelligence research has attracted increasing attention in both academia and industries over the last decade. Software code intelligence techniques can help developers reduce tedious repetitive workloads, enhance the programming quality, and improve the overall software development productivity. This would reduce time spent writing software as well as reduce computational and operational costs. In this work, we focus on the fundamental challenge of software code pre-training, which has great potential to boost a wide spectrum of downstream applications in the software development lifecycle.
However, existing code pre-training methods have two major limitations. First, they often rely on either an encoder-only model similar to BERT or a decoder-only model like GPT, which is suboptimal for generation and understanding tasks. For example, CodeBERT [2] requires an additional decoder when applied for the code summarization task, where this decoder cannot benefit from the pre-training. Second, most current methods simply adopt the conventional NLP pre-training techniques on source code by regarding it as a sequence of tokens like natural language (NL). This largely ignores the rich structural information in programming language (PL), which is vital to fully comprehend the code semantics.
To address these limitations, we created CodeT5, an identifier-aware unified pre-trained encoder-decoder model. CodeT5 achieves state-of-the-art performance on multiple code-related downstream tasks including understanding tasks such as code defect detection and clone detection, and generation tasks across various directions including PL-NL, NL-PL, and PL-PL. In what follows, we will explain how CodeT5 works.
How Does CodeT5 Work?

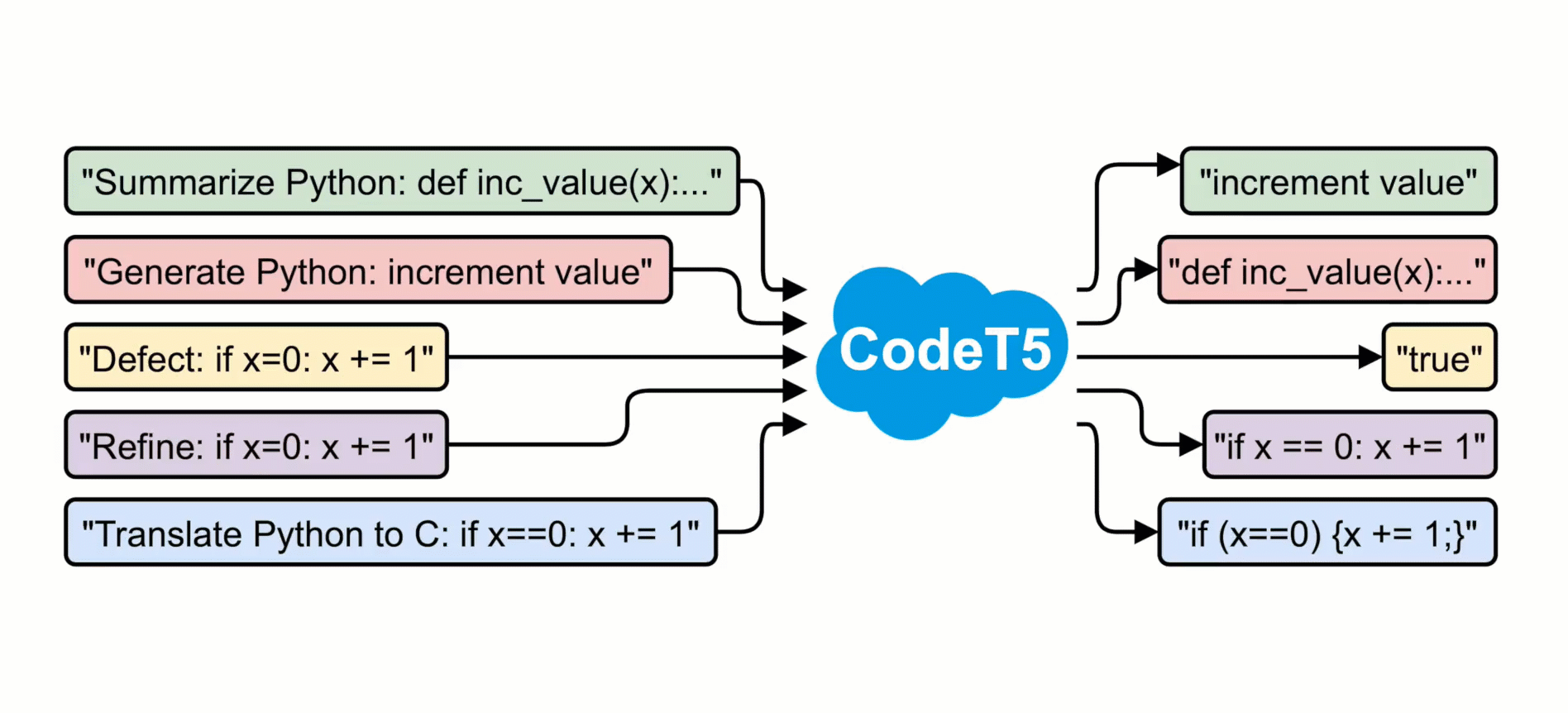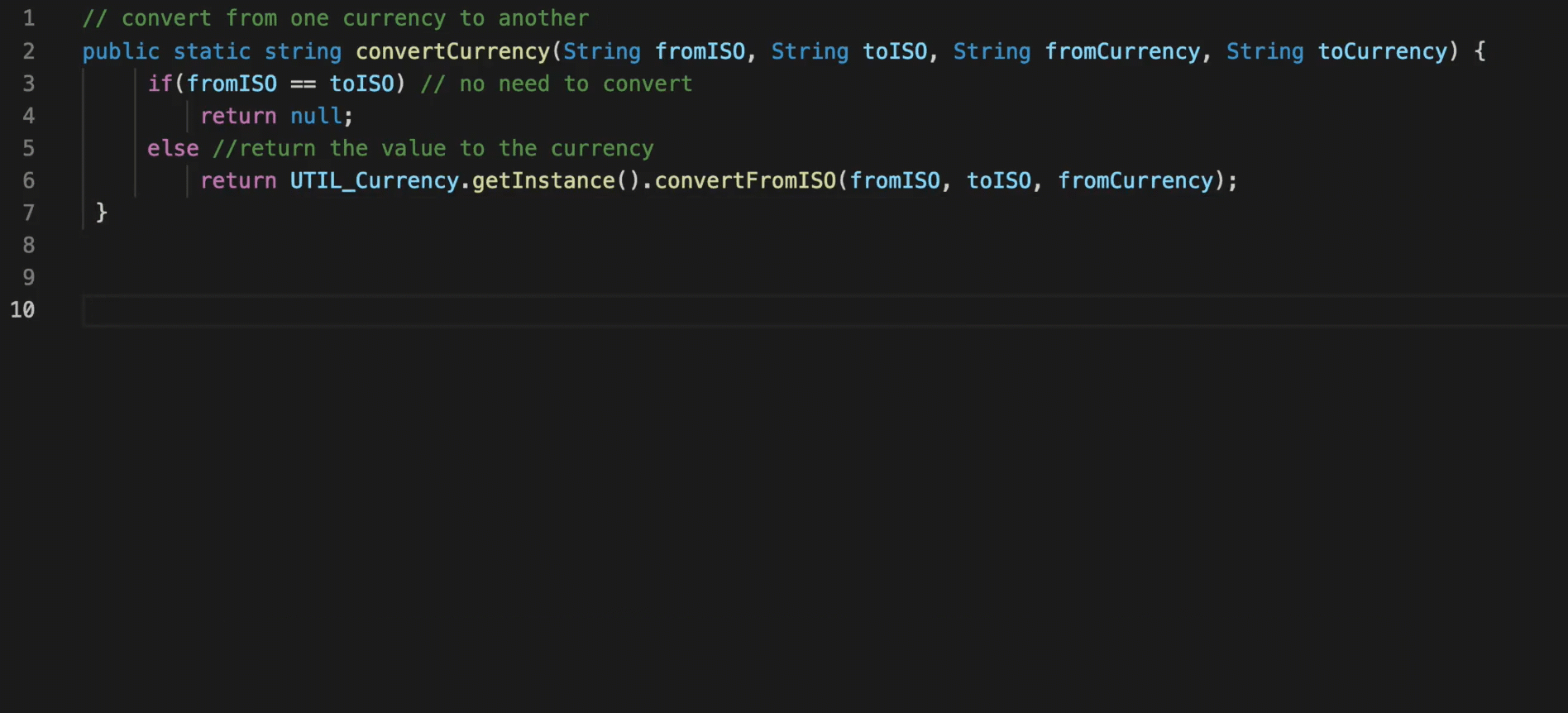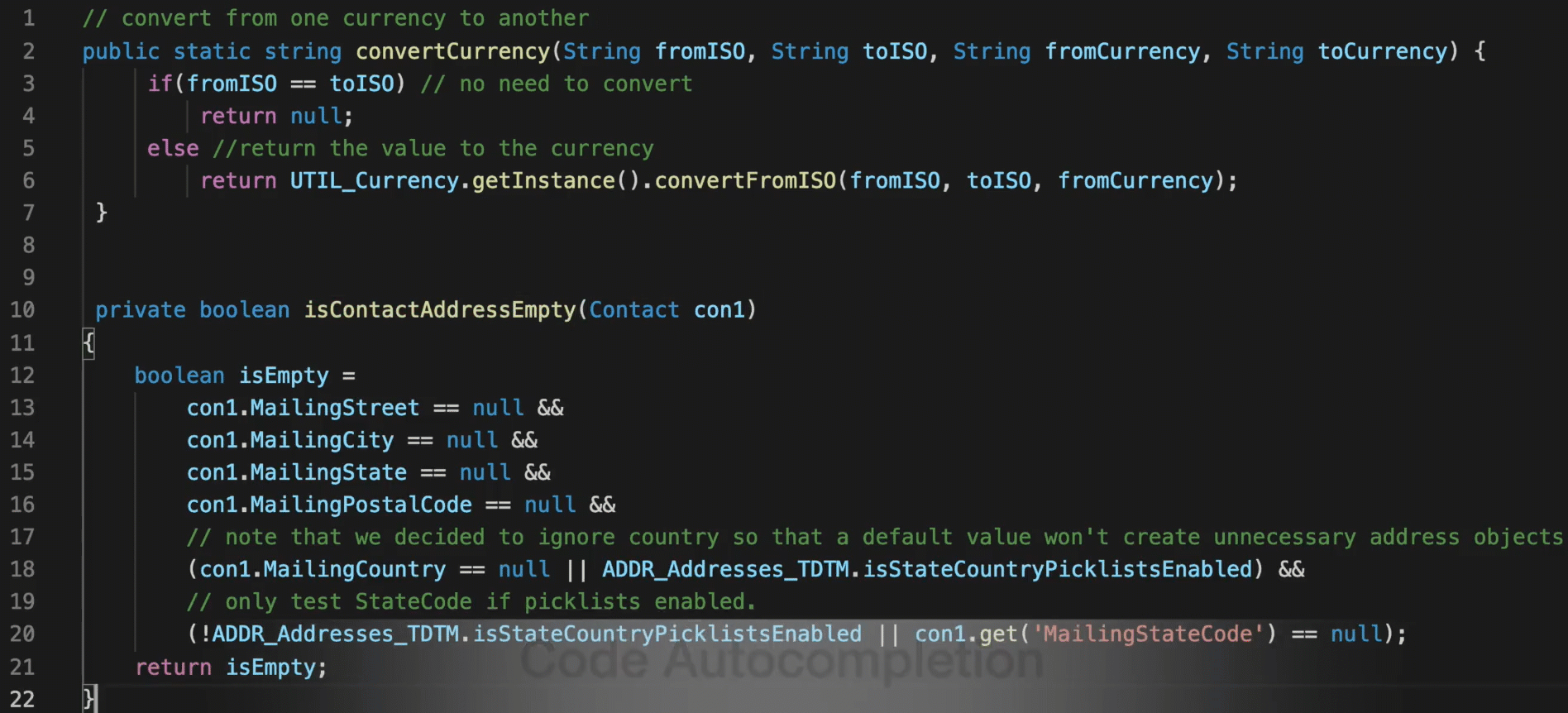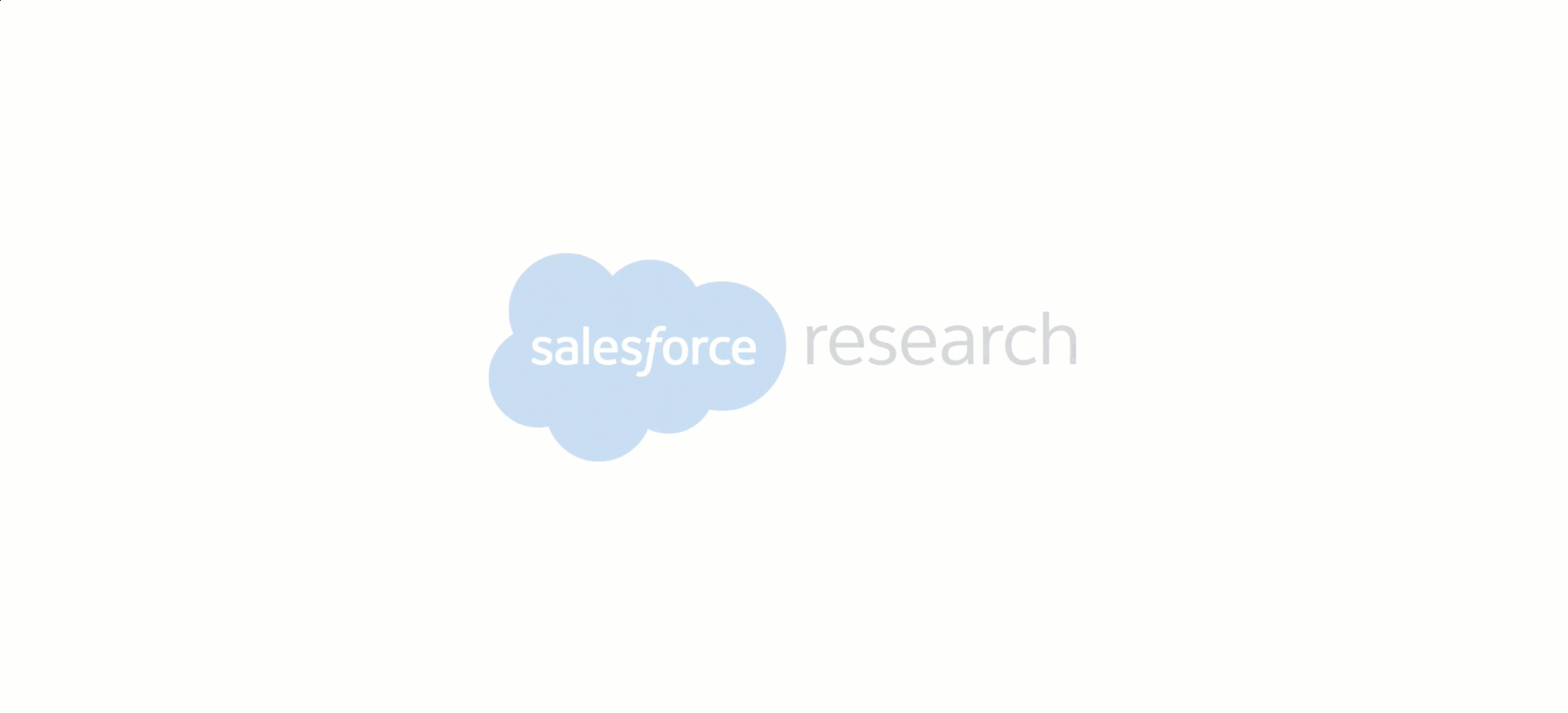
CodeT5 builds on the similar architecture of T5 but incorporates code-specific knowledge to endow the model with better code understanding. It takes code and its accompanying comments as a sequence input. As illustrated in the figure above, we pre-train CodeT5 by first alternatively optimizing the following objectives (a-c) and then the objective (d):
Objective (a): Masked Span Prediction (MSP) randomly masks spans with arbitrary lengths and requires the decoder to recover the original input. It captures the syntactic information of the NL-PL input and learns robust cross-lingual representations as we pre-train on multiple PLs with a shared model.
Objective (b): Identifier Tagging (IT) applied only to the encoder which distinguishes whether each code token is an identifier (e.g., variables or function names) or not. It works like the syntax highlighting feature in some developer-aided tools.
Objective (c): Masked Identifier Prediction (MIP), in contrast to MSP, only masks identifiers and employs the same mask placeholder for all occurrences of one unique identifier. It works like deobfuscation in software engineering and is a more challenging task that requires the model to comprehend the code semantics based on the obfuscated code.
Objective (d): Bimodal Dual Generation (dual-gen) jointly optimizes the conversion from code to its comments and vice versa. It encourages a better alignment between the NL and PL counterparts.
Benchmarks
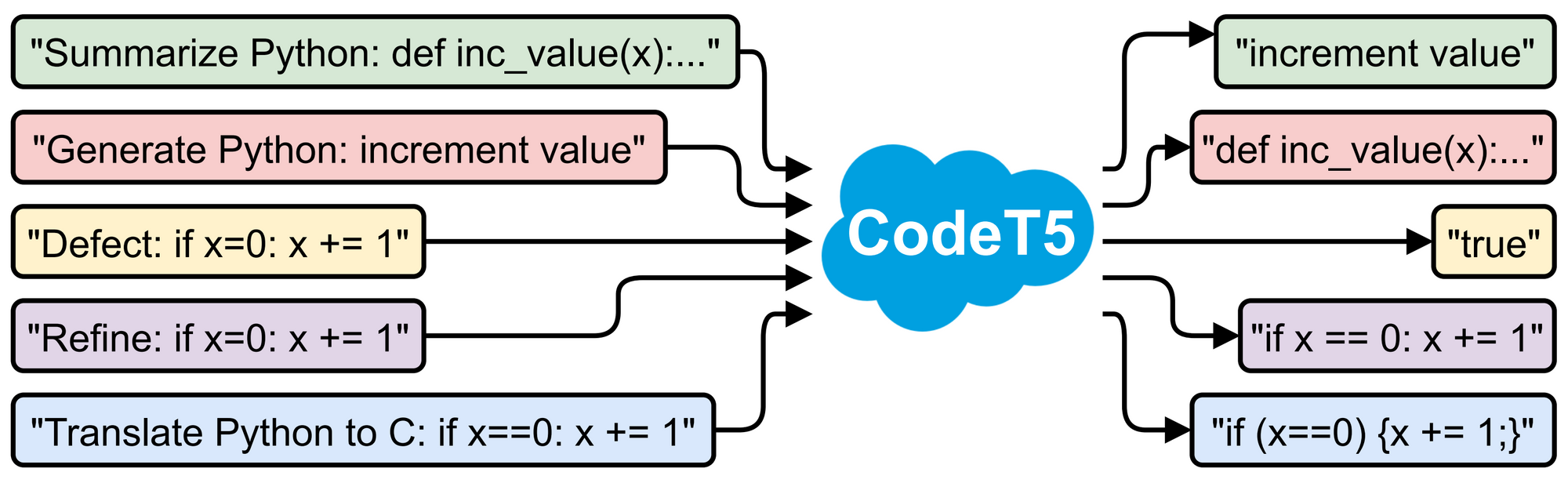
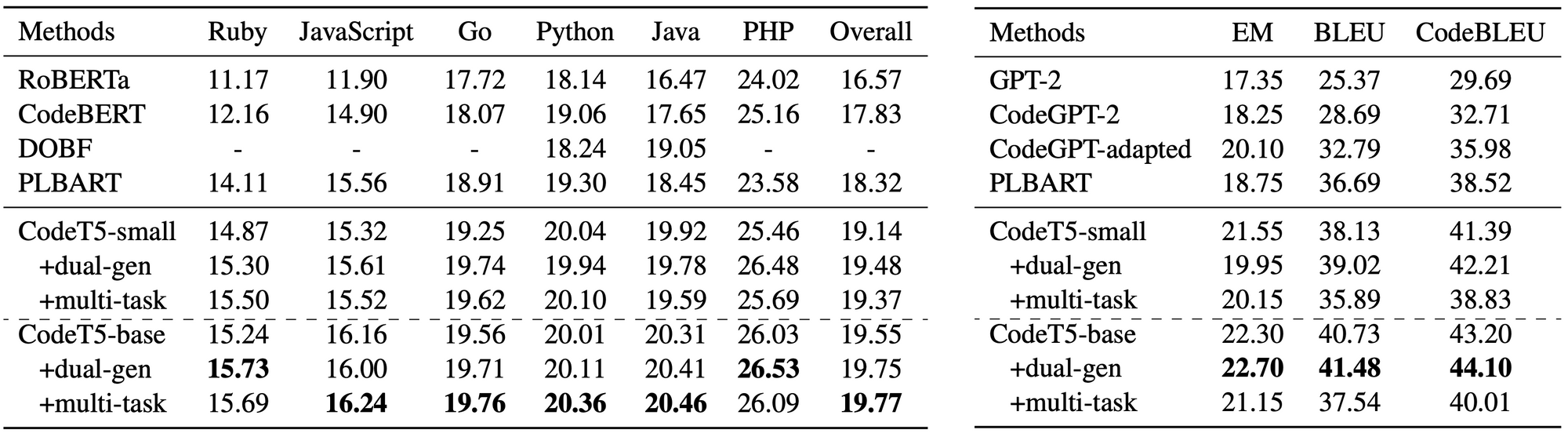
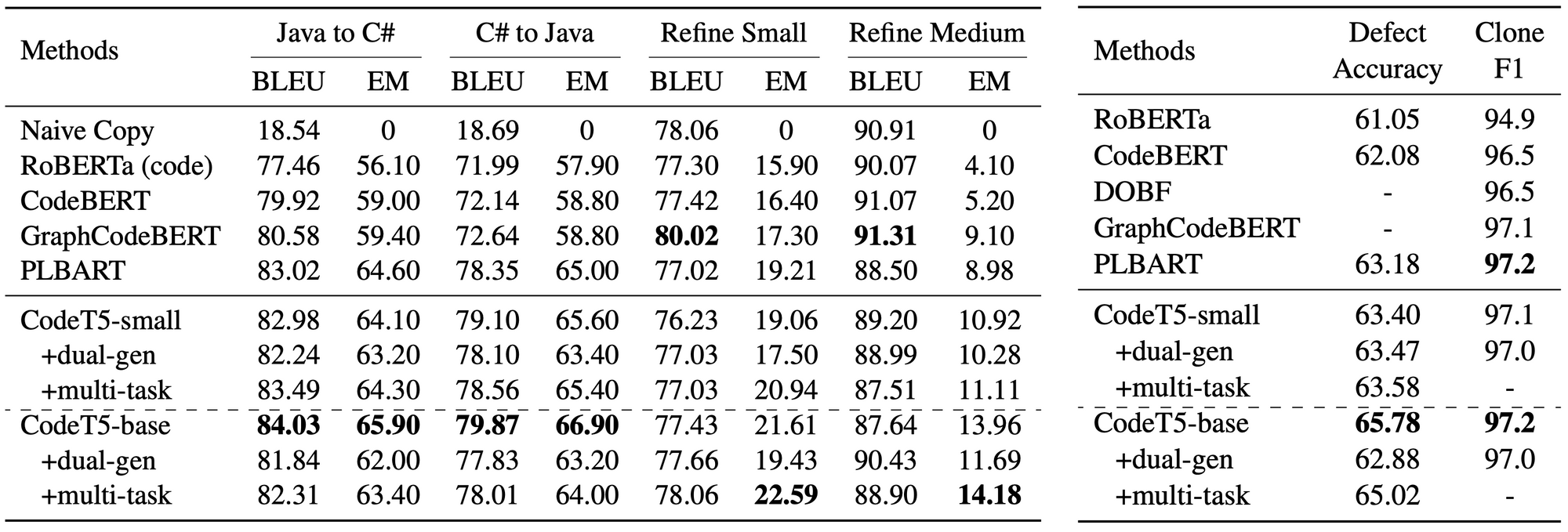
CodeT5 achieves state-of-the-art (SOTA) performance on fourteen subtasks in a code intelligence benchmark CodeXGLUE [3], as shown in the following tables. It significantly outperforms the previous SOTA model PLBART [4] on all generation tasks including code summarization, text-to-code generation, code-to-code translation, and code refinement. On understanding tasks, it yields better accuracy on defect detection and comparable results on clone detection. Besides, we observe that bimodal dual generation primarily boosts NL-PL tasks such as code summarization and text-to-code generation. Please check out our paper [1] for more details.
How Could CodeT5 Disrupt Software Development?
You might be wondering how pre-trained code intelligence models like CodeT5 could improve the developer productivity in real-world scenarios? At Salesforce, we can use CodeT5 to build an AI-powered coding assistant for Apex developers. Here we demonstrate an example of CodeT5 powered coding assistant with three code intelligence capabilities:
- Text-to-code generation: generate code based on the natural language description
- Code autocompletion: complete the whole function of code given the target function name
- Code summarization: generate the summary of a function in natural language description
For the first two functionalities, developers could simply type the natural language description or the function signature to specify their intents, and our AI coding assistant can generate or complete the target function for them. This helps to accelerate their implementation and also reduce their reliance on external resources. For code summarization, it can automatically summarize a function into code comments, which enables faster documentation and easier software maintenance.
Ethical Risks and Considerations
We discuss four ethical risks of our work in the following:
- Dataset bias: The training datasets in our study, including user-written comments, are source code from open-source Github repositories and publicly available. However, it is possible that these datasets would encode some stereotypes like race and gender from the text comments or the source code such as variables, functions, and class names. As such, social biases would be intrinsically embedded into the models trained on them. As suggested by [5], interventions such as filtration or modulation of generated outputs may help to mitigate these biases in code corpus.
- Computational cost: Our model pre-training requires non-trivial computational resources though we have tried our best to carefully design our experiments to save unnecessary computation costs. In addition, we experimented on Google Cloud Platform which purchases carbon credits to reduce its carbon footprint, e.g., training CodeT5-base produced around 49.25 kg CO2 which was totally offset by the provider. Furthermore, we open source and release our pre-trained models publicly to avoid repeated pre-training for the community.
- Automation bias: As CodeT5 can be deployed to provide coding assistance such as code generation for aiding developers, the automation bias of machine learning systems should be carefully considered, especially for developers who tend to over-rely on the model-generated outputs. Sometimes these systems might produce functions that superficially appear correct but do not actually align with the developer’s intents. If developers unintentionally adopt these incorrect code suggestions, it might cause them much longer time on debugging and even lead to some significant safety issues. We suggest practitioners using CodeT5 should always bear in mind that its generation outputs should be only taken as references that require further correctness and security checking.
- Security implications: Pre-trained models might encode some sensitive information (e.g., personal addresses) from the training data. Though we have conducted multi-rounds of data cleaning to mitigate this before training our models, it is still possible that some sensitive information cannot be completely removed. Besides, due to the non-deterministic nature of generation models, it might produce some vulnerable code to harmfully affect the software and even be able to benefit advanced malware development when deliberately misused.
About the Authors
Yue Wang is an applied scientist at Salesforce Research Asia, which he joined after earning his PhD in The Chinese University of Hong Kong (2020). His research focuses on deep learning applications in natural language processing and its intersections with programming language processing and computer vision.
Steven Hoi is the Managing Director of Salesforce Research Asia and oversees Salesforce’s AI research and development activities in APAC. His research interests include machine learning and a broad range of AI applications.
Acknowledgments
This blog is based on a research paper [1] authored by Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi. We thank Kathy Baxter for the ethical review. We thank Amal Thannuvelil Surendran for the help of the AI coding assistant. We thank Denise Perez for refining this post. We thank Michael Jones, Caiming Xiong, and Silvio Savarese for their support. We thank Akhilesh Deepak Gotmare, Amrita Saha, Junnan Li, and Chen Xing for valuable discussions.
Find Out More
- Check out our research paper.
- Check out our code and pre-trained models on Github.
- Contact us at wang.y@salesforce.com.
- Follow us on Twitter: @SalesforceResearch, @Salesforce.
- Check out www.einstein.ai and learn more about what Salesforce AI Research is working on!
References
- Yue Wang, Weishi Wang, Shafiq Joty and Steven C.H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. EMNLP 2021
- Feng et al. 2020. Codebert: A pre-trained model for programming and natural languages. Findings of EMNLP 2020.
- Lu et al. 2021. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation. CoRR abs/2102.04664.
- Ahmad et al. 2021. Unified pre-training for program understanding and generation. NAACL 2021.
- Chen et al. 2021. Evaluating large language models trained on code. CoRR, abs/2107.03374.