 Blog Home
Blog HomeCausalAI: Answering Causality Questions Using Observational Data
TLDR; We introduce the Salesforce CausalAI Library, an open source library for causal analysis of time series and tabular data. The Salesforce CausalAI Library aims to provide a one-stop solution to the various needs in causal analysis including handling different data types, data generation, multi-processing for speed-up, utilizing domain knowledge and providing a user-friendly code-free interface.
We continue to develop this library. Some of our future plans are to include support for heterogeneous data types (mixed continuous and discrete types), support for GPU based computing, more algorithms for causal discovery and inference, and support for latent variables.
What is the Salesforce CausalAI Library?
In many applications, it is important to find out whether one action/entity/feature causes another in a multivariable system. Think smoking causes cancer as a classic two variable example. Further, beyond simply finding cause and effect, users may also be interested in finding a numerical estimate of the change in value of a feature if its causal ancestors are intervened.
Salesforce CausalAI Library is an open-source library for answering such causality related questions using observational data. It supports tabular and time series data, of both discrete and continuous types, and includes algorithms that handle linear and non-linear causal relationships between variables, and uses multi-processing based parallelization for speed-up. It also includes a data generator capable of generating synthetic data with specified structural equation models, that helps users control the ground-truth causal process while investigating various algorithms. Finally, we provide a user interface (UI) that allows users to perform causal analysis on data without coding. The goal of this library is to provide a fast and flexible solution for a variety of problems in the domain of causality.
What Kind of Problems Can the CausalAI Library Solve?
Causal Discovery
In a nutshell, causal discovery can answer questions about which variable causes which variable in a multivariable system using observational data.
More concretely, causal discovery aims at finding the underlying directed causal graph from observational data, where the variables (or features) are treated as nodes in the graph, and the edges are unknown. An edge between two variables (say $A$ and $B$)-- $A \rightarrow B$, denotes $A$ causes $B$. Observational data is simply a set of observations recorded in the past without any interventions. Typically, finding causal relationships between variables would require performing interventions. But under certain assumptions, it is possible to extract the underlying causal relationships between variables from observational data as well.
Causal Inference
Causal inference involves finding a numerical estimate of intervening one set of variables, on another variable. This type of inference is fundamentally different from what machine learning models do when they predict one variable given another as input, which is based on correlation between the two variables found in the training data. In contrast, causal inference tries to estimate how a change in one variable propagates to the target variable while traversing the causal graph from the intervened variable to the target variable along the directed edges. This means that even if two or more variables are correlated, intervening one may not have any effect on another variable if there is no causal path between them.
Importance of Causal Analysis and Interventions
Interventions are fundamentally different from correlations. For instance, during summer, people are more likely to go swimming and therefore there might be cases of people drowning. Eating ice cream is another likely activity during summer. Both activities are less likely during the winter season. So people drowning and eating ice cream may exhibit some correlation. However, we know that eating ice cream does not cause a person to drown or vice versa.
On the other hand, exercising has been shown to lower cholesterol levels. Therefore, if the cholesterol level of a person is high, they can intervene and start exercising to lower their cholesterol level.
Thus interventions are actionable items that can be used to change future outcomes, as opposed to correlation based machine learning models, which are typically used for automation. Causal analysis tools help us discover which variables in a system can be intervened to achieve the desired outcome for a particular variable of interest.
A Real World Example
Suppose flight tickets are getting very expensive, and you want to find a possible macroeconomic action that can lower the prices. You start by trying to find what causes airfares to increase or decrease. You have access to the historical monthly prices of crude oil and the average monthly airfares in the United States. This data can be seen in the figure below.
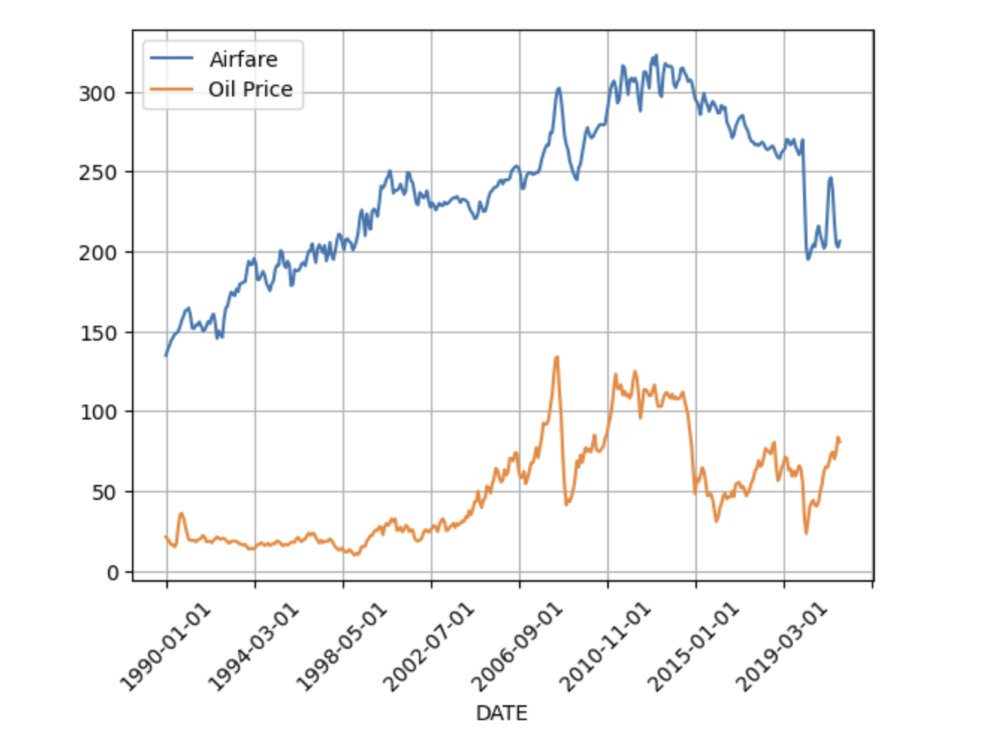
You want to find what will happen to airfares if crude oil prices go up, vs what will happen to crude oil prices if airfares go up. Note that we are not talking about correlations here. Rather, we are talking about performing an intervention on one variable and predicting its effect on the other, which is a more challenging task. Nonetheless, this specific problem is fairly intuitive, and one can predict based on common sense that if oil prices go up, it should increase the fuel cost for airline companies, which will make them raise their ticket prices. And on the other hand, if airlines decide to raise their prices independently of any change in oil prices, this raise should not impact oil prices. Therefore oil prices cause airfares but not vice versa. More broadly, using causal analysis on historical data, one can discover that an increase in oil prices will have a cascading effect on other commodity prices. Thus one possible macroeconomic remedy to reduce the rising costs of flight tickets, and possibly other commodities, is to increase the oil supply which will in turn bring down oil costs (due to the fundamental demand and supply dynamics), thus reducing prices.
The advantage of causal analysis is that it can automatically predict such relationships without “common sense”, simply based on historical data. This is specifically advantageous when we are dealing with a large multivariable system and there is a lack of a full prior knowledge about the system.
An Overview of the Salesforce CausalAI Library
Salesforce CausalAI Library aims at solving causal discovery and causal inference problems as described above. Below, we describe the library’s API pipeline, key features, supported algorithms, and a comparison of this library with existing libraries.
API Pipeline
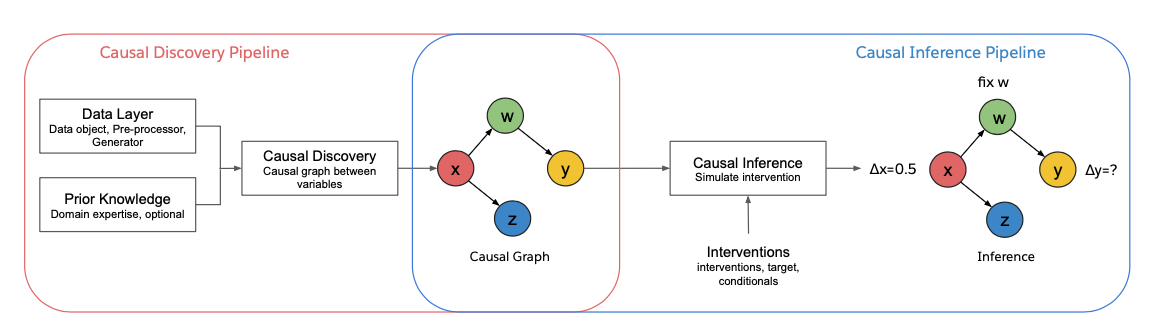
The figure above shows the CausalAI Library Pipeline. We support causal discovery and causal inference. The causal discovery module takes as input a data object (containing observational data) and a prior knowledge object (containing any expert partial prior knowledge, which is optional), and outputs a causal graph. The causal inference module takes a causal graph as input (which could be directly provided by the user or estimated using the causal discovery module) along with the user specified interventions, and outputs the estimated effect on the specified target variable.
Key Features
Some of the key features of our library are as follows:
- Data: Causal analysis on tabular and time series data, of both discrete and continuous types.
- Missing Values: Support for handling missing/NaN values in data.
- Data Generator: A synthetic data generator that uses a specified structural equation model (SEM) for generating tabular and time series data. This can be used for evaluating and comparing different causal discovery algorithms since the ground truth values are known.
- Distributed Computing: Use of multi-processing using the Ray library for parallelization, that can be optionally turned on by the user when dealing with large datasets or number of variables for faster computation. It can provide ~5x speed-up depending on the size of the data (number of variables and number of samples).
- Targeted Causal Discovery: In certain cases, we support targeted causal discovery, in which the user is only interested in discovering the causal parents of a specific variable of interest instead of the entire causal graph. This option reduces computational overhead.
- Visualization: Visualize tabular and time series causal graphs.
- Domain Knowledge: Incorporate any user provided partial prior knowledge about the causal graph in the causal discovery process.
- Code-free UI: Provide a code-free user interface in which users may directly load their data and perform their desired choice of causal analysis algorithm at the click of a button.
Algorithms
Currently, we support the PC algorithm, Granger causality and VARLINGAM for time series causal discovery, and the PC algorithm for tabular causal discovery. For causal inference, we currently learn conditional models based on the causal graph to simulate the data generating process for estimating the counterfactuals given intervention.
We plan to add more algorithms to the library for both causal discovery and causal inference to our library in future versions.
Comparison with Existing Libraries

The table above shows a comparison of some key capabilities offered by our library versus existing libraries. The key differentiating features of our library are parallelization and an easy-to-use user interface, that are aimed at making causal analysis more scalable and user friendly.
Explore More
Salesforce AI invites you to dive deeper into the concepts discussed in this blog post (links below). Connect with us on social media and our mailing list to get regular updates on this and other research projects.
Paper: Learn more about Salesforce CausalAI Library by reading our research paper.
GitHub: Check out our code and pre-trained models here.
Tutorials and Example Code: For example code and an introduction to Salesforce CausalAI Library, see the Jupyter notebooks in examples, and the guided walkthrough here https://github.com/salesforce/causalai/tree/main/tutorials and https://opensource.salesforce.com/causalai .
Documentation: See detailed API documentation (including the example code) here. https://opensource.salesforce.com/causalai
Salesforce CausalAI Library project page: https://github.com/salesforce/causalai/
Feedback/Questions? Contact Juan Carlos Niebles at jniebles@salesforce.com.
Follow us on social: @SFResearch (Twitter page for Salesforce AI), @Salesforce (company Twitter page)
Other AI projects: Learn more about all the projects we’re working on at salesforceairesearch.com
About the Authors
Devansh Arpit is a Senior Research Scientist at Salesforce AI. He earned his Ph.D. degree in Computer Science from University at Buffalo. At Salesforce, he works at the intersection of optimization and generalization in deep learning, domain generalization, time series analytics, and causal analysis. Prior to joining Salesforce, he was a postdoctoral fellow at Mila under Prof. Yoshua Bengio.
Juan Carlos Niebles received an Engineering degree in Electronics from Universidad del Norte (Colombia) in 2002, an M.Sc. degree in Electrical and Computer Engineering from University of Illinois at Urbana-Champaign in 2007, and a Ph.D. degree in Electrical Engineering from Princeton University in 2011. He is Research Director at Salesforce and Adjunct Professor of Computer Science at Stanford since 2021. He is co-Director of the Stanford Vision and Learning Lab.
Acknowledgments
Here is the full list of authors: Devansh Arpit, Matthew Fernandez, Chenghao Liu, Weiran Yao, Wenzhuo Yang, Paul Josel, Shelby Heinecke, Eric Hu, Huan Wang, Stephen Hoi, Caiming Xiong, Kun Zhang, Juan Carlos Niebles.
We would like to thank Matthew Fernandez, Paul Josel and Eric Hu for UI design.
We would also like to thank Denise Perez and Tessa Faubion for their help in setting up the webpage, UX designs.