 Blog Home
Blog HomeCASTing Your Model: Learning to Localize Improves Self-Supervised Representations

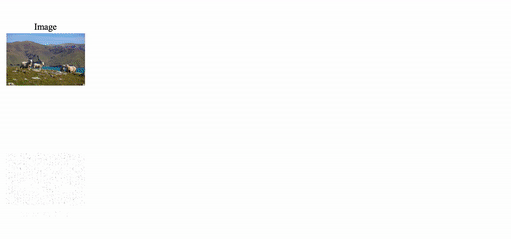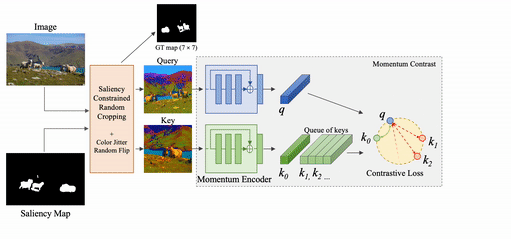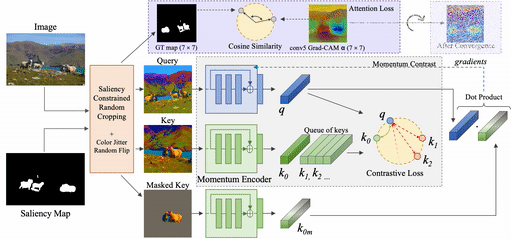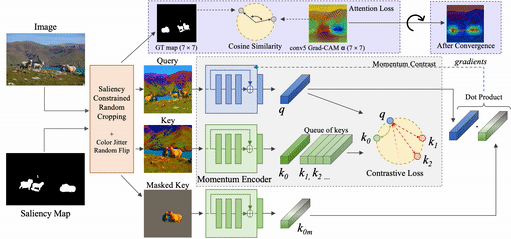
TL; DR: We find that current self-supervised learning approaches suffer from poor visual grounding and receive improper supervisory signal when trained on complex scene images. We introduce CAST to improve visual grounding during pretraining and show that it yields significantly better transferable features.
Self-supervised learning and its grounding problem
Self-Supervised Learning in computer vision aims to learn feature representations without using any human annotations, which can be utilized by downstream tasks such as supervised image classification, object detection, and semantic segmentation. Recent advances in SSL methods based on contrastive learning have begun to match or even outperform supervised pretraining on several downstream tasks. Despite their success these methods have been primarily applied to unlabeled ImageNet images, and show marginal gains when trained on larger sets of uncurated images [1].
We find that contrastive SSL methods have poor visual grounding and receive poor supervisory signal when trained on scene images. These issues may arise from the practice of training the instance discrimination task with random views from images. This task, by design does not encourage semantic understanding, and models often cheat by exploiting low-level visual cues or spurious background correlations.
These issues can be seen in the examples below.




Introducing our new approach, CAST
To mitigate these limitations, we propose Contrastive Attention-Supervised Tuning (CAST), a training method to improve the visual grounding ability of contrastive SSL methods by making them rely on appropriate regions during contrastive pretraining. CAST consists of two algorithmic components: (a) an intelligent geometric transform for cropping different views from an input image, based on constraints derived from an unsupervised saliency map, and (b) a Grad-CAM-based [2] attention loss that provides explicit grounding supervision by forcing the model to attend to objects that are common across the crops.
To fix the problem of models receiving inconsistent query-key crops, we design a random crop transform called Saliency-constrained Random Cropping, that generates input crops constrained to overlap with a saliency map -- binary mask containing objects and other important visual concepts present in the image. We obtain these saliency maps from an unsupervised approach, Deep-USPS [4].
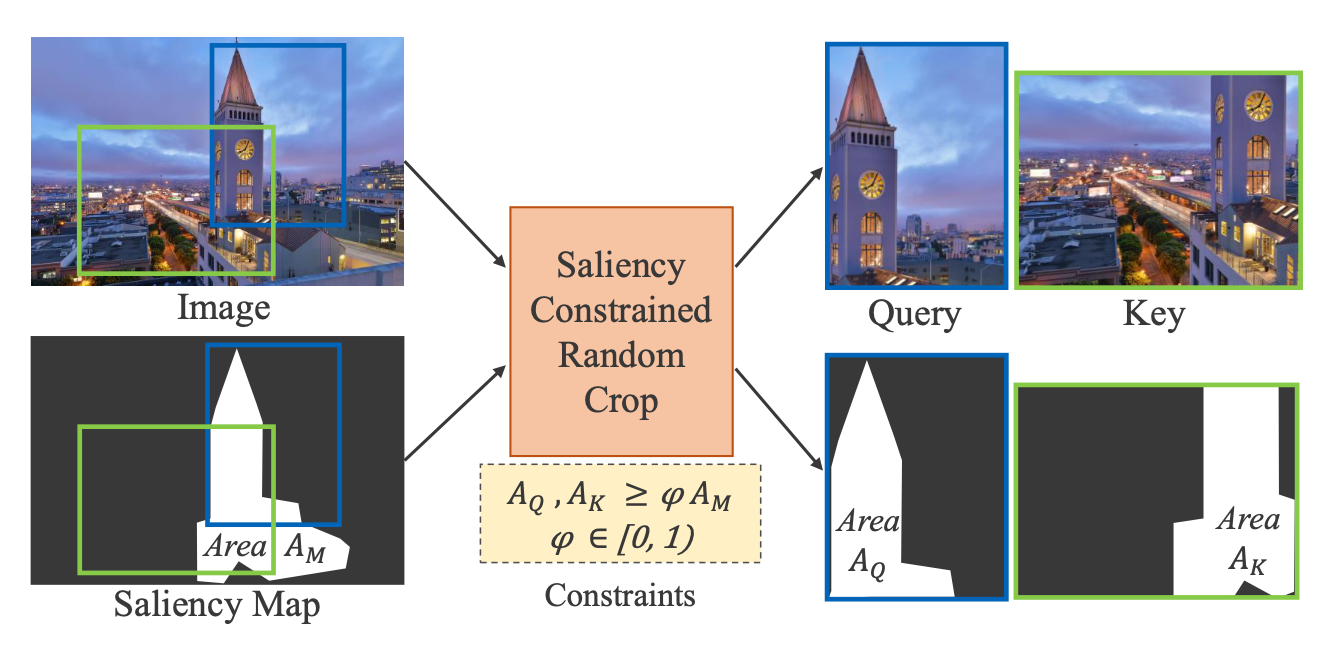

How do you CAST your model?
The premise of our approach, CAST, is that when contrastive models such as MoCo [3] are given multiple crops from an image, focusing on the salient (object) regions in the crops would make them learn representations that are more generalizable. These models are likely to be more grounded, and are thus less likely to learn unwanted biases. CAST introduces a grounding loss that encourages this behaviour.
At a high level, CAST consists of two steps: 1. constrained sampling of the query and key crops from the original image based on constraints generated using an image saliency map, 2. contrastive learning with a loss that forces models to look at the relevant object regions that are common between the query and key crops through Grad-CAM supervision.
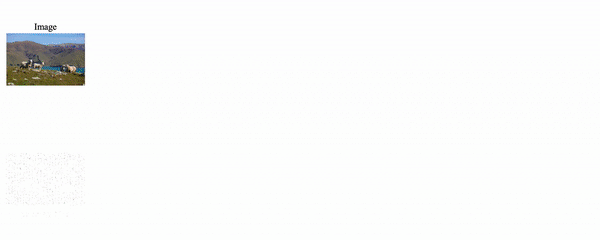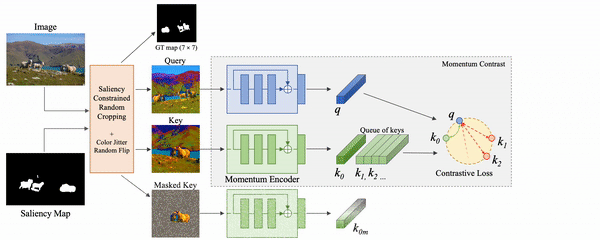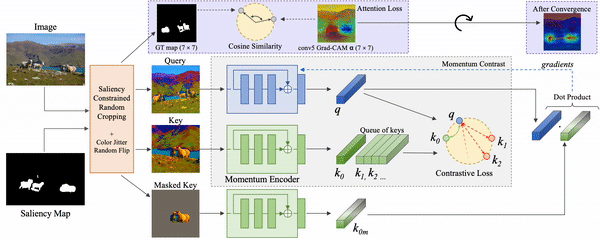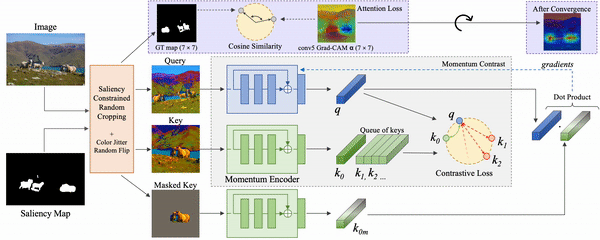

CAST is generic and can be applied on top of any contrastive self-supervised approach.
CAST yields significantly better transferable features
We will first evaluate the quality of the learned features from CAST pretraining by transferring them to 4 standard downstream tasks, namely VOC’07 linear classification, Imagenet linear classification, VOC detection and COCO instance Segmentation.

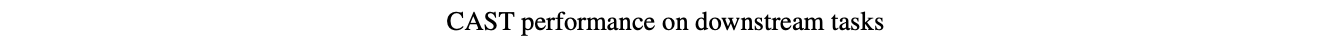
As can be seen above, MoCo+CAST outperforms MoCo on all downstream tasks. The performance improvement is especially large on the VOC detection task, aided by the improved visual grounding in models trained with CAST. We also find that our unsupervised saliency-constrained cropping alone outperforms MoCo on VOC’07 and VOC-Detection, and gets close to MoCo performance on Imagenet-1k and COCO instance segmentation tasks.
CAST improves visual grounding during pretraining and downstream tasks
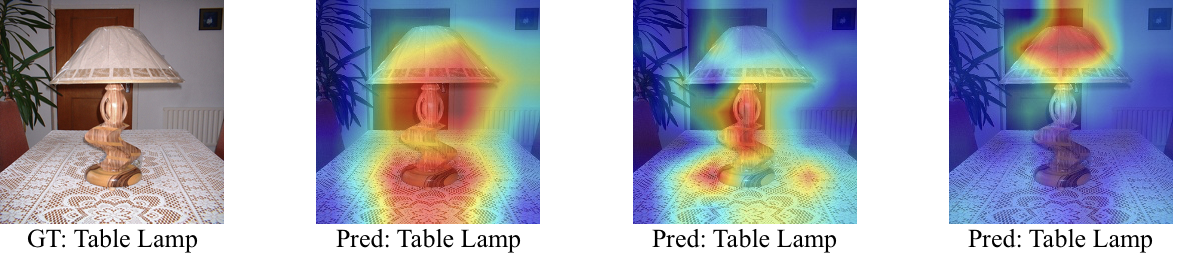
We use Grad-CAM to show the improved grounding ability of contrastive SSL models trained with CAST during the self-supervised task and how it translates to improved grounding in downstream tasks.

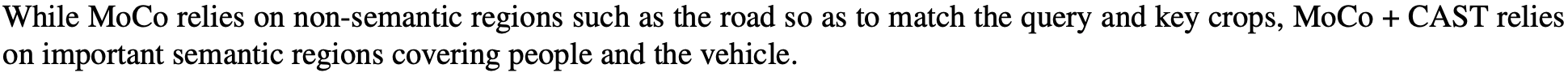


CAST pretraining also improves robustness of downstream models
We also evaluate CAST using the Backgrounds Challenge dataset [5], a 9-class image classification dataset designed to evaluate the robustness of models on varying backgrounds. It measures the accuracy of Imagenet trained models on images containing foreground objects superimposed on various background types. Since CAST forces a model to attend to salient objects during training – reducing model dependence on background correlations – CAST-trained model significantly outperforms MoCo on the Backgrounds Challenge [5].




What's next?
We have demonstrated the power of making models rely on appropriate regions when making decisions. We hope that our method leads to development of interpretable general-purpose and robust self-supervised methods that learn from noisy, unconstrained, real-world image data from the web.
This research is joint work with Karan Desai and Justin Johnson at University of Michigan and Nikhil Naik at Salesforce Research. If you’re interested in learning more about CAST, please refer to our arxiv preprint, and feel free to contact us at rselvaraju@salesforce.com.
References:
[1]. Ishan Misra, Laurens van der Maaten. Self-supervised learning of pretext-invariant representations. In CVPR, 2020.
[2]. Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra. Grad-CAM: Visual Explanation from Deep Networks via Gradient-based Localization. In ICCV, 2017.
[3]. Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, 2020.
[4]. Duc Tam Nguyen, Maximilian Dax, Chaithanya Kumar Mummadi, Thi Phuong Nhung Ngo, Thi Hoai Phuong Nguyen, Zhongyu Lou, Thomas Brox. DeepUSPS: Deep Robust Unsupervised Saliency Prediction With Self-Supervision. In NeurIPS, 2019.
[5]. Kai Xiao, Logan Engstrom, Andrew Ilyas, Aleksander Madry. Noise or signal: The role of image backgrounds in object recognition. In ArXiv preprint arXiv:2006.09994.