 Blog Home
Blog HomeBootPIG: Bootstrapping Zero-shot Personalized Image Generation Capabilities in Pretrained Diffusion Models

TL;DR: We present a novel architecture, BootPIG, that enables personalized image generation without any test-time finetuning.
Full Paper: https://arxiv.org/abs/2401.13974
Background
Text-to-image models, such as DALLE-3[1], Midjourney[2], and StableDiffusion[3], have become a powerful means of creating high-quality images. But what if you wanted to create a new image centered around your pet dog? Or if you were a sneaker company that wants to generate high quality images featuring your newest sneaker? Since these models rely only on textual input for control, they won’t know the specific features of your subject and, thus, will fail to accurately render your dog or sneaker. However, this problem of subject-driven generation, i.e., generating an image containing a desired subject like your dog or sneaker, is an important and powerful application of text-to-image models. Concretely, subject-driven generation enables users and businesses to quickly and easily generate images containing a specific animal, product, etc., which can be used for fun or to create advertisements.
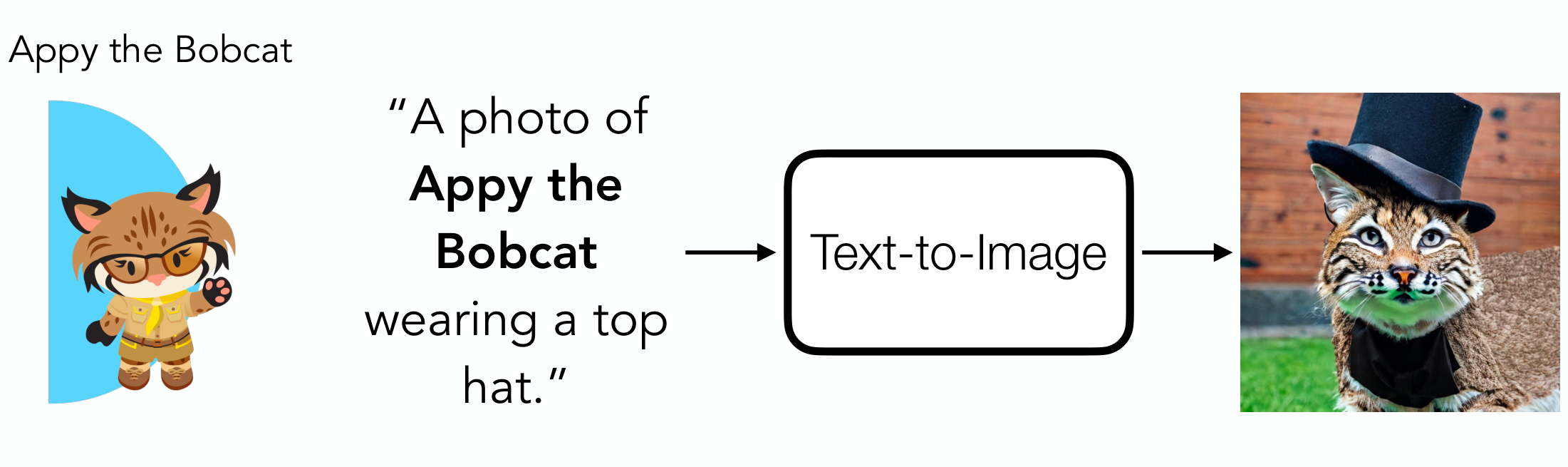
To tackle this problem, many methods, such as DreamBooth4, use test-time finetuning which updates the text-to-image model to learn your target subject. These methods are time-consuming and must be re-trained for each new subject. Recently, works such as BLIP-Diffusion5 have tried to mitigate these problems by enabling zero-shot subject-driven generation, where a user can provide an image (or multiple) of their target subject and novel scenes containing the subject can be generated without training the model to specifically learn your subject. Unfortunately, zero-shot subject-driven generation methods fall short of the performance of test-time finetuned approaches like DreamBooth. To close this gap, we present BootPIG an architecture that enables state-of-the-art subject-driven generation without any time-consuming finetuning.
Problem
What is zero-shot subject-driven generation? In simple terms, it means creating new scenes containing a target subject (e.g., your dog or cat) without training the image generation model specifically for the subject. In this work, we present an architecture and pretraining method that equips powerful text-to-image models with the ability to personalize images according to a specific subject, without any finetuning.
Method: BootPIG
We now describe: (1) the BootPIG architecture and (2) a training pipeline that enables BootPIG to perform zero-shot subject driven generation. The BootPIG architecture builds upon pretrained text-to-image models and introduces new layers to allow for the pretrained model to accept images of the subject at test-time. The training process trains these new layers and thus enables the BootPIG model to generate images of the desired subject without any specific finetuning. On top of that, BootPIG’s training process does not require real images featuring the object and only takes about an hour!
Architecture: The BootPIG architecture shares similarities with the ControlNet6 architecture. Specifically, we introduce a copy of the original text-to-image architecture, which we call the Reference U-Net. The Reference U-Net takes as input reference images, e.g., images of your dog or cat, and learns features that enables the original text-to-image architecture, which we call the Base U-Net, to synthesize the subject in the desired scene. Additionally, we add Reference Self-Attention (RSA) operators in place of the Self-Attention layers in the Base U-Net. The RSA operator performs the Attention operation between the Base U-Net features (query) and the concatenation of Base U-Net features and Reference U-Net features (keys, values). During training, the Base U-Net and Reference U-Net are trained jointly. All parameters in the Reference U-Net are updated, while only the RSA layers in the Base U-Net are trained.
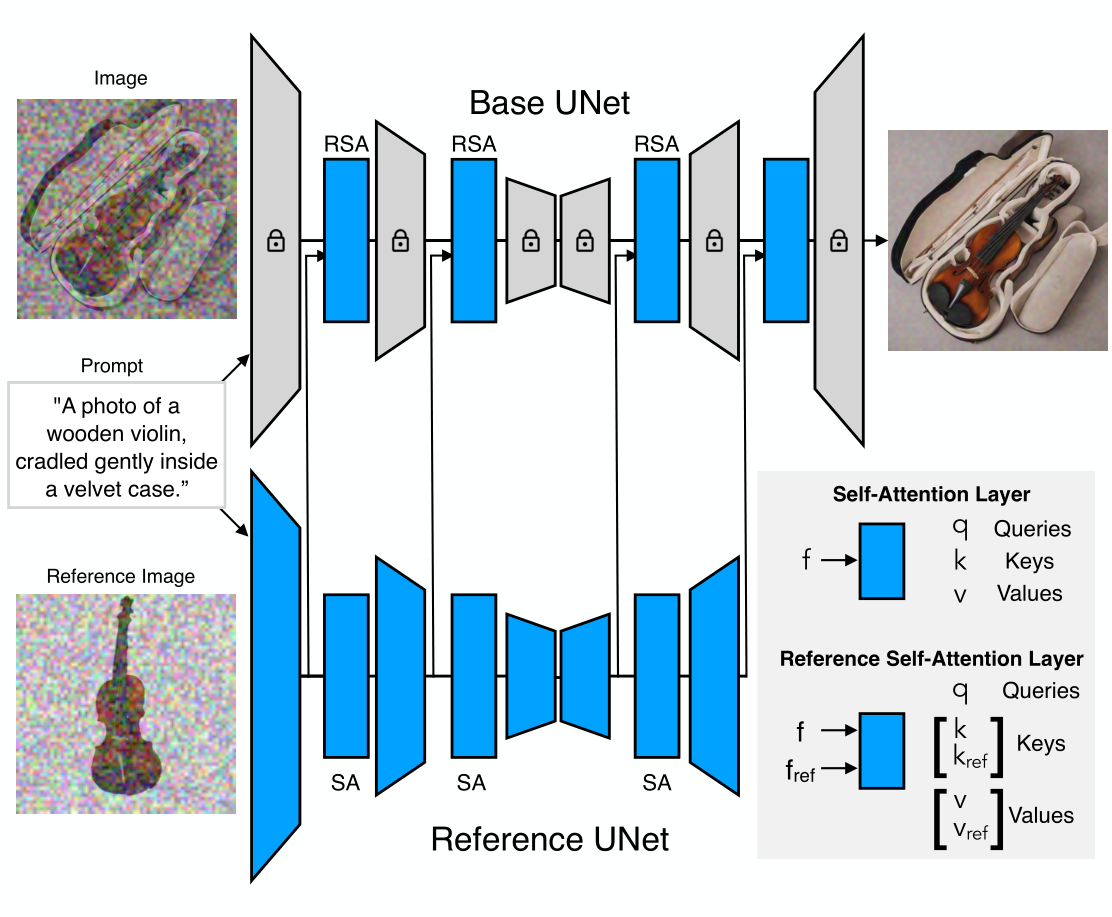
Data: BootPIG is trained entirely using synthetic data. During training, BootPIG requires triplets of the form, (image, caption, reference image). First, we use ChatGPT7 to generate captions for potential images. Next, we use StableDiffusion to generate images for each of these captions. Lastly, we use Segment Anything8, a state-of-the-art segmentation model, to segment the subject in each image and we use this segmented portion of the image as the reference image.
Results
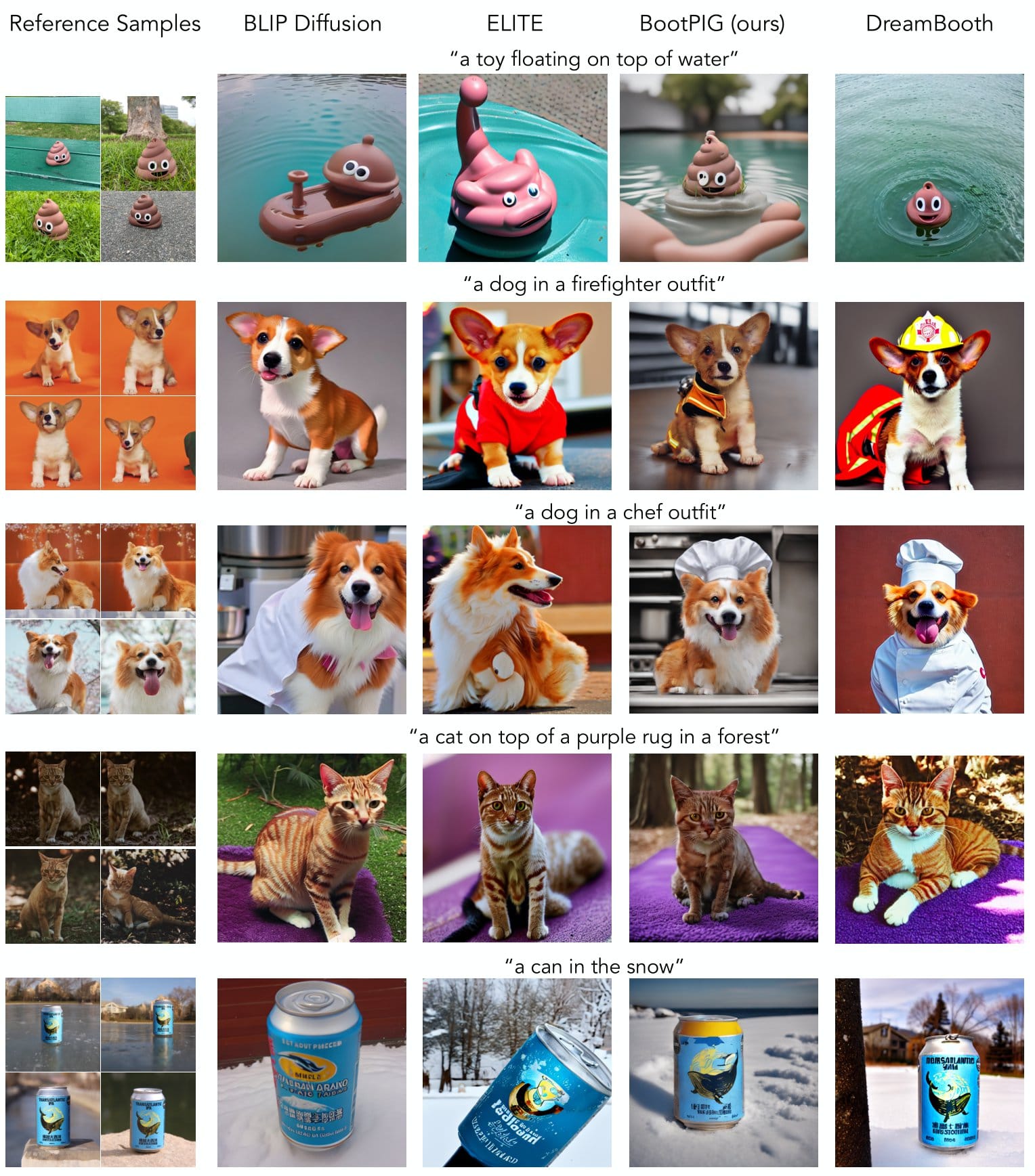
BootPIG demonstrates state-of-the-art quantitative results in zero-shot subject-driven generation. We present qualitative (visual) comparisons to existing zero-shot and test-time finetuned methods below. As seen in the figure, BootPIG is able to maintain key features of the subjects, such as the fur markings of the dog in the 3rd row, in the new scene.
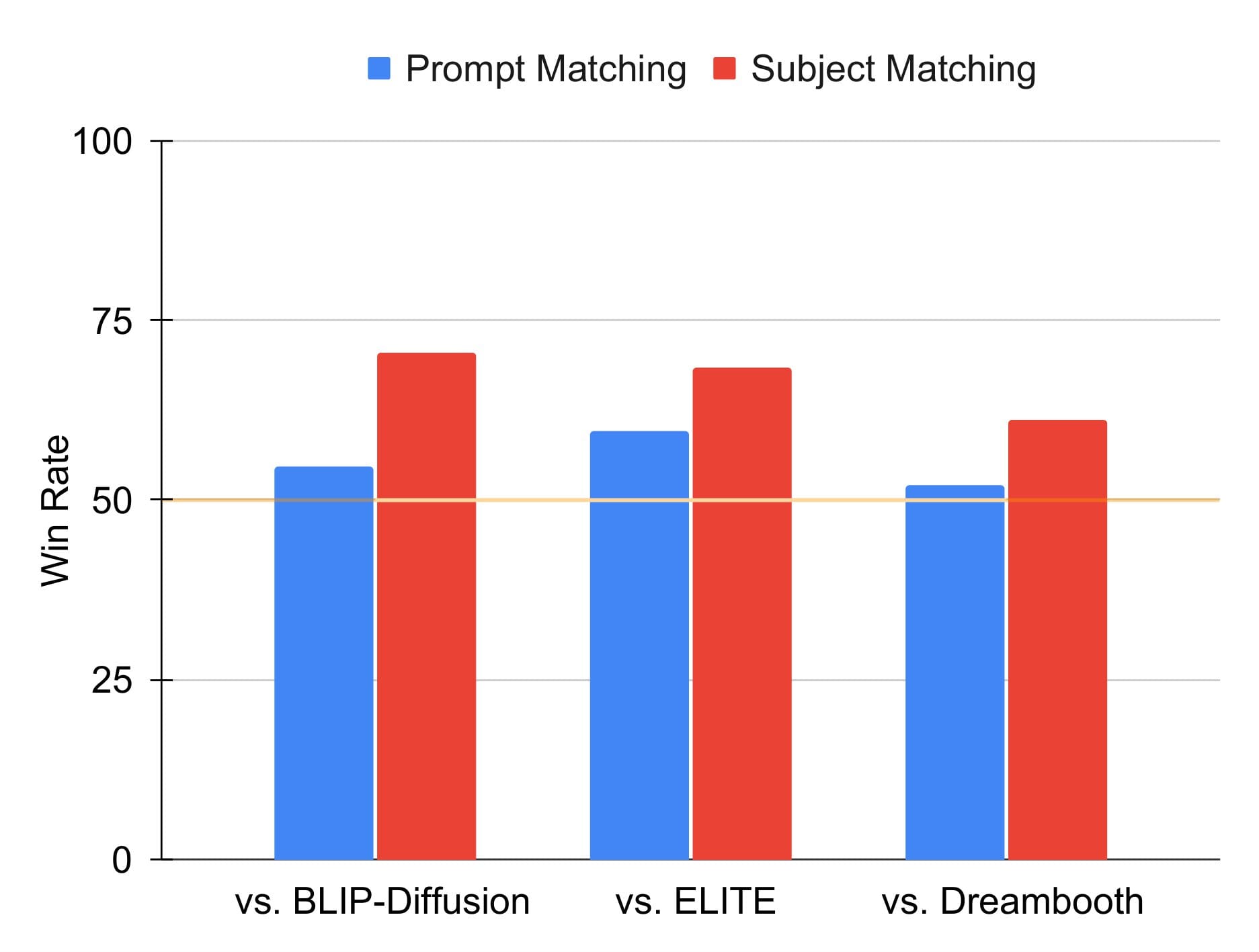
We further find that human evaluators prefer BootPIG over existing subject-driven generation methods. Here, we conduct two studies per comparison— one evaluating which method generates an image that best matches the prompt (prompt matching), and another evaluating which method generates an image that maintains the key features of the subject (subject matching).
Impact and Ethical Considerations
The ability to personalize images according to a subject opens up many avenues for applications. From creating marketing images with your product to inpainting your pet into a family photo, the possibilities of personalized generation are endless. On top of that, being able to generate these images without having to wait through the finetuning process, means that these applications are only a few keystrokes away.
While BootPIG enables many exciting applications, it is important to be mindful of the limitations of text-to-image models. Text-to-image models reflect the biases captured in their training data. As a result, harmful stereotypes and inappropriate content may be generated9. Additionally, subject-driven generation introduces the risk of misinformation. BootPIG relies on pretrained text-to-image models and thus may perpetuate these biases.
Conclusion and Future Directions
BootPIG allows users to generate any image with their desired subject while avoiding the hassle of finetuning the text-to-image model at inference. BootPIG pre-trains a general subject encoder, which can handle multiple reference images, using only synthetic data. The entire training process takes approximately 1 hour. Future work could explore the use of BootPIG for subject-driven inpainting or look to introduce additional visual controls (e.g., depth maps) into the model.
Additional Details
Checkout the full paper and other experiments at: https://arxiv.org/abs/2401.13974
Stay tuned for the release of the code and models.
Citations
- Betker, James, et al. "Improving image generation with better captions." https://cdn.openai.com/papers/dall-e-3.pdf.
- Midjourney. https://www.midjourney.com/home/.
- Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
- Ruiz, Nataniel, et al. "Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023.
- Li, Dongxu, Junnan Li, and Steven CH Hoi. "Blip-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing." arXiv preprint arXiv:2305.14720 (2023).
- Zhang, Lvmin, Anyi Rao, and Maneesh Agrawala. "Adding conditional control to text-to-image diffusion models." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
- ChatGPT. https://chat.openai.com/.
- Kirillov, Alexander, et al. "Segment anything." arXiv preprint arXiv:2304.02643 (2023).
- Bianchi, Federico, et al. "Easily accessible text-to-image generation amplifies demographic stereotypes at large scale." Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency. 2023.
About the Authors
Senthil Purushwalkam is a Research Scientist at Salesforce AI. His research interests lie in Computer Vision and NLP.
Akash Gokul is an AI Resident at Salesforce Research. He is currently working on improving multimodal generative models.
Shafiq Rayhan Joty is Research Director at Salesforce Research AI, where he directs the NLP group's work on large language modeling (LLM) and generative AI. His research interests are in LLMs, multi-modal NLP and robust NLP.
Nikhil Naik is a Principal Researcher at Salesforce AI. His research interests are in computer vision, natural language processing, and their applications in sciences. His current work focuses on generative modeling and multimodal representation learning.