 Blog Home
Blog HomeBannerGen: A Library for Multi-Modality Banner Generation
Background
Graphic layout designs serve as the foundation of communication between media designers and their target audience. They play a pivotal role in organizing various visual elements, including rendered text, logos, product images, calls to action (such as buttons), and background textures/images. The arrangement of these elements is the linchpin for creating appealing advertisements, webpages, posters, and more. Expertly crafted layouts have the power to captivate viewers, emphasize critical information, and enhance the overall visual appeal of the media.
Motivation
The goal of this project is to streamline the workflow for graphic designers. When creating a graphical layout, such as an ad banner, designers typically begin by selecting an appropriate background image. They then brand the ad by incorporating elements like the company logo, custom fonts, buttons, taglines, and composing ad text in various categories like headers, body content, and disclaimers (see Fig. 1). Finally, they meticulously fine-tune the alignment of these visual components, all while carefully choosing the right color palette. This process demands the expertise of experienced designers and is not easily scalable for mass and diverse production needs.
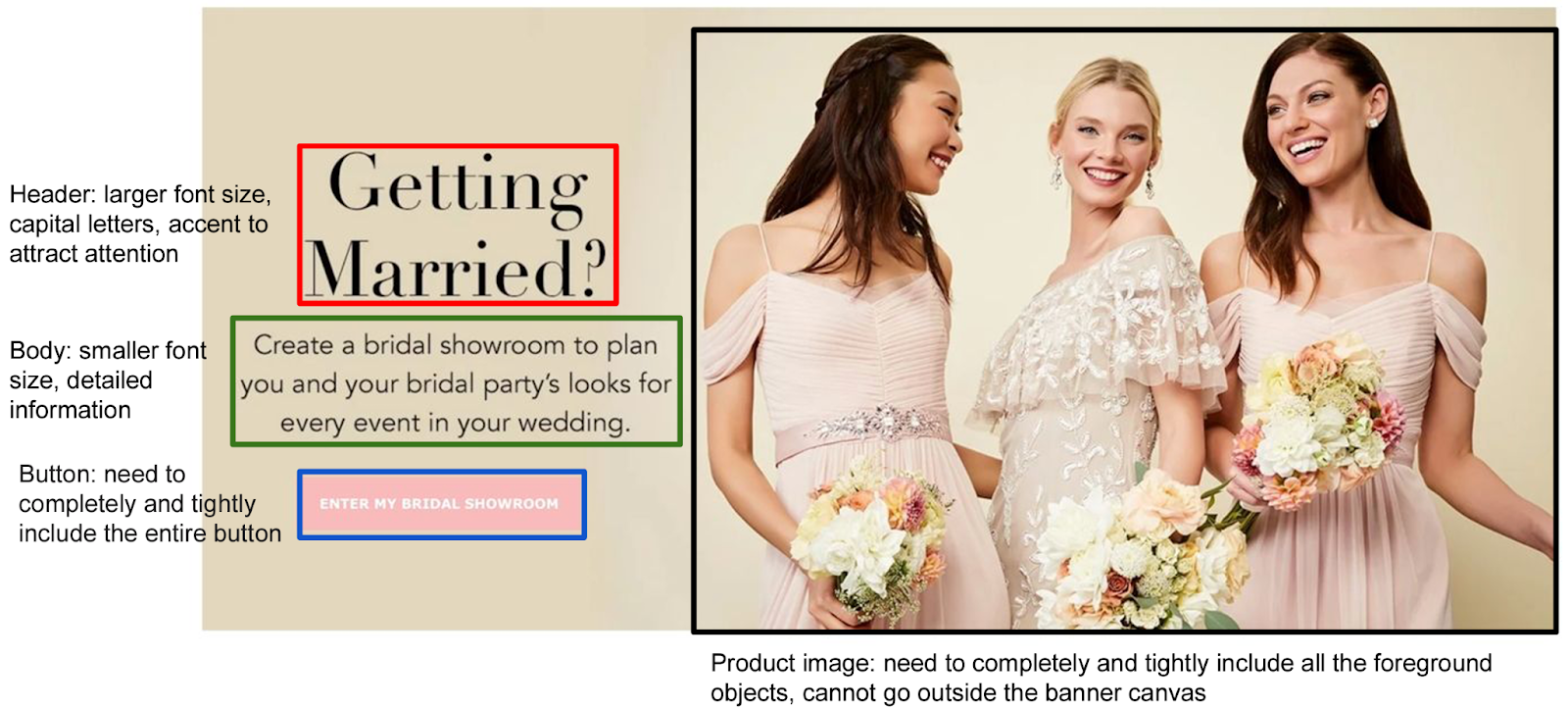
Our approach aims to alleviate the time-consuming, layer-by-layer assembly work by harnessing the power of multiple generative AI techniques. These models have been trained on a large scale of professionally designed graphical data, allowing us to consider the background canvas and significantly expedite the design process.
BannerGen
System design
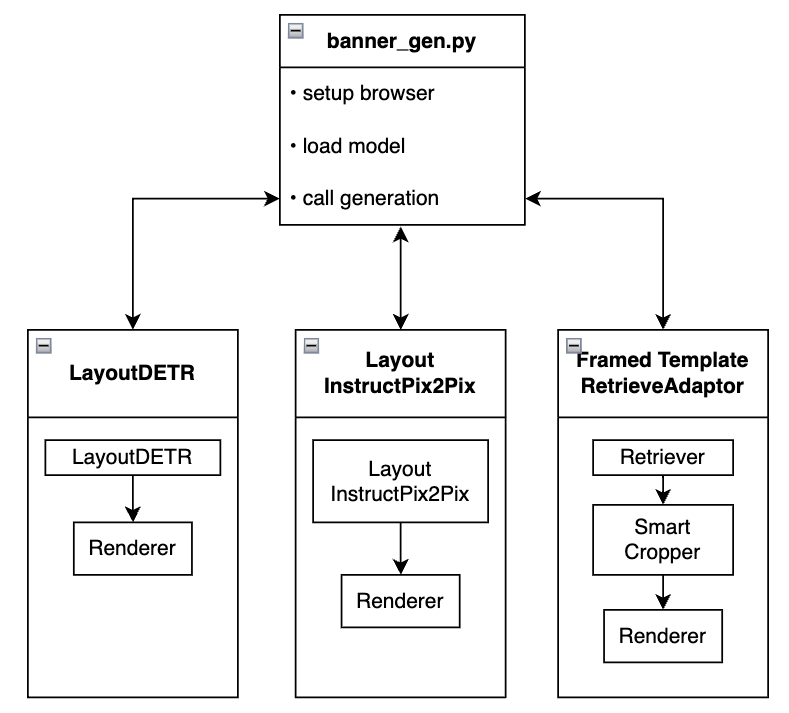
In order to inspire the users’ creativity by providing a variety of design ideas, our system comprises three distinct banner generation methods in parallel: LayoutDETR, LayoutInstructPix2Pix, and Framed Template RetrieveAdapter.
We open sourced all the three banner generation models and implementation in our BannerGen GitHub repository. These banner generation methods have been designed as importable Python modules. Our open-source project empowers researchers and developers to swiftly engage in experimentation with each individual method. Furthermore, by incorporating licensed fonts and an expanded collection of carefully crafted framed templates, developers can effortlessly harness our open-source modules to build a high-quality, professional-grade banner design assistance tool.
In particular, our BannerGen open-source library is structured in Fig. 2, with each module being introduced in the subsequent sections.
LayoutDETR-based layout generation [arXiv]
When designing the layout generator, we have three key criteria in mind:
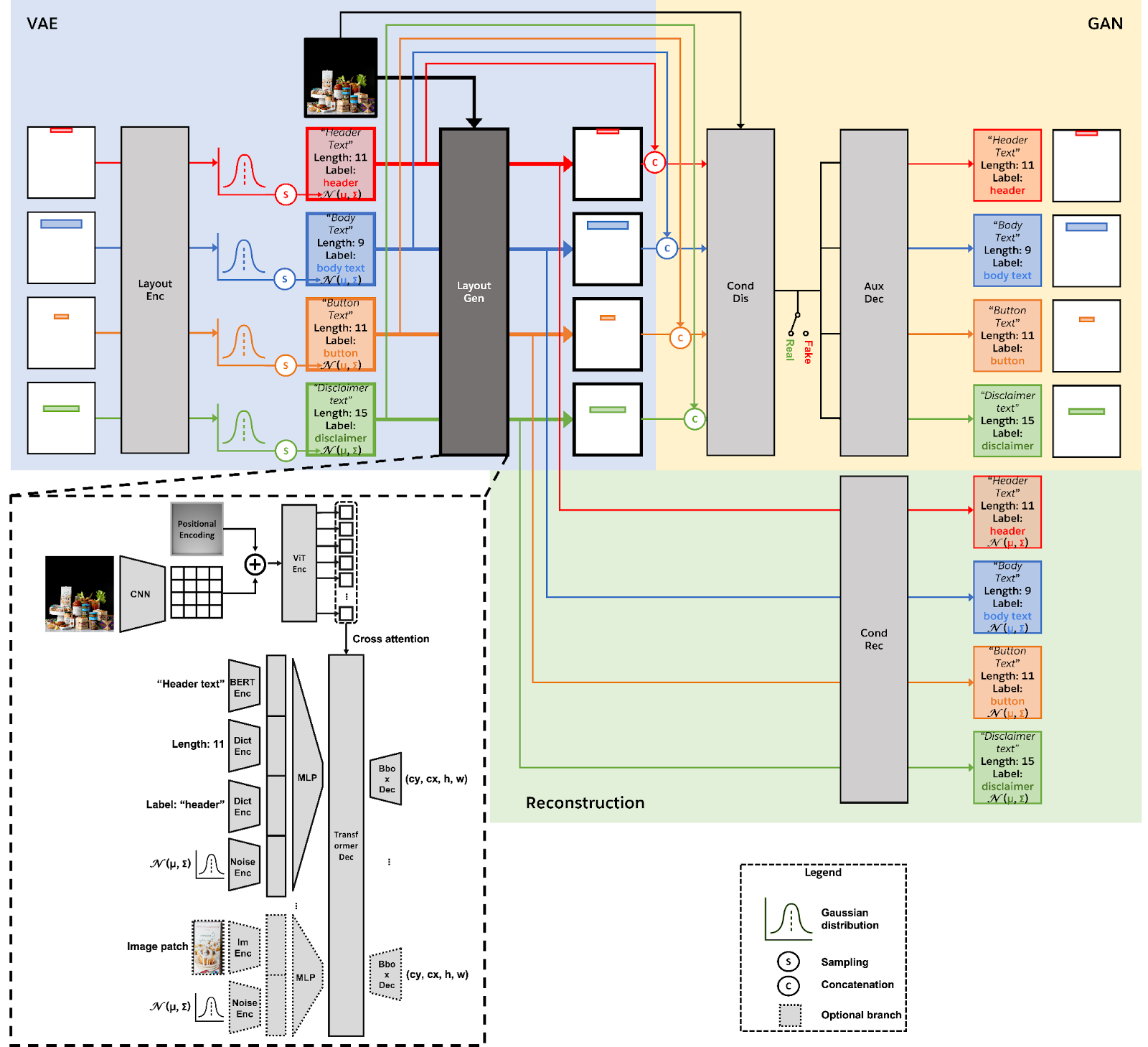
Criterion #1: Learning from real layouts. Our primary objective is to learn and generate layouts that align with the patterns found in real-world distributions. To achieve this, we have integrated the VAEGAN framework into our approach. In this framework, the generator (Fig. 3, blue) takes multimodal background and foreground elements as inputs and produces bounding box parameters for each foreground element. An encoder (Fig. 3, blue) precedes the generator, while a discriminator (Fig. 3, yellow) follows it. Both the encoder and discriminator receive the set of bounding boxes as input. The encoder generates latent embeddings for each bounding box, while the discriminator produces binary classification logits to differentiate between real and fake layouts. Additionally, we have included an auxiliary decoder (Fig. 3, yellow) after the discriminator and an auxiliary reconstructor (Fig. 3, green) after the generator to ensure that the outputs of the discriminator and generator are fully conditioned on their input elements without any shortcuts. During training, we jointly train the encoder, generator, and its auxiliary reconstructor to encode and reconstruct real layouts. In the meanwhile, we adversarially train the discriminator and its auxiliary decoder to classify layouts as either real or fake. During inference, only the generator is retained, and we sample from the latent space to generate layouts.
Criterion #2: Understanding the background. To achieve this, we have drawn inspiration from object detection principles and incorporated the DETR architecture into our framework. Hence, we refer to our method as LayoutDETR. Specifically, we encode background images using Vision Transformers (ViT) and employ these embeddings for cross-attention with the layout generator, leveraging the decoder from the DETR implementation (see Fig. 3, bottom left).
Criterion #3: Understanding foreground elements. To achieve this, we have modified the DETR decoder to handle multimodal foreground inputs. Text elements, in particular, are characterized by their content, length, and text category. These categories, defined by professional marketers, encompass ad header texts, body texts, disclaimer texts, button texts, and more (see Fig. 3, bottom left). For each foreground element, we encode each attribute separately and concatenate their embeddings as the query input to the generator transformers.
LayoutInstructPix2Pix-based layout generation

In addition to LayoutDETR, the BannerGen system incorporates a complementary layout generator that aligns with the emerging instructional image-to-image editing technique known as InstructPix2Pix, which is powered by diffusion models. The rationale behind integrating InstructPix2Pix is to convert foreground text elements and their associated attributes into instructional prompts that guide the editing of background images. Subsequently, we fine-tune InstructPix2Pix to transform clean background images into images with text superimposed on them, as depicted in Fig. 4. We capitalize on InstructPix2Pix's remarkable prompt controllability while acknowledging its limitations in text generation quality. As a result, our approach focuses on extracting only the layout information represented by bounding boxes of texts following image editing, while disregarding the textual pixels.
Framed Template RetrieveAdapter

To enhance the diversity of generated layouts, we introduce an additional approach known as the Framed Template RetrieveAdapter. This approach is designed to accommodate users' multimodal inputs within retrieved framed templates. Our in-house UX designer, Paul Josel, has meticulously crafted 56 distinct framed banner templates for retrieval, as showcased in Fig. 5. These templates exhibit various background styles, including light textures, gradients, uniform colors, or combinations thereof. The background layer serves as the canvas for three other types of foreground layers: (1) Ad copy text layers, encompassing headers, body text, and more; (2) Image placeholder layers, represented as masks in common geometric shapes; (3) Composite layers, which may include optional elements like buttons.
In essence, rather than employing the user input image as the banner background, we "frame" it as a foreground image layer. To seamlessly integrate the input image into the banner, we have developed a smart cropping algorithm that identifies salient sub-windows within the input image. These sub-windows typically preserve salient foreground objects, such as human faces, products, logos, and more. When a framed template is retrieved, one of these salient sub-windows is selected based on the size and aspect ratio of the template image layer. Finally, a renderer compiles HTML and CSS scripts to merge all the layers into an HTML file, enabling rendering and manual adjustments.
In summary, our RetrieveAdapter method consists of three main components:
- Retriever: This component retrieves the most suitable framed templates based on predefined metrics, including the number and type of user-provided ad copies, text length matching scores, and more.
- Adaptor: The adaptor customizes user input text and images to fit within each matched framed template.
- Renderer: This component produces each ad banner in HTML/CSS by seamlessly blending the background layer with layers tailored to the user's inputs.
Layout-to-image rendering
The objective of our banner renderer is to follow each of the above layout generators and seamlessly rasterize users’ multimodal inputs alongside our generators’ bounding box predictions, adapting to the specific input modality. This involves the following actions:
- For texts:
- Rendering the input text content in accordance with the user-specified font family, color, and enhancements.
- Calculating the maximum font size based on the predicted text bounding box.
- Aligning the text content as per the specified post-processing argument.
- For images:
- Performing alpha blending with the smart-cropped sub-image, based on the masked image layer.
Our rendering process generates banners in two distinct formats: HTML and PNG. We provide the rendered banner in HTML format to facilitate further layout manipulation. Simultaneously, our renderer captures a screenshot of the HTML banner using a headless Chrome browser. These saved PNG files represent the final output and are ready for embedding into any media or immediate use.
Results



Bottom Line
BannerGen paves the path towards customizable layout design. It inherits the generation quality and controllability of modern generative models, and in turn facilitates efficient and scalable layout generation. We integrated all the modules above into open source, in the purpose of inspiring follow-up works in this direction as well as accelerating implementation iterations.
Acknowledgements
We express gratitudes to Paul Josel for the banner template design, Gang Wu and Matthew Fernandez for the system maintenance, and Rui Meng, Juan Carlos Niebles, and Caiming Xiong for the advice in general.
Explore More
Code: https://github.com/salesforce/BannerGen
Contact: ning.yu@salesforce.com; ran.xu@salesforce.com