 Blog Home
Blog HomeA Multi-Discriminator CycleGAN for Unsupervised Non-Parallel Speech Domain Adaptation
Neutral AI
In the same way that human decisions can be influenced by cognitive biases, decisions made by artificially intelligent systems can be vulnerable to algorithmic biases. Because AI systems depend heavily on the data used to train them, any bias in the data can then bias the decisions that system makes. In order to build a neutral AI that humans can trust, it is imperative to detect and remove such biases.Here, we study the effect of gender biases in automatic speech recognition (ASR) models, propose an approach for removing these biases, and build a gender-neutral ASR model.
Toward Neutral Speech Recognition System
Neural-based acoustic models have shown promising improvements in building automatic speech recognition (ASR) systems. However, when evaluated on out-of-domain data, they tend to perform poorly because of a mismatch between the train and test distribution. Domain mismatch is mainly due to features that are described as ‘non-linguistic’ by the ASR literature:
- Different speaker identity
- Unseen environmental noise
- Large accent variations
- Style: Variation in speed, intonation, pitch range
For this reason, training a robust ASR system is highly dependent on disentangling linguistic features (content that would appear in a transcript) from these ‘non-linguistic’ features (the inter-domain variations between source and target that would not appear in a transcript).
Neural and statistical voice conversion (VC) has been widely used to adapt non-linguistic variations. However, traditional VC methods require parallel data of source and target, which is difficult to obtain in practice. In addition, the requirement of parallel data also prevents these methods from using more abundant unsupervised data. Because there is far more unsupervised data than supervised data, a method for unsupervised domain adaptation is desirable when building a robust ASR system.
A Multi-Discriminator CycleGAN (MD-CycleGAN)
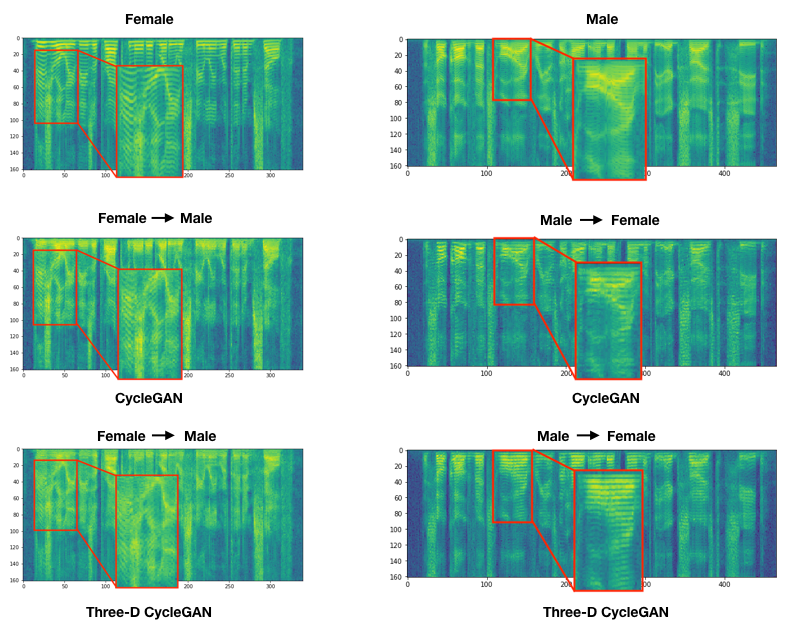
We propose a new generative model based on the CycleGAN for unsupervised non-parallel domain adaptation of speech. A domain adaptation model should match or convert the characteristic features of data samples across different domains. By representing speech domains using spectrogram features, the main difference emerges in the frequency magnitude of the source and target domain. Therefore, it is imperative that a voice conversion model can convert this characteristic variation. Accordingly, a generative model, such as CycleGAN, should correctly model the spectro-temporal variations between different frequency bands across domains during training. This will allow the generator to learn the mapping function which can convert spectrogram from source to target domain. We show that the original CycleGAN model is failing to learn such a mapping function between domains.The generator collapses into learning an identity mapping function, which results in generating a noisy and unnatural-sounding audio. This problem is alleviated by using multiple discriminators. For more details, please see the paper.
Gender-Based Speech Synthesis by MD-CycleGAN
Below, we compare the naturalness of synthesized audio samples, generated by CycleGAN and MD-CycleGAN for male↔female conversions.
Male→Female
| Speaker 1: The emblem depicts the Acropolis all aglow. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 2: Will Robin wear a yellow lily? | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 3: Obviously, the bridal pair has many adjustments to make to their new situation. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 4: Less personal salesmanship. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 5: Poach the apples in this syrup for twelve minutes, drain them, and cool. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 6: The so-called vegetable ivory is the hard endosperm of the egg-sized seed. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 7: This is no spectator-type experience; everyone is to be a participant. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 8: Take care of yourself then. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 9: It was a fairly modern motel with quite a bit of electrical display in front. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 10: It was there that she would have to enact her renunciation, beg forgiveness. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
Female→Male
| Speaker 1: Bricks are an alternative. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 2: Aluminum silverware can often be flimsy. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 3: Production may fall far below expectations. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 4: Elderly people are often excluded. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 5: Let all projects dry slowly for several days. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 6: December and January are nice months to spend in Miami. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 7: If people were more generous, there would be no need for welfare. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 8: Basketball can be an entertaining sport. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 9: A note of awe came into his voice. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
| Speaker 10: My mother was beside herself with curiosity. | ||
| Source | ||
| (CycleGAN) Target 1 | ||
| (MD-CycleGAN) Target 2 | ||
Qualitative Assessment of Synthesized Spectrograms
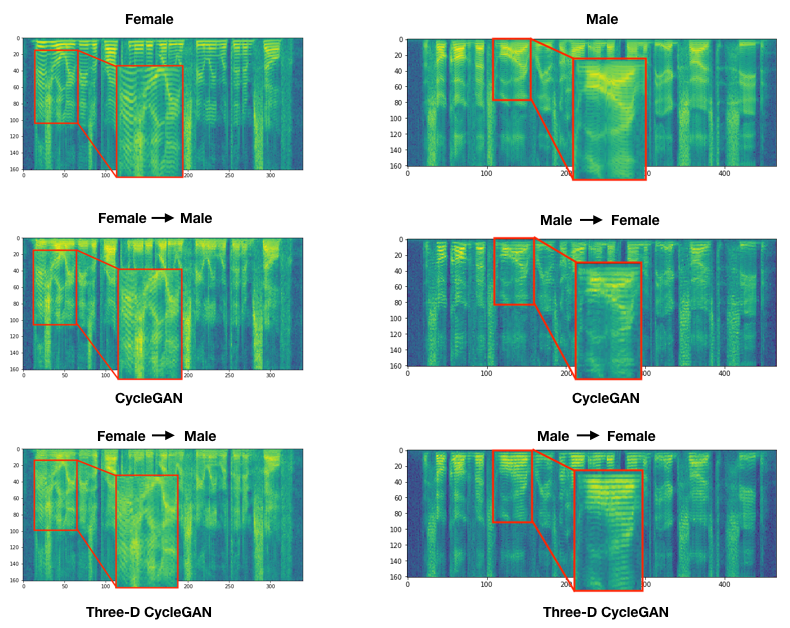
Improving ASR performance using Domain Adaptation
Domain adaptation intends to improve the performance of an ASR model by matching the target and source distributions. In this section we define domains which are differentiated by gender type. To evaluate the performance of MD-CycleGAN on domain adaptation, ASR performance is assessed on the converted domains. Split by gender type, we consider both train→test and test→train domain adaptation. In the former, ASR model is re-trained on the test-adapted train set, while in the latter, a more applicable case, ASR model is fixed and evaluated on a train-adapted test set. Below, we show the results on TIMIT and WSJ datasets. TIMIT dataset contains broadband 16kHz recordings of phonetically-balanced read speech of 6300 utterances (5.4 hours). Male/Female ratio of speakers across train/validation/test sets are approximately 70% to 30%. WSJ contains ~80 hours of standard si284/dev93/eval92 for train/validation/test sets, with equally distributed genders. It is worth mentioning that MD-CycleGAN is only trained on the TIMIT dataset, and when used on the WSJ dataset (Table 5), it generalizes well in adapting male and female domains.
| Train on Male | ||
|---|---|---|
| Test on Female | True | CIBA AGREED TO REMEDY THE OVERSIGHT |
| Female | SEVEN AGREED TO REMEDY THE OVER SITE | |
| Female→Male | CIBA AGREED TO REMEDY THE OVER SITE | |
| True | A LITTLE GOOD NEWS COULD SOFTEN THE MARKET'S RESISTANCE | |
| Female | A LITTLE GOOD NEWS COULD SOUTH IN THE MARKETS RESISTANCE | |
| Female→Male | A LITTLE GOOD NEWS COULD SOFTEN THE MARKET'S RESISTANCE | |
| Train on Female | ||
| Test on Male | True | THEY EXPECT COMPANIES TO GROW OR DISAPPEAR |
| Male | THE DEBUT COMPANIES TO GO ON DISAPPEAR | |
| Male→Female | THEY EXPECT COMPANIES TO GROW OR DISAPPEAR | |
| True | MR POLO ALSO OWNS THE FASHION COMPANY | |
| Male | MR PAYING ALSO LONG THE FASHION COMPANY | |
| Male→Female | MR POLO ALSO OWNS THE FASHION COMPANY | |
Train Domain Adaptation
| Model | Train | Male (PER%) | |
|---|---|---|---|
| Val | Test | ||
| -- | Female | 40.704% | 42.788% |
| CycleGAN | Female→Male | 40.095% | 42.379% |
| Female&→Male | 39.200% | 42.211% | |
| Three-D CycleGAN | Female→Male | 29.838% | 33.463% |
| Female&→Male | 30.009% | 33.273% | |
| -- | Male (baseline) | 20.061% | 22.516% |
| Model | Train | Female (PER%) | |
|---|---|---|---|
| Val | Test | ||
| -- | Male | 35.702% | 30.688% |
| CycleGAN | Male→Female | 32.943% | 30.069% |
| Male&→Female | 31.289% | 29.038% | |
| Three-D CycleGAN | Male→Female | 28.80% | 25.448% |
| Male&→Female | 25.982% | 24.133% | |
| -- | Female (baseline) | 24.51% | 23.215% |
Test Domain Adaptation
| Test (PER) | Train | ||
|---|---|---|---|
| Model | Male | Female | |
| Male (baseline) | -- | 22.516% | 42.788% |
| Male→Female | CycleGAN | -- | 43.427% |
| Three-D CycleGAN | -- | 37.000% | |
| Female (baseline) | -- | 32.085% | 23.215% |
| Female→Male | CycleGAN | 32.606% | -- |
| Three-D CycleGAN | 25.758% | -- | |
| Test (CER/WER) | Train | |
|---|---|---|
| Male | Female | |
| Male (baseline) | 3.19 / 8.16% | 14.31 / 27.66% |
| Male→Female | -- | 6.82 / 15.68% |
| Female (baseline) | 7.57 / 16.38% | 2.80 / 6.71% |
| Female→Male | 5.93 / 13.18% | -- |
Conclusion
We have introduced a new, cyclic generative adversarial network that trains with a multi-discriminator objective -- (MD-CycleGAN) -- for unsupervised non-parallel speech domain adaptation. Based on the frequency variation of spectrogram between domains, multiple discriminators enabled MD-CycleGAN to learn an appropriate mapping function that catches the frequency variations between domains. The performance of MD-CycleGAN was measured by ASR performance on source↔target adaptation, which are differentiated by gender. Evaluations showed that MD-CycleGAN can improve ASR performance on such unseen domains. As future extension, MD-CycleGAN will be evaluated for removing different biases via adaptation, e.g. TIMIT↔WSJ as dataset adaptation, and American↔Indian as accent adaptation.
Citation credit
Ehsan Hosseini-Asl, Yingbo Zhou, Caiming Xiong, and Richard Socher. 2018.
A Multi-Discriminator CycleGAN for Unsupervised Non-Parallel Speech Domain Adaptation