 Blog Home
Blog HomeA Domain Specific Language for Automated RNN Architecture Search
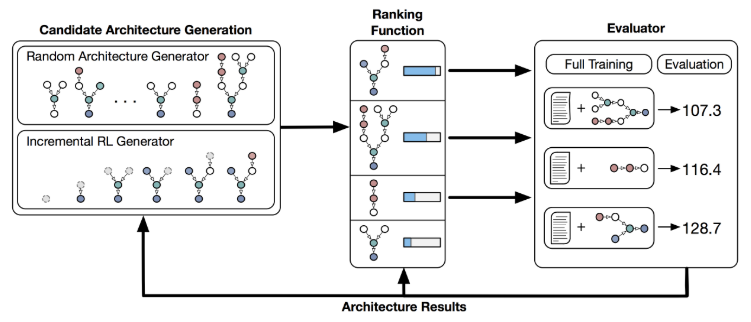
When humans generate novel neural architectures, they go through a surprisingly large amount of trial and error. This holds true almost regardless of how much experience in deep learning that person might have! In an optimal world, the neural networks themselves would explore potential architectures and improve themselves over time.
Without human intuition and insights however, automated architecture search is fraught with peril. Even at the blinding speed computers operate, our machines aren't fast enough to brute force search randomly through the billions of different potential architectures. While we can't scale human intuition, we can approximate it with through a ranking function. This ranking function is a neural network that learns from past experiences regarding which types of neural networks look promising and which are likely to be useless.
We propose a system that learns to generate candidate architectures in a domain specific language (DSL), ranks these candidate architectures based upon previous experience (our ranking function), and then compiles and evaluates a subset of these architectures which are then used to improve the overall system.
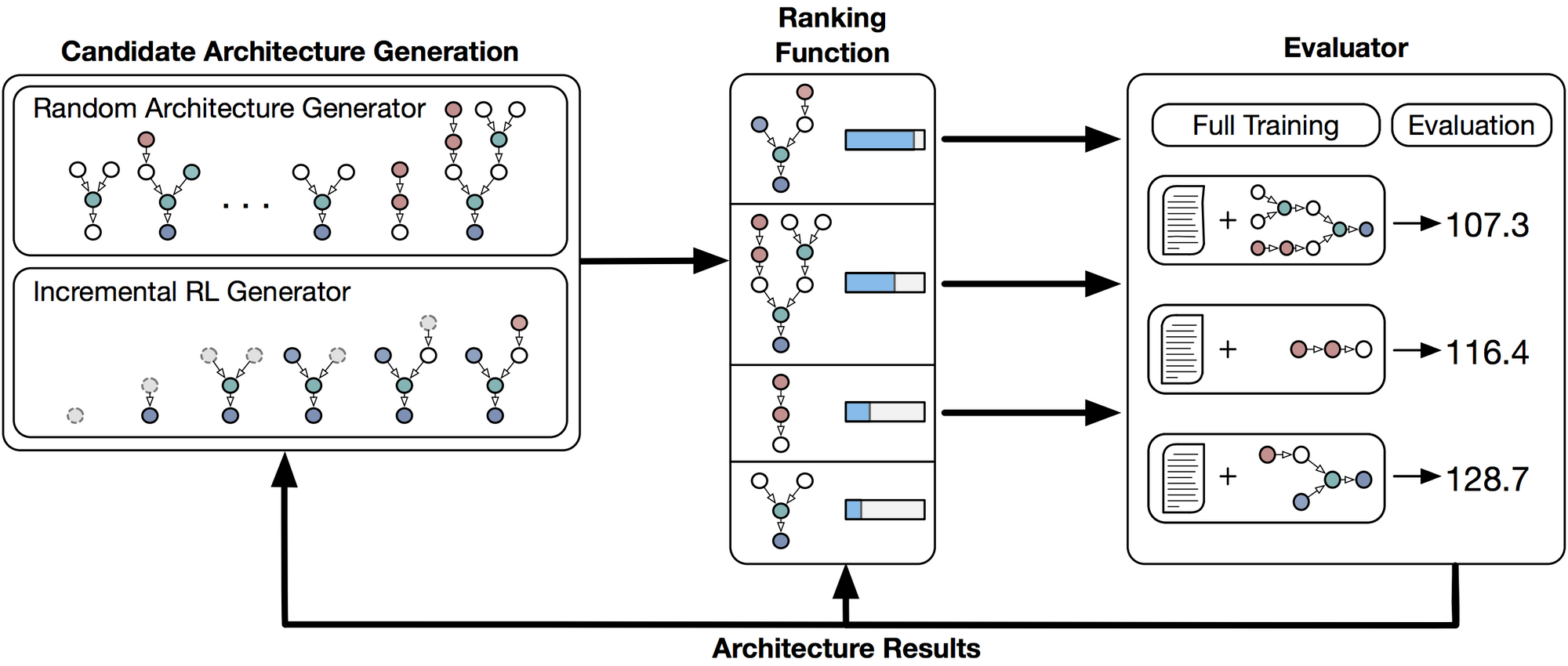
The domain specific language (DSL) defines the search space of potential architectures and allows the computer to compile candidate architectures into executable code. The DSL has two sets: a basic subset and an extended subset. The basic DSL can define the majority of standard RNN architectures (RNN, GRU, LSTM, QRNN, ...), suggesting it has can cover much of the existing RNN search space. The extended DSL allows us to incorporate unusual operators like geometric curves, division, or positional encoding. These components are non-standard and haven't been as well explored by humans yet, either due to time or their pre-existing biases as to what does or doesn't work.
With the DSL, a standard tanh-RNN may be represented as: tanh(Add(MM(x), MM(h))).
For more complex RNNs, the definition can become a quite a bit more lengthy!
The ranking function: To allow for the architecture search to improve in an automated manner, we design a ranking function that estimates a given candidate architecture's performance. Given an architecture-performance pair, the ranking function constructs a recursive neural network that reflects the nodes in a candidate RNN architecture one-to-one. Sources nodes are represented by a learned vector and operators are represented by a learned function. The final vector output then passes through a linear activation and attempts to minimize the difference between the predicted and real performance.
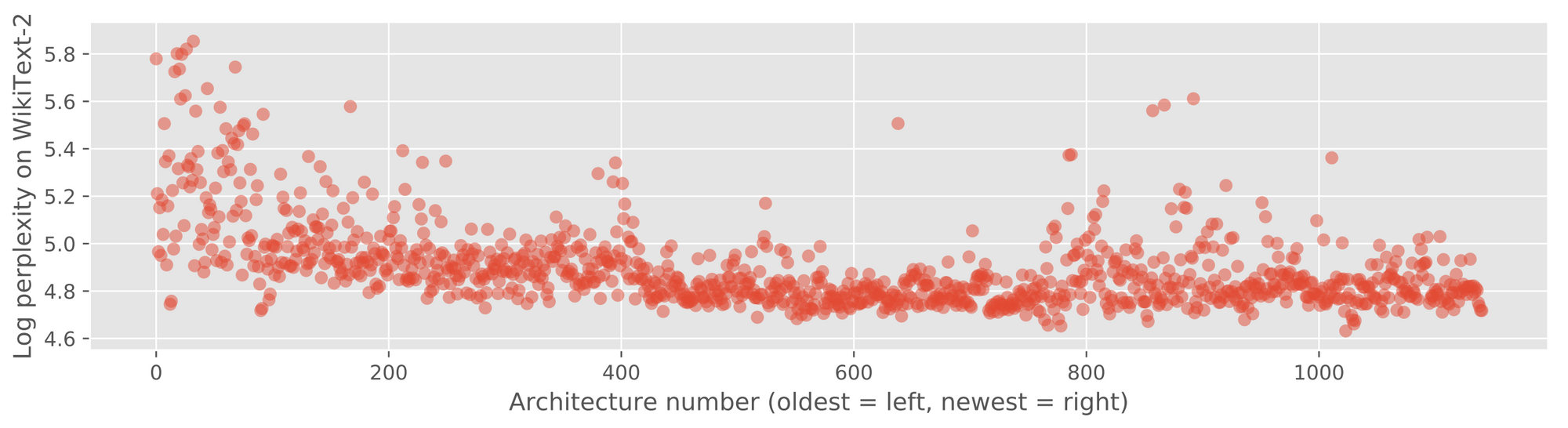
As we can see in the figure above, over time the ranking function becomes more and more accurate it predicting a given candidate's performance, meaning it only selects promising architectures to evaluate. The confusion around architecture number 800 is that we allowed the generator to design more complex RNN architectures, specifically those which use both a long and short term memory component.
What does training an architecture search look like? The generator begins pre-trained with human knowledge and focused only on the core DSL but, after various experimental runs and evaluations, begins using the full extended DSL.
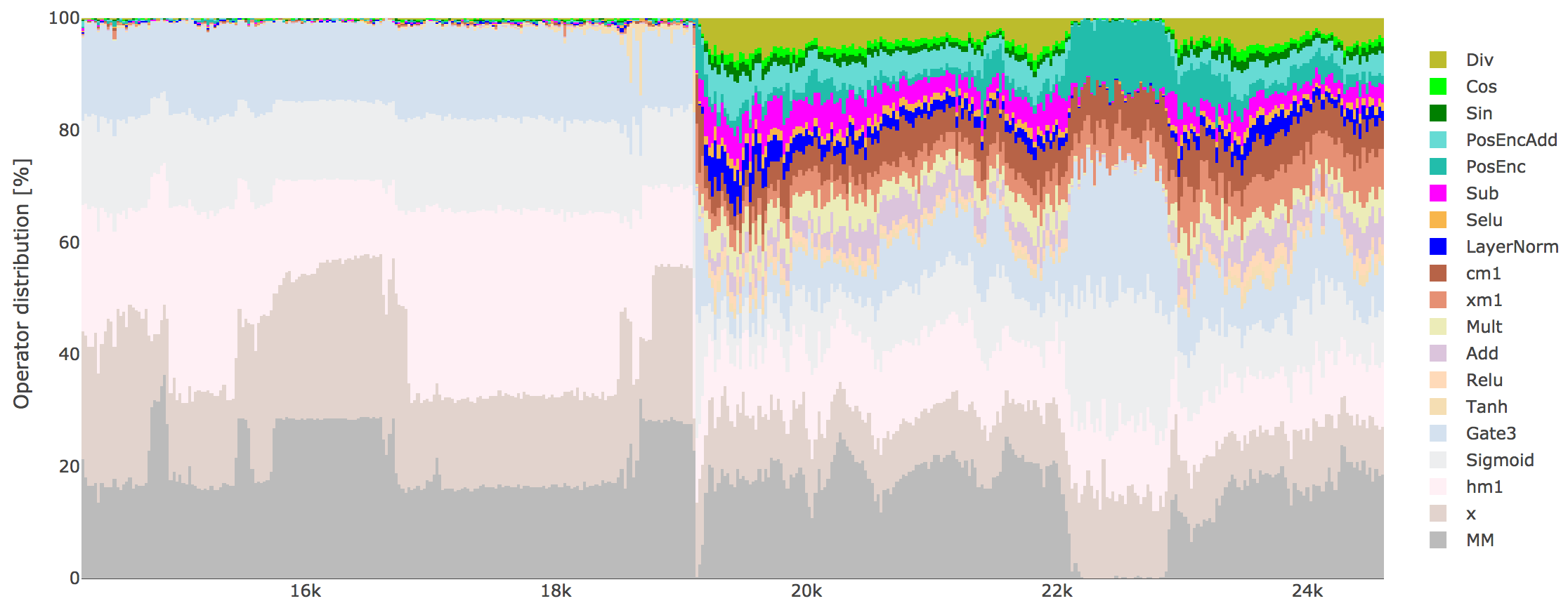
This suggests our system is able to learn to use diverse and complicated components within RNN architectures. On inspecting the architectures generated, many broke with human intuitions regarding what RNN architectures should or shouldn't work. This suggests that humans may be handicapping their creativity by relying too strongly on ungrounded intuition rather than wide scale experimental results!
How do the architecture process information differently? Given the differences in generated architectures and their quite varied usage of components, we explored how the models reacted to the same input data over time. Each of the activations differs substantially from those of the other architectures even though they are parsing the same input.
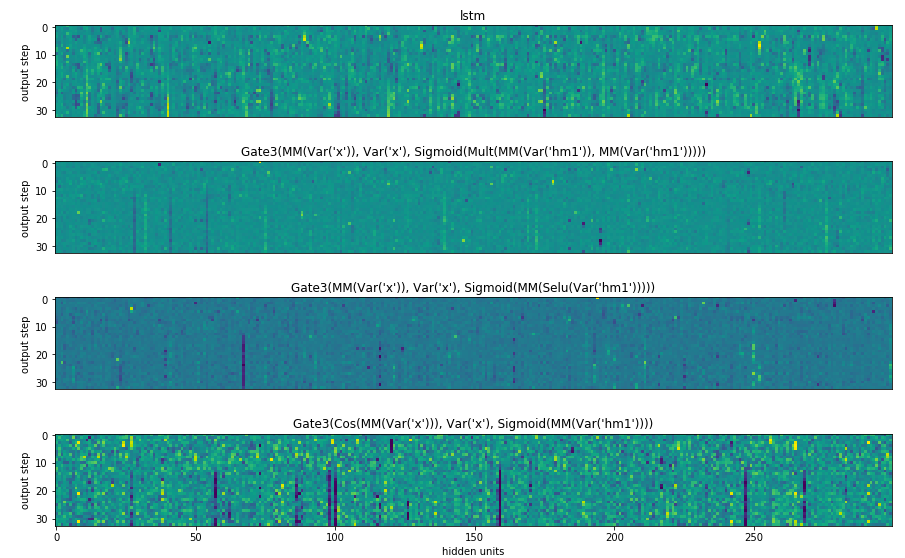
As the input features are likely to not only be captured in different ways but also stored and processed differently, this suggests that ensembles of these highly heterogeneous architectures may be effective. Rather than selecting just the best found architecture, it may become promising to keep an entire zoo of them, selecting and mixing between their results!
For more details and in depth discussion, refer to:
Stephen Merity, Martin Schrimpf, James Bradbury, Richard Socher. 2017.
A Flexible Approach to Automated RNN Architecture Generation